RCT #188 -Immediate next steps for managers worried cuts are coming
Plus: Influencing people; Who’s using LLMs (hint: our users); USRE’25 CFP; Source Available Licenses; Many-Analyst Papers and what they say for our work;...
RCT #187 - Challenging times ahead
Plus: Northwestern University; Massively multiplayer retrospectives; Strategic frameworks framework; How biotechs use software and data to make drugs;...
RCT #186 - Northwestern's experience with success stories.
Plus: Standups; Lockwood on life in industry; Best forking practices; Energy debugging; Genomic data cybersecurity and privacy from NIST; and Slinky for...
RCT #185 - Research Judgement Must Direct Research Resources. Plus: Good software engineer teammembers; Free tier as a business model; STRUDEL and UX; Python 3.13; Writing code for humans; Next level HPC support; Rackspace and OpenStack
Hi, all! Sorry for the pause in newsletter issues; I’m trying to figure out how to better work the newsletter writing into my weeks. You may see shorter...
RCT #184 - The Job Market for Our Community. Plus: Actual managment; ChemOS; Google's View of Software Quality; SciCode codeing benchmarks; Leonhard Med TRE; Blender for scientific Viz; the Anaconda mess
Hi, everyone: Happy September! For those of you, like me, in the Northern Hemisphere, I hope you enjoyed your summer and that the academic year is off to a...
From the RCT Archives: #142 - Other Teams Aren't the Competition
Hi, everyone! This is the last of my over-the-summer “From the Archives” issues - this one from Oct 2022. We’ll get started with regular posting in the next...

From the RCT Archives: #123 - Research Support Teams are Vendors, Too
Hi, everyone! Over the summer I'll mostly be sending out issues from the archives, like below, from May 2022. The job board highlights, though, at the end,...
RCT #183 - We Need To Talk About AI. Plus: Upfront technical requirements are possible; (Too much) Manual work is a bug; Technical governance and leadership; Define your audience better than 'non-experts'; Microvms and Isolation
I think I’ve served you poorly by not writing more about AI. As many of you know, my current day job is with a company now best known as an AI...
RCT #182 - Scientific judgement is part of our job. Plus: Parking lots; Stop hiding in the comfort of your expertise; No wrong doors; Sales is research; Mentoring plans mandatory for NIH funding; NIHR RSS funding; Communities sustain software; Seqera containers
In follow up conversations from our series on the research impact flywheel, the issue that keeps coming up for people is discomfort with making choices about...
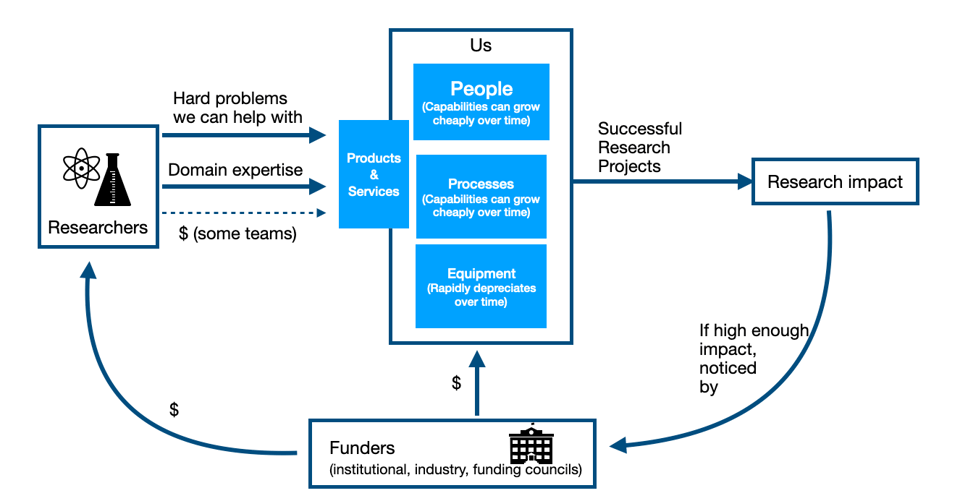
RCT #181 - Positioning, Marketing, and Other Bad Words. Plus: Onboarding instead of sink-or-swim; Making your next week earlier with an hour of planning; Visually communicating software design; HPC containers; and HPC desktops
I want to close our discussion that started way back in #176 about this flywheel we want to keep going, by going back to the start. In #176, I talked about...
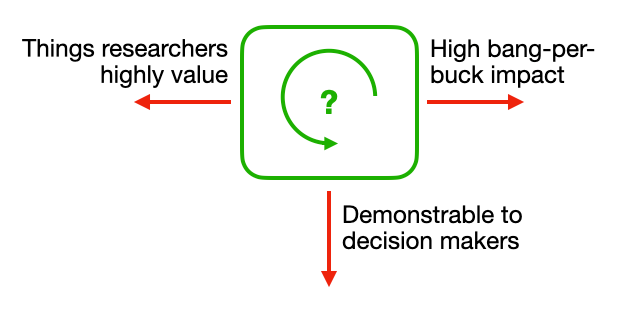
RCT #180 - Fundability and Staffability. Plus: Successes and Struggles of Horizon 2020; Research Management as a profession; RSE Competencies; NASA Transform to Open Science; Infrastructure for Research on Teaching; CaRCC Engagement Guide for Smaller Institutions
For the last four issues we’ve been walking our way around the flywheel of research computing teams, looking at the external forces tugging on our teams —...
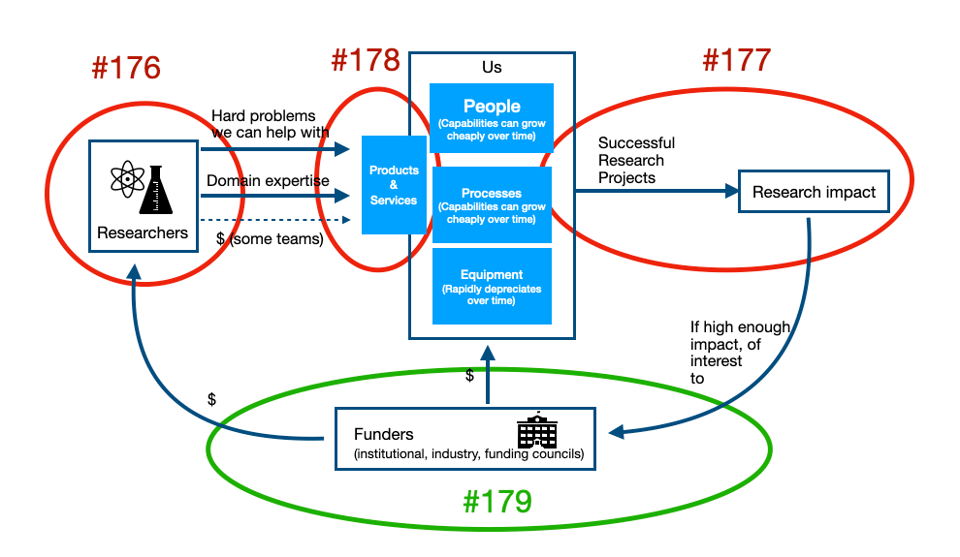
RCT #179 - Success Stories are the best advocacy. Plus: Avoiding hero work pays off in the end; Good progress updates; Design is not recoverable from implementation; Product management at a science tech company; Code-review.org; Configuration shouldn't change version-controlled source code
We’re going to continue the series based on this seemingly simple diagram. The diagram sketches out the flywheel of a successful technical research support...
RCT #178 - Offer services worth paying for. Plus: Effective vendor relationships; Teaching Humanists Changed How This Team Teaches Everyone; Service sludge toolkit; Existing knowledge and collaborations improves agility
Offer Services Researchers Would Be Willing To Pay For I want to keep talking about this diagram, and point out something that seems logical to the point of...
RCT #177 - Do the highest bang-for-buck work. Plus: What to say after a failure; GitHub Copilot’s productivity benefits; Research data services landscape at Canadian and US institutions; What modern NVMes can do.
Do the highest bang-for-buck work. Plus: What to say after a failure; GitHub Copilot’s productivity benefits; Research data services landscape at Canadian...
RCT #176 - Nurture your best clients first. Plus: Write and get feedback on tech specs; technical documentation guidebook; wrap up projects; talent leaks out of funding gaps; reproducibility of jupyter notebooks; 10 simple rules to manage lab data; NIST on HPC security"
Nurture your best clients first. Plus: Write and get feedback on tech specs; technical documentation guidebook; wrap up projects; talent leaks out of funding...
RCT #175 - Digital Humanities’ LLM Edge? Plus: EOLing a Product; Product vs Project; Directing Contributors Where Needed; Commercial Products and Reproducibility; Federated Analysis Primer; And the Job Board Returns, Maybe?
Happy 2024! RCT took a bit of an unplanned long holiday break, due to life intervening; all’s well now, and I’m looking forward to the year ahead. The next...
RCT #174 - Roundup - Building trust; Internal engineering conferences; Don't get stuck on finding a mentor; SlackLog; Single Decision Makers; Incident Response and Postmortems
Hi, all! The holiday season is starting! I don’t have an essay here for you this week, but I do have lots to share with you in the roundup - so let’s get...
RCT #173 - The measuring stick is the best teams, not the absence of work. Plus: I2ic organization report; New CaRCC Capabilities Model Assessment Tool; EPSCoR CI Recommendations; Racks as the unit of infrastructure; Slurm on Kubernetes
There’s a number of technical research support teams where the institution would be better served by disbanding the team and freeing up the money for...
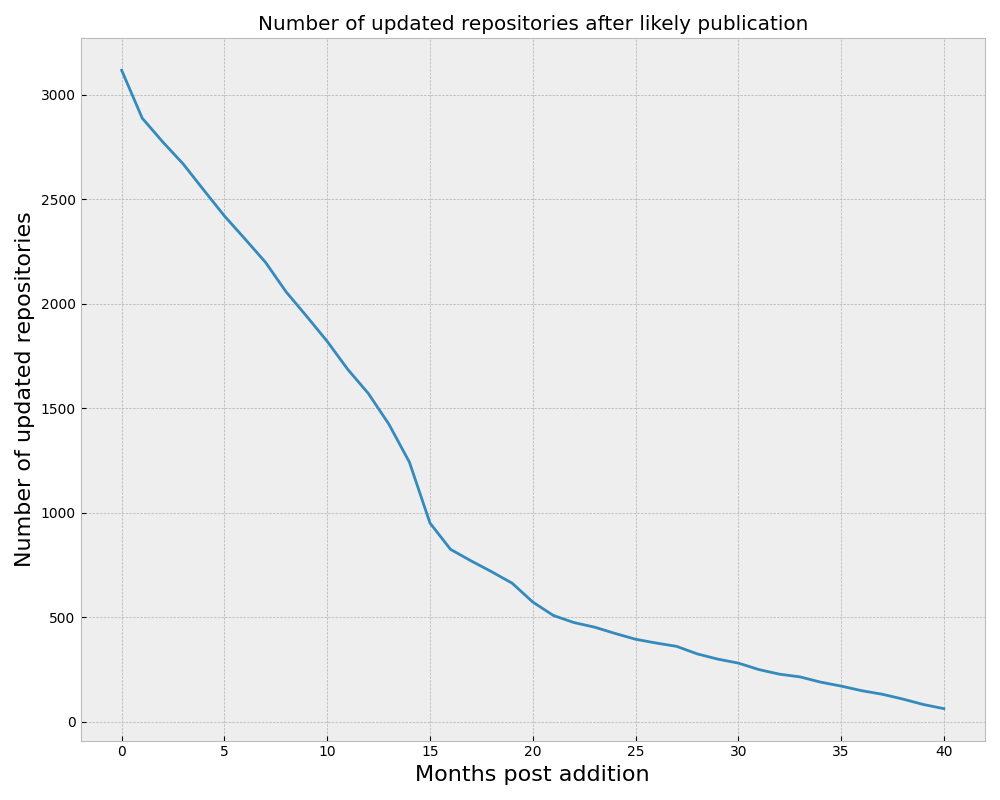
RCT #172 - 'We Can’t Hire' isn’t a good enough bug report. Plus: Management Problems at ITER; Valuable Software is Updated
Over in the other place I encourage readers to use their existing scientific skills and apply them to how they work as a manager. There's a lot of...
RCT #171 - Know What Your CIO Is Thinking about AI. Plus: The fast track tip; Huh as a signal; Prioritization together; Strategy as group choosing; Lessons from building CLIs
Do you know what your CIO is thinking about and planning for AI? We owe it to research at our institutions to know, and to both shape their thinking and...