Research Computing Teams Link Roundup, 8 Oct 2021
Let me tell you about a mini-fiasco this week that was entirely my own doing.
In our team, we routinely hire students for semester-long co-op positions. It happens three times a year - I think we’ve taken part 12 times over the past five years. It generally works out pretty well, for us and the co-op student.
The process is pretty uneventful generally. Our tireless administrative staff, without whom the place would fall apart, lets me know that it’s time again; we post our usual job ad; we interview some students and submit a ranked list. We’ve lately been pretty good at having projects ready for them on day one.
We had a couple more potential student supervisors with projects this semester, which is good. In the past year we’ve been upping our game at hiring full time staff, and part of that is better job ads; so we wrote a much better job ad for the co-op position this year and that resulted in fewer candidates but who were overall much better matches for the team. Win-win!
And, my fellow managers and leads, I’m ashamed to tell you that that’s where it all fell apart.
Because we had fewer, better matches, and more potential supervisors, triaging the resumes - which was my job - was harder and I didn’t do it in time. Our admin, after an earlier prompt, let me know the last possible day to interview was the next day. I dumped a pile of resumes at end of day on our volunteer supervisors, who had hours to read them after hours and choose preferred candidates. Our interviews were ill-prepared, and we didn’t have as much communication with the candidates before and afterwards as we would have liked. A bunch of meetings had to be cancelled and rescheduled because there was only one window to interview the students. The remainder of the week was all messed up.
The outcome was ok, but not great - we found some really good candidates, but we shredded credibility with them because we were visibly unprepared. One has already been poached by someone in another team in our org, and if we had coordinated earlier we could have known about the shared interest. And it completely screwed up our week and stressed out volunteer supervisors - who don’t have to do this next time around.
So why are dates of something that happens on a schedule three times a year and has done so for the past five years coming as a surprise to me and the co-op interviewers? Why was I being a bottleneck for triaging resumes - why not have the supervisors do it? (Because that’s how I did it four years ago when I was the only supervisor). Why are we making our admin, who has other things to do, patiently shepherd us through an utterly routine occurrence that we should have down pat?
More fundamentally - the co-op student hiring process is both something we do all the time, and is the fastest feedback loop we have for improving our hiring process. Why, after 12 iterations, did I not have a runbook for doing this, with a systematic way of learning and improving both the co-op process and our interviewing process for hiring in general?
The answer of course is that it was going well enough, there were no flashing red lights, and there was always something else demanding attention.
But building a process for this at any time over the past four years would have been a very valuable activity for me. It would have helped me delegate tasks that I oughtn’t have been doing, improved our team’s interviewing and hiring skills, helped us find better matches for co-op students, and improved our co-ops experience throughout the process (which helps with referrals and full-time hires).
The situation is utterly goofy. Had I been talking to a peer and they told me they had this issue, I would have encouraged them to address it. And, in my own job - I just didn’t. Even when we know the right thing to do as managers to improve our processes and help our team, it’s really easy to be caught up in other priorities - “now’s just not the right time”.
Anyway: a learning opportunity. Next time through there will be a runbook, and it’ll go better. But this shouldn’t have happened in the first place.
Do you have processes in your current job that badly need updating - or have you improved one lately? How’s it going? Email me and let me know.
On to the roundup!
Managing Teams
LifeLabs Sample Interviewing Playbook - Life Labs Learning
Life Labs Learning, a management/leadership training company, has a Google Doc template interviewing playbook for team members that can be a starting point for a given team and role. It’s short but gives good guidance on creating the process for the manager, and how to conduct the interview for novice interviewers.
No-bullshit tenets for faster decision-making - Jade Rubick
Breaking Through The Guard Rails - Roy Rapoport
These are about managing and decision-making generally, but they apply very much to hiring.
The key idea of both is that, while people often list the things they value in their team - “independence”, “delivers results”, “attention to detail” - listing them as standalone values is meaningless. Nobody thinks independence, delivering results, or attention to detail are bad things, so saying you value them communicates nothing and can’t inform decisions.
But these values have tradeoffs. They’re one end of a spectrum that has another end. For these to be principled choices rather than just feel-good assertions, you have to explicitly own that if you’re hiring for “independence” you’re also hiring for “chafes at detailed guidance”.
Rubick recommends specific “We value this, over this” structures to clarify team decision making, regardless of the context:
A good tenet should have a perfectly valid opposite tenet that would make sense in a different context.
He gives some examples:
“We build things in a cost-conscious way, even if it takes longer to build”. Vs. “We are willing to throw money at problems if it speeds us up”
or
“We value clarity over moving quickly” Vs. “We value taking action over analysis”.
He doesn’t suggest these should be top-down, but should emerge from a forming team.
Rapoport’s article is more about personal failure modes. He describes an analogy where different people might prefer one side or another of a lane, along multiple dimensions:
Freedom vs guidance
Strategy vs tactics
Relationship orientation vs execution orientation
Changephilic vs changephobic
Caution vs speed
and knowing where you personally sit on those spectra mean you can be more prepared for your own personal failure modes. He leans heavily on the “freedom” side of freedom vs guidance as a manager, so he’s not worried about becoming a micromanager - he doesn’t prepare for that failure mode - but he’s learned to keep an eye on himself to make sure he’s providing enough guidance for team members who need it in a particular situation.
Again, note that the lane edges are not defined as “good vs bad” - freedom is good, but so is guidance. Caution and speed are both good. But there are trade-offs.
Are your hiring filters working? - Jonathan Hall
Once you are clear on the nature of candidates you’re trying to hire, it’s a lot easier to evaluate hiring processes - and once you have a documented repeatable process, you can evaluate and update iteratively.
As Hall points out, everything we do in the process - from the job ad to the application form questions and onward - is a hiring filter. But is it a good filter? Does it enrich for the candidates we actually want by filtering out the candidates that wouldn’t be a good match and preserving the candidates that would be a good match? Have you checked?
Product Management and Working with Research Communities
FILE NOT FOUND: A generation that grew up with Google is forcing professors to rethink their lesson plans - Monica Chin, The Verge
This article has been going around, and I’m curious to hear how many groups that do training have seen this already - students who grew up with search capabilities and (implicitly) object stores or flat namespaces are going into computational science courses with no comprehension of directory hierarchies, or that programs need to be told where to find files.
I think this is an interesting challenge when designing training for our existing tools, which very much rely on file system hierarchies. Yet I can’t agree with the premise of some of the scientists that Chin interviews, that directory structures are “computer fundamentals” that need to be learned, as opposed to a particular way of organizing metadata about files that many of the tools we’re still using require.
Linux block file systems (say) support directories, but files are just inodes and blocks, with human-friendly grouping and naming implemented by having some files be lists of other files and directories along with human-readable names. Object stores make this more explicit - “directory structures” are just syntactic sugar.
We know that a strict hierarchy can be awkward in practice for organizing files - sometimes files belong in multiple directory trees - so from very early on with POSIX file systems we had to give the directory structure mental model an escape hatch, with symlinks. Even when happily using directory structures, search with find and grep (and git grep and cousins) are pretty widely used tools. And heaven help you if you’ve realized you organized files into directories along the wrong dimensions, because “refactoring” a directory structure is a labour-intensive and error-prone process. An awful lot of data management systems are moving towards something that looks more like search + flat-ish name spaces that students are used to.
Is this mental-model mismatch something your group has seen in training sessions? How has your team handled it? Does anyone still organize their email into folders? Reply and let me know.
Teaching by filling in knowledge gaps - Julia Evans
Chin’s article above is really valuable because it connects a problem people are having (understanding directory structures and why they even exist) to their existing knowledge and experience (familiarity with accessing data and files primarily via search and flat namespaces). There’s a knowledge and experience gap that needs to be filled.
As Evans points out in this article, making progress with basic knowledge and then filling in the gaps as needed is how most of us learn computing (or physics, or..). So paying attention to what they do know is as important as what they don’t, because then you can connect to that knowledge:
One mistake I see people make a lot when they notice someone has a knowledge gap is:
-notice that someone is missing a fundamental concept X (like knowing how binary works or something)
-assume “wow, you don’t know how binary works, you must not know ANYTHING”
-give an explanation that assumes the person basically doesn’t know how to program at all
-waste a bunch of their time explaining things they already know
Evans says that she herself focusses on small bitesized things that uncover one core concept - often what’s behind an abstraction - with realistic use cases of how someone might have run up against this, and so what they likely already have some familiarity with.
I’m not sure if that approach suggests any particular way to approach teaching directory structures. Show how indexes like locatedb work, how a search for a filename goes - especially for a case with a non-unique filename, and then talk about directory hierarchies?
Cool Research Computing Projects
Nobel Prize for Climate Modeling - Steve Easterbrook
This year’s Nobel Prize in Physics went, in part, to the kind of work that RCT teams support - climate modelling. This is a section from Easterbrook’s upcoming book describing Syukuro Manabe’s early work on general circulation modelling.
Research Software Development
Profilerpedia: A map of the Software Profiling Ecosystem - Mark Hansen
Hansen presents a tabulation of 130+ (!!) different software performance profilers which collectively output in 109 (!!) different file formats, and 90 different tools for visualization of profiles. There are also ~100 different converters available.
Hansen is hoping to (a) let people wrestling with profilers or visualizers that there might be other options out there for them - at the very least other visualization tools they should know about - and hoping to help kickstart development of more profile-format converters.
How Big Tech Runs Tech Projects and the Curious Absence of Scrum - Gergely Orosz
I’m a big fan of the analogy between research software development and tech companies (including startups). In both cases, there’s an element of something new to what’s being built, and R&D - figuring out the problem while building an initial solution.
Another parallel is that you can’t necessarily start with two-week stories. An MVP for the new groundwater simulation code is going to take a little while, and there’s going to be a lot of very waterfall-y planning at the start.
Orosz has consulted and worked at several companies, and ran a survey of 100 companies. He sees big tech, and venture-funded scaleups and startups often having a Plan → Iteratively Build → Ship methodology rather than a purely agile approach like Scrum or Kanban. (Also, everyone hates Jira, and everyone uses it anyway).
There’s a lot more interesting material in his distillation of his survey - eventually as tech firms get large they adopt product rather than project managers, the importance of team autonomy in choosing how they work to their morale (even though they tend to converge on a common model per sector!) the varying division of responsibilities of managers. If you’re interested in how teams build stuff at tech companies, it’s worth a read.
Research Data Management and Analysis
Why you should use Parquet files with Pandas - Tirthajyoti Sarka
Regular readers will know that this newsletter is adamantly anti-CSV. Using text files to store structured data is a problem from the point of view of documentation, integrity/enforcing constraints, performance, space usage, and usability.
The usual recommendation is databases, including embedded DBs like SQLite or DuckDB. But! If you really want to maintain the a-table-in-a-file structure, especially where you’d be typically operating mostly on subsets of columns at a time, Sarka would like to introduce you to Parquet.
Parquet files are binary self-describing columnar files that have been used for years in the Big Data/Hadoop area, and are easily accessed in python (with pyarrow) or R (with arrow). The data is stored by column, not by row, which makes reading subsets of columns fast, and greatly improves compression. In addition, several columnar databases (including DuckDB) will operate on parquet files out-of-the-box.
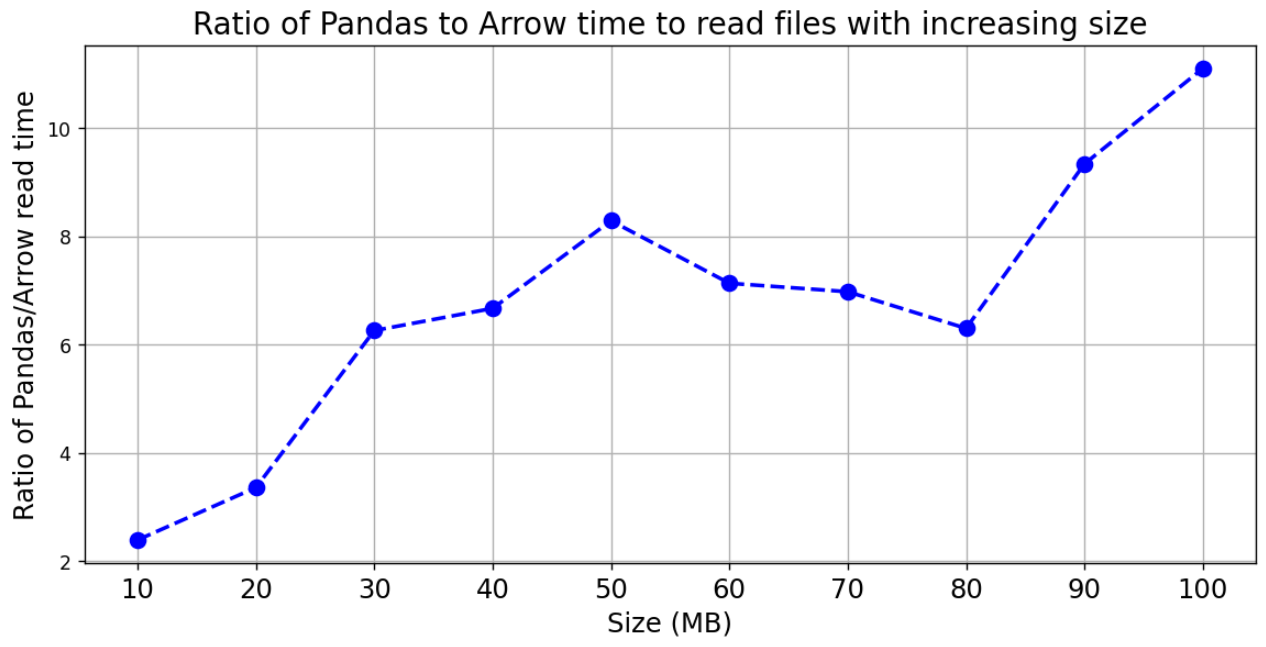
Even if you’re just going to read in the entire file, Sarka shows how reading it into a Pandas data frame is 2-10x bigger for 10-100MB files:
Research Computing Systems
Helping Apache Servers stay safe from zero-day path traversal attacks (CVE-2021-41773) - Michael Tremante, Cloudflare Blog
Heads up that Apache 2.4.49 released mid-Sept is susceptible to a remote code execution attack that’s being seen in the wild, if you’re using that you should downgrade to earlier versions or upgrade quickly to 2.4.51.
Sharing the wealth of HPC-driven apps with flexible as-a-service models - Dell, HPC Wire
This is a sponsored vendor article - so, you know - but it highlights UMich, University of Florida’s, and SDSC’s successful service-driven HPC models: Michigan’s Open OnDemand and ITS Cloud Services program, U Florida’s similar Open OnDemand program, and SDSC’s cloud based version. Building these service-based approaches to compute provisioning is not just doable but done, and there are starting to be enough use cases to learn from.
Path Building vs Path Verifying: The Chain of Pain - Ryan Sleevi
Just as last week’s Facebook outage taught a lot of people about BGP, certificate issues are the way most people learn about certificate chains and verification. This year’s Let’s Encrypt old root certificate expiry went better than Facebook’s BGP issues, but there were still a lot of problems. Here’s an article from last year where Sleevi describes a similar issue, what went wrong with early OpenSSL releases, how certificate graphs should be handled, and what happens when corners are cut.
Emerging Technologies and Practices
The ultimate guide to GitHub Actions authentication - Michael Heap
GitHub Actions are increasingly being used by research computing teams for CI, CD, bundling releases, and other things (have a particularly interesting use case? Let me know!).
Here Heap walks us through the different authentication and authorization methods, and their pros and cons. His proposed ranking is:
- GITHUB_TOKEN - the default, but you probably should know how it works and downscope permissions, and understand its limitations
- GitHub Apps - Has some additional features like lets you perform actions as a user, abd actions can trigger new workflow runs
- Personal Access Token (PAT) - very flexible, but has long lived tokens and probably means the use of shared accounts.
Calls for Submissions
Open Call for New User Project Proposals, Advanced Quantum Testbed, Letters of Intent due 5 Nov
From the call:
The Advanced Quantum Testbed at Lawrence Berkeley National Laboratory (Berkeley Lab) announces the second open call since the inauguration of its user program for new user project proposals. In collaboration with AQT’s expert team, testbed users have full access to the hardware and software, participate in its evolution, and advance the science enabled by quantum computing.
The 22nd International Conference on Parallel and Distributed Computing, Applications and Technologies (PDCAT) - 17-19 Dec, Guangzhu China, papers due 31 Oct
Topics of interest include
- Networking and Architectures
- Software Systems and Technologies
- Algorithms and Applications
- Security and Privacy
Events: Conferences, Training
The 34th International Workshop on Languages and Compilers for Parallel Computing - 13-14 Oct, Virtual, $50 Registration
Talks include progress on runtime and programming languages for parallel computing, accelerated architectures (including OpenMP for FPGAs), multi-target compilation including ARM and RISC-V, and more.
International RSE Day, 14 Oct, various
Happy RSE day, to all who celebrate!
The international council of RSE associations has apparently decided to celebrate Interational Research Software Engineer day the second Thursday of October each year. This page lists events in the Netherlands, Nordic countries, the US, Germany, and Australia.
19th Annual Workshop on Charm++ and its Applications - 18-19 Oct, Virtual
Free virtual workshop on all things Charm++, NAMD, ChaNGa, and OpenAtom.
ARDC Skills Impact and Strategy - 26 Oct - Free
ARDC Carpentry Connect Australia, 2 Nov - Free
Two sessions hosted by the Australian Research Data Commons for those interested in training. The first is a set of sessions on measuring training outcomes (notoriously difficult to do well!). The second covers hosting Carpentries events, for those in the Carpentries community or considering joining.
18th Annual IFIP International Conference on Network and Parallel Computing (IFIP NPC) - 3-5 Nov, Paris, €50 virtual attendees, €450 on-site
Everything from data centre networks and NVM storage systems to cache management for SSDs.
Random
As we get closer to hallowe’en and the terrors that holds - the case for proportional fonts for programming. As if the thought isn’t horrifying enough, the author says that using proportional fonts meant switching from spaces to tabs. Truly, it is a season of damned souls.
Semantic code search for C/C++ code bases - weggli.
Updates to GitHub Releases, including the option of autogenerating a first draft of release notes.
AWS Batch do’s and don’ts, including cutting costs, debugging, making sure your images & containers aren’t a bottleneck, and when to use various tools.
Cindy Sridharan’s delayed best of 2020 tech talks, including on some RCT-relevant topics like monitoring and change data capture.
Web apps in Pascal, for some reason.
Fit 6000 tiny bit-serial cores onto a single FPGA, for some reason.
A git implementation in awk, for some reason.
Interesting review of a new terminal emulator, warp, which doesn’t seem like it’s for me but it’s fun to see some quite different UI and design choices made around what’s become a pretty staid space.
Post-quantum cryptography is already available for curl.
Another small/medium-sized academic/public sector HPC procurement goes to Azure - this time University of Bath, after a pilot project last summer.
The Insane Innovation of TI Calculator Hobbyists - what can be done with a 10MHz revamped 8080 CPU and 32K RAM.
A searchable database of (so far) 1,818 public incident reports/statements.
That’s it…
And that’s it for another week. Let me know what you thought, or if you have anything you’d like to share about the newsletter or management. Just email me or reply to this newsletter if you get it in your inbox.
Have a great weekend, and good luck in the coming week with your research computing team,
Jonathan
About This Newsletter
Research computing - the intertwined streams of software development, systems, data management and analysis - is much more than technology. It’s teams, it’s communities, it’s product management - it’s people. It’s also one of the most important ways we can be supporting science, scholarship, and R&D today.
So research computing teams are too important to research to be managed poorly. But no one teaches us how to be effective managers and leaders in academia. We have an advantage, though - working in research collaborations have taught us the advanced management skills, but not the basics.
This newsletter focusses on providing new and experienced research computing and data managers the tools they need to be good managers without the stress, and to help their teams achieve great results and grow their careers.
Jobs Leading Research Computing Teams
This week’s new-listing highlights are below; the full listing of 151 jobs is, as ever, available on the job board.
Digital/Senior Digital Product Manager (Data Science) - Abcam, Cambridge UK
Abcam is committed to scaling and using data science to help us serve life scientists to achieve their mission, faster. The Digital/Senior Digital Product Manager (Data Science) is responsible for the development and delivery of our data science digital product landscape, ensuring product quality, value and alignment with our overall product vision & strategy.
Manager, Service Support & Outreach, IS&T Scientific Computing - Boston University, Boston MA USA
The Manager of Research Computing Service Support and Outreach is responsible for managing the team that delivers technical support, training, and assistance in the use of Research Computing services in an advanced computing environment. This position manages current and identifies new centrally funded and researcher Buy-in service models that utilize local, regional, and national Research Computing resources. The Manager oversees accounts administration, resource requests, show-back reporting, and coordinates the delivery of Research Computing focused training, documentation, communications, and outreach for the University Research community. This position and its reports facilitate with researchers in understanding their Research Computing requirements and identifying existing services and contacts both within and outside of the University to fulfill them. The Manager engages with peers to share knowledge and identify potential support and research collaborations.
Kubernetes Infrastrructure Architect - Lawrence Livermore National Laboratory, Livermore CA USA
We have an opening for a Kubernetes Infrastructure Architect to provide technical computer support for systems in a heterogeneous enterprise environment to solve a variety of moderately complex technical problems in a timely manner. This position is in the Information Technology Operations (ITO) Division supporting Global Security Programs within the Computing Directorate.
IT Manager - McMaster University, Hamilton ON CA
Located in the Faculty of Health Science, department of Health Research Methods, Evidence, and Impact (HEI), The Canadian Longitudinal Study on Aging (CLSA) is a large, national study that will follow 50,000 Canadians between the ages of 45 and 85 for a period of at least 20 years. The CLSA is the most comprehensive research platform of its kind, not only in Canada but also around the world. The CLSA is a project funded by CIHR and Innovation Canada, you can read more about us here. Working as part of a two IT Manager team, this role will report to the CLSA Scientific Operations Manager and work with the National Managing Director and the Executive Committee at the National Coordinating Centre at McMaster University in Hamilton.
They will provide operational leadership for all aspects of IT-related infrastructure in the CLSA such as hardware management. They will also collaborate with the CLSA System and Software Architecture team to ensure all IT operations run effectively.
Head Engineer - University of Oslo, Oslo NO
A full time, permanent engineering position (SKO1087 Head engineer/lab engineer) is available in the Research Center for Lifespan Changes in Brain and Cognition (LCBC) in the Department of Psychology. The position is suited for a person with strong programming competence and interest in signal and image processing. Imaging of the human brain by MRI and PET is central to LCBC research. Main tools used for analyses are FreeSurfer (http://surfer.nmr.mgh.harvard.edu/) and FSL (http://fsl.fmrib.ox.ac.uk/fsl/fslwiki/) in addition to custom made procedures, and the center cooperates with the developers of these programs. Custom-made tools are run in Python, Matlab or R, and the lab environment is mainly Linux.
Associate Director, Research Systems - Queen’s University, Kingston ON CA
The Associate Director takes a leadership role in analyzing, interpreting and evaluating business needs, and recommends strategies to enhance and sustain research services at Queen’s. The Associate Director works collaboratively with Portfolio managers, as well as with other units supporting research services at Queen’s, e.g., Centre of Advanced Computing, Research Accounting, affiliated hospitals, Queen’s Libraries and ITS, to lead implementation, outreach and training activities related to the sustainment and evolution of resources, procedures and practices required to maintain progressive, effective and efficient digital research services solutions.
Foundation Scientific Software Engineers - Met Office, Various UK
Contribute to the design, development, maintenance, and optimisation of the core underpinning systems of the Met Office Weather and Climate observation and modelling capability, enhancing technical capability in support of science advances and/or improving performance on available IT infrastructure. Liaise with system users and developers in order to understand their scientific and software requirements, to provide technical guidance and advice; with code developments and/or to ensure developments will be suitable for implementation. Share knowledge and expertise with colleagues in order to enhance both team and inter team effectiveness, including acting as a key interface with science/research colleagues.
Manager, Data & Analytics - University of Toronto, Toronto ON CA
The Manager will lead and coordinate data analysis, investigations, and assessment projects that enable stakeholders at various levels to make data driven decisions. Through strong relationships with partners and by working collaboratively with functional teams across the Enrolment Services, the Institutional Research and Data Governance (IRDG) Office, the Office of Planning and Budget, and across the institution, this position will have a major impact on the strategic information that is provided to senior leadership, enhancing the effectiveness of decision making. The incumbent will possess the knowledge and expertise to effectively navigate the University’s internal data and operational systems in addition to identifying and understanding relevant comparative data sources.
Research Software Scientist - UK Research and Innovation - Science and Technology Facilities Council, Didcot or remote UK
We have an exciting opportunity for mutliple software developers/software scientists to join our team in the Research Software Engineering (RSE) Team within the ISIS Scientific Software Group (SSG). Together, we will be developing a number of software packages in partnership with ISIS scientists and users at the cutting-edge of neutronic data analysis! This group resides within the ISIS Computing Division. To be successful at the higher band [Scientist level] candidates should demonstrate significant experience from contributing to, and often being responsible for, the technical success of a project. Additional duties will also include analysing priorities, guiding the design of software solutions to satisfy scientific requirements, and owning the development of the project.
Senior Research Software Developer - University College London, London UK
The Senior Research Software Developer will take on a leadership role within the group, either technically or managerially, helping to guide the vision for this strategically important area for UCL. You may lead the technical design for complex projects, manage a portfolio of research programming projects, and/or mentor and supervise other group members.