Research Computing Teams Link Roundup, 27 Aug 2021
Hi, everyone:
I hope that as the start of the academic year approaches in the northern hemisphere, those of you who are going back to campus are comfortable doing so, and supported by administration.
Thanks to community members volunteering, we have a small core of 4-5 people who will start helping with resources for the community making suggestions to guide the newsletter. If you have suggestions, or want to take part, just hit reply or email me.
And now, on to the roundup:
Managing Teams
The 3 Stay Conversations: The Best Way To Improve Employee Retention - Know Your Team, Clare Lew
The Final One-on-One: 7 Questions to ask When Offboarding Employees - Anita Chauhan, Hypercontext
After 18 months of pandemic, with everyone tired while tech industry employee demand and salaries are skyrocketing, incautious research computing team managers risk losing their most ambitious, high-performing, team members.
In the first article, Lew lists three sets of conversations to routinely have with team members during one-on-ones:
- Clarifications about the team member and their work (what has motivated them, is it clear why what they do in particular matters, are there skills of theirs not being used)
- Questions around team dynamics (do they wish they were interacting with another part of the team more, do they like the current level of interactions, how do they like to be recognized for their work)
- Questions about organizational context (are there areas of the org they wish they knew more about, what has been confusing lately, is the vision clear).
These seem like great detailed questions to ask periodically. It might usefully be augmented by very frequent high-level open-ended check-ins. For instance, with manager-tools employee retention question - “Hey, overall, how’s it going?” - asked routinely in one-on-ones, as a way of detecting whether your team members have any issues or concerns which might lead them to having their shields down to other opportunities.
If people do leave, we should celebrate that - growth and development and moving to new roles is good and healthy - even if it’s a pain for us. In addition, a team member leaving can be a good time to get some unvarnished feedback if you’ve spent the time together building a good working relationship. Chauhan recommends some questions, including:
- Is there anything we should be aware of as we take over your responsibilites?
- If we could improve, how would we do it?
- Did the job live up to your expectations?
- What was the most enjoyable part of your job?
- What qualities and skills should someone have to be succesful in your role?
- Who do you feel is doing an outstanding job on the team?
Performance Review: Build Your Process and Master Feedback Delivery - Gábor Zöld and Lara Hogan, Coding Sans
In my institution it’s annual review time - it’s a pretty lightweight process here. It might actually be too lightweight - a manager who isn’t routinely giving their team members direct feedback could easily skate through this review process with some platitudes and go an entire year without ever giving their team members any useful information about how they are doing. On the other hand, massive annual processes cause their own pain, if only through non-compliance.
In a field as quickly-shifting as research computing, setting goals annually requires unfeasible powers of prognostication. I like setting and reviewing goals for work, skill development, and career development every 3-4 months - our template form is here. New managers: you are not as limited by official HR processes as you likely believe! Your HR business associate would be delighted to hear that you’re setting goals and reviewing progress with your team members more often than the bare minimum enforced by policy.
Regardless - however you and your institution organize performance review processes, it’s important for the team for expectations setting, an important lever and responsibility for you as a manager, and a stressful time for your team members. In this blog post coming out of a podcast episode, Hogan gives a detailed walk through of her approach to the process; it’s a terrific discussion. She covers:
- Getting input from stakeholders and synthesizing it
- Provide what they need to make any improvements they need to make
- What should go in a performance review - no surprises, super specific points, focus on behaviours, what would need to be changed, and why
- How to prepare for giving the feedback
- How to present the report
With a bonus of how to prepare to receive feedback when its your turn.
Hogan makes an important point early on - none of your feedback given in a performance review should ever be a surprise. You’re their manager - you can, and have the responsibility to, give them timely feedback as needed; the purpose of the review process is to synthesize and memorialize that feedback and make plans together as to next steps. She also emphasizes connecting the feedback to things they care about, such as career development goals.
There’s a lot of good material here, and it’s worth going through if you’ll be giving a performance review any time soon - or even if you’re not but you’d like to up your performance expectations conversation skills.
Managing Your Own Career
Demystifying Public Speaking - Lara Hogan
A lot of us who came up through research tend to no longer focussing on giving good presentations, because after all - we gave a million presentations about our work. We’re old hands.
But the presentations we’re asked to give leading research computing teams are very different than the extremely specific sub-genre that is academic presentations, which are mostly teaching people who are already experts about some new work we’ve recently done. We’re usually making cases for particular actions, or giving status reports, or training, all the while speaking to a very broad audience. Also - look, the quality/interestingness bar set for academic presentations is pretty dire.
Hogan’s book is a simple overview of giving more general-purpose presentations. Several sections of this book - choosing a topic and a venue, getting over pre-talk jitters, what to pack and bring on talk day - will in fact be old hat to veterans of the academic colloquium circuit. But sections 4 and 5 on crafting the structure of the talk, arranging post-talk resources, practicing and getting feedback before, and taking notes afterwards of what worked and what didn’t, are useful, especially for people who haven’t thought critically about this since grad school.
Check Your Work, Ask for Help, and Slow Down - Michael Lopp
Making decisions as a manager is scary, and it gets harder as your responsibilities grow. In this very sympathetic article for decision-makers, Lopp has some recommendations for you once you think you have a decision:
- Check your work - are there aspects of the situation you haven’t thought about? Are there other options?
- Ask for help - from the team, and from your peers
- Slow down - most decisions are less urgent than they seem
- What if I’m wrong - make sure you understand what will happen if the decision is the wrong one (it’s often not as scary as it sounds)
Product Management and Working with Research Communities
Patterns in confusing explanations - Julia Evans
We do a lot of training and other explaining to broad communities - perhaps in presentations, as above! - and it’s important to have clear explanations.
Evans, who writes extremely clear explanations on a range of technical topics, often about things she’s recently learned herself, has seen a list of common anti-patterns in explanations she’s read on technical topics, and lists them here with some examples and better ways. I’ve paraphrased the list for stand-alone summary purposes:
- Making outdated or internally-inconsistent assumptions about the audiences knowledge
- Strained analogies
- Mismatch between dry explanations and “fun” illustrations
- Unrealistic examples
- Meaningless jargon
- Too many concepts introduced all at once
- Starting out with abstractions or concepts before getting to concrete needs (we are terrible about this in academia and tech), but also
- Explaining the what without the why at all
- Unsupported statements
- Explaining the “wrong” way without first saying its wrong - shreds trust of the rader
but if you’re at all interested in improving the explanations you and your team share in anything from documentation to presentations to downtime announcements to anything else, this is a good starting point.
Research Software Development
GitHub Discussions is out of beta - Evi Liu, GitHub Blog
GitHub Discussions is now officially generally available, and provides an entire forum - with Q&A and open discussions, pin announcements, enable moderation, grant higher permissions to frequent contributors, create polls, for your users, and more. You can convert issues into discussion topics, too.
Have any readers started doing this for their projects? It seems a lot easier than setting up a slack or something for community feedback, and a lot easier for a potential new user to participate in than filing an issue.
20 Questions a Software Engineer Should Ask When Joining a New Team - Thomas Stringer
This is written as advice to candidates to ask their hiring managers in interviews, but they are also a good set of questions for research software development teams should ask themselves and have ready as good answers (or unsolicited information) for incoming candidates before they start hiring.
Stringer’s questions cover working with the code, working with the team, working with the users, and the product(s) as a whole:
- Working with the code - how do developers locally build and test the software, how is CI/CD setup
- Working with the team - how is the team structured, what meetings and rituals are there, what communications tools do they use, who is available for beginner quetsions
- Working with the users - how does feedback work, what support requirements are there, where is the documentation
- Working on the product - what are high-level issues with the existing software, where are stakeholders focussed, what is the release cycle
A candidate who is given all of this information at once, before hiring or as part of onboarding material, would have a lot of confidence that they’re joining a team that has their stuff together.
Research Data Management and Analysis
The big-load anti-pattern - Daniel Lemire
The obvious and easy thing to do when processing a lot of data is to load it all in memory. Sometimes this is the only feasible approach unless you want to do a lot of work, as Lemire points out it scales poorly even if the machine you’re using has the necessary memory - with the simplest possible example, Lemire shows a slowdown of 3-4x going from 1MB to 1GB, and 1GB isn’t a tonne of data. All of the caching infrastructure of your system, from disk to RAM to CPU, works better and faster with processing small chunks of data at a time.
Lemire recommends:
- make use of chunking that is almost certainly implemented in whatever readers you are using
- split the data, by horizontal (rows) or vertical (columns) shards
- make use of compression, and compress small chunks
Research Computing Systems
Hot Chips: Here Come the DPUs and IPUs from Arm, Nvidia and Intel - John Russell, HPCWire
HPC hasn’t been alone since at least 2009 in trying to manage single computing systems that are datacenter-sized.
“Smart NICs” offloading some computation - like MPI collective aggregations - to the network cards have been available for some time. But there are increasingly stringent needs. This article provides a nice quotable fact via Intel - Google and Facebook claim that anywhere from 22% to 80% of CPU usage from many micro service workloads go to infrastructure handling, like network security (IPSec, TLS), networking control (traffic management and shaping), etc.
Hyperscalers like AWS and Azure have been pushing these functions to their own hand-rolled network cards developed with ASICs or FPGAs, but demand is growing enough that NIC vendors are looking to turn these into products. It’s not straightforward - handling these tasks at line speeds while speeds increase requires significantly more compute power, and programmability. The result is what everyone else is calling DPUs, and intel is calling IPUs because it used DPUs for something else.
The IEEE Hot Chips conference had a session on these units from ARM/Marvell, NVIDIA, and Intel, and Russel here helpfully summarizes and compares the plans.
Interestingly, all the DPUs are ARM based, even Intel’s. As is required for application offload, they’re all quite programmable. The aims are impressive - 400-800 Gbps ethernet, with switching, security and QoS at line speeds, direct memory access with ROCEv2, and more.
This is a good overview of products coming down the line and if you’re interested the summary and links to other materials is a good starting point.
Eats Safety Team On-Call Overview - Eduardo David and Josh Kline, Uber Engineering Blog
An important requirement for reliable systems is a well-defined set of responsibilities for being on-call outside of regular working hours. It doesn’t necessarily have to be onerous, depending on what the reliability goals are, but if you want to avoid people stressing out over things that don’t matter, or being too lax over things that do, or not knowing what is whose job, there has to be something explicitly written down.
This post by David and Kline is a nice, short, and unusually specific writeup of how Uber Eats handles on-call:
- Definitions of on-call teams; a primary responder, a secondary responder (presumably in smaller teams we could make this less of a responsibility and more of a back-up) and a defined role for a “shadow” for onboarding/training
- Alert notification policy, saying how alerts are commuincated (and escelated)
- The rotation schedule
- Before on-call preparation checklist
- After on-call handoff meeting
What I found most interesting is the hand-off meeting, and on-call quality metrics. The goal is to make on-call as reasonable as possible, and that means not getting paged for stuff that can wait until morning, or that the paged person can’t do anything about. It also means having high-quality runbacks so if there are things that need to be fixed, it’s clear to the on call team what needs to be done. So they collect data from the on-call team about exactly these items, so they can improve things.
(Interestingly - they are using this blogpost in part as a recruiting tool. “Look how reasonable our on-call is, and how we work to improve it. Hey, we’re hiring”. There’s a lesson in there for our teams.)
Emerging Technologies and Practices
Playing with a Quantum Computer - Rainer Müller, Franziska Greinert, arXiv 2108.06271
Even 15 years ago, this would be a pretty fantastical sentence: The authors of this paper show how to use freely-available real quantum computers as teaching labs for undergraduate physics courses.
IBM Quantum and Quantum Inspire have free tiers, and other cloud providers have free tiers which can be used for their quantum simulators which allow one to develop against the APIs that are used for their quantum computing resources.
There are a number of classic quantum algorithms - Shor’s algorithm for factorization which is complicated, or the artificial but simple Deutsch–Jozsa algorithm determining if an algorithm returns binary constants or 50/50 ones and zeros. Müller and Greinert, for their purposes, want something that is both relatively straightforward to program in a gate-baed quantum computer but also interesting and easy to reason about for undergrads.
The “Coin Flip” game is a not-very-interesting game where two players have a penny in (say) a heads-up state, each determine their move (flip or not-flip) a penny, and player 2 wins if it ends up heads else player one wins. In David A Meyer’s Quantum Coin Flip game, the coin is a quantum bit in the |0> state, classical player 1 is limited to the classical flip or no-flip moves, and quantum player 2 can “move” by applying an arbitrary unitary transform to the qubit. In this game, the quantum player has a move that will always win. (“Unlike Bob, Alice knows the laws of quantum physics and is able to perform all conceivable quantum operations on the qubit.”)
Programming (here in IBM’s quantum composer) the winning strategy is relatively straightforward, it helps demonstrate both unitary transformations and measurement by projecting onto the 0/1 states, and (helpfully, pedagogically) it demonstrates a state of affairs that’s completely impossible for the classical version of the game, where there is no winning strategy.
We often talk about research computing as a way of simulating experiments of physical systems - this is the first time I believe we’ve described a situation where the research computing environment actually is a physical undergraduate laboratory of the actual system.
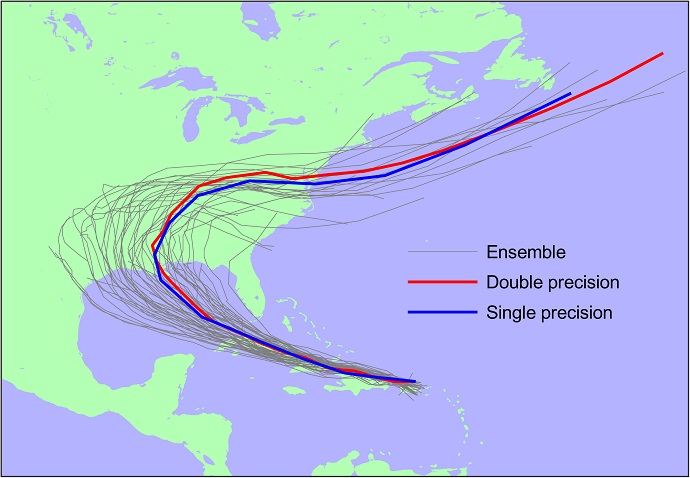
More Proof Points for Low Precision HPC - Nicole Hemsoth, Next Platform
High Performance Correctly Rounded Math Libraries for 32-bit Floating Point Representations
- Jay Lim and Santosh Nagarakatte, ACM SIGPLAN blog
Lower-precision calculations in HPC aren’t new - multi-precision methods come up often in the literature of the late 90s and early 2000s, when the use of smaller floats for parts of the calculation started looking attractive as memory bandwidth started to play a larger role in technical computation.
But those methods are more complicated and subtle than just using double for everything, and until AI started really driving hardware efficiency advances (and awareness) on FP32, FP16, and BF16 computations, most felt it wasn’t worth it.
The article by Hemsoth highlights recent work done by the European Centre for Medium-Range Weather Forecasts (ECMWF) and others on using lower-precision calculations in climate and weather calculations. Both the fully-fledged weather forecast simulations (showing forecast tracks of a hurricane) and shallow-water calculations show significant performance increases with lower-precision and compensation, and perfectly acceptable accuracy:
The article by Lim and Nagarakatte outlines the work of creating accurate and highly performant rounded math libraries for lower-precision floats.
For those intereted in learning more, here’s a great survey paper on numerical methods using mixed precision from 2020.
Events: Conferences, Training
IEEE Cluster 2021, 7-10 Sept, Virtual, $65-$140
Very broad conference on cluster computing, which includes workshops like the interesting-looking Workshop on Re-envisioning Extreme-Scale I/O for Emerging Hybrid HPC Workloads (REX-IO ’21)
RustConf ’21 - 14 Sept, Virtual, $106, $7.32 for students or unemployed
Rust is becoming popular for the sort of things research software teams would typically write in C++; sessions on fuzzing and optimization (with the case of a machine learning algorithm) may be of interest.
New Zealand Research Software Engineering Conference 2021 - 15-17 Sept, Online, $40 NZD
Covers a wide range of applications and methods for research software development in the New Zealand context, with meetups and workshops associated with the conference.
Training Virtualization - 23 Sept, 3pm-4:15pm EDT, Online, Free registration.
From the website:
Many organizations abruptly transitioned from a primarily on-site to a primarily remote work experience last spring. However, organizations still have training needs that were once largely accomplished through in-person events such as workshops, hackathons, and tutorials. This panel will share what they learned during the past year in their efforts to bring more virtualization to what historically has worked for in-person training events. What worked well? What did not work? This panel will share their insights about lessons learned over the past year and how those experiences will inform plans moving forward when organizations can safely offer in-person training again.
Random
An opinionated guide to xargs, an essential shell tool for handling large numbers of files or items.
This week in git I learned: You know how git suggests the “right” version of mispellings? Apparently if you like to live dangerously you can have it automatically run the suggestion. You can also have conditional blocks in your gitconfig.
Part one of a story of how ispc, a compiler for Larrabee, came about.
Nice story from the Facebook team of how they built ZippyDB, a distributed sharded key-value store built atop RocksDB.
Datalog is having a moment. Datalog in Haskell, Datalog in bash (along with a datalog→bash translator) and Datalog in python.
Sure, playstation 5s look cool, but how about an even cooler gaming platform - DOS games, with 19 games released so far in the 2020s(!)
Building a Commodore PET with components available today.
Ooh, GitHub is finally improving their issues/project boards - by a lot, it looks like.
Making the case that in 2021, unix tools should be outputting not plain text but JSON - and providing a tool to help. Which might make this introduction to jq handy.
PlsExplain, a simple programming language with first-class comments, and where every value is associated with a history of comments.
Huh - apparently a number of terminal emulators (iTerm2, Gnome terminal, …) have support for control codes which make URLs or link anchor text clickable. And if you want to know about accessibility with colours in the terminal, it turns out that the terminal game community (e.g. roguelikes like Nethack) have put a lot of thought into it.
An argument (correct, I think), that SQL vs NoSQL isn’t a helpful distinction, and instead strict vs loose schema validation is the split to make.
A free book on SAT-solvers (and SMT solvers) by example.
Function-as-a-service (AWS Lambda) for bursty monte carlo computations.
A deep dive into API authX tokens.
That’s it…
And that’s it for another week. Let me know what you thought, or if you have anything you’d like to share or ask about the newsletter or research computing teams. Just email me or reply to this newsletter if you get it in your inbox.
Have a great weekend, and good luck in the coming week with your research computing team,
Jonathan
About This Newsletter
Research computing - the intertwined streams of software development, systems, data management and analysis - is much more than technology. It’s teams, it’s communities, it’s product management - it’s people. It’s also one of the most important ways we can be supporting science, scholarship, and R&D today.
So research computing teams are too important to research to be managed poorly. But no one teaches us how to be effective managers and leaders in academia. We have an advantage, though - working in research collaborations have taught us the advanced management skills, but not the basics.
This newsletter focusses on providing new and experienced research computing and data managers the tools they need to be good managers without the stress, and to help their teams achieve great results and grow their careers.
Jobs Leading Research Computing Teams
This week’s new-listing highlights are below; the full listing of 171 jobs is, as ever, available on the job board.
Senior Firmware Engineer - Machine Learning Team Lead - Milwaukee Tool, Brookfield WI USA
As a Team Lead within the Machine Learning group, you will be a hands-on leader tasked with enabling (electronics and sensors) and implementing (firmware) machine learning solutions. Your team members will be tasked to highly cross-functional teams to make power tool solutions that change the lives of our users. In addition, you will act as a technical expert in the creation of these concepts and support them as products through implementation, validation, and transfer to production.
Technical Product Manager - Scientific Platform, Computing and Analytics - Amgen, Burnaby BC CA
In this role, you will be part of the team which plays a meaningful role in accelerating early pipeline work by incorporating novel analyses and models into easy-to-use software tools accessible by all scientists. You will work with user communities, vendors and teams of data scientists and software developers to establish the roadmap of needed analyses/models and how they should be coordinated into scientists’ workflow with the best user experiences. Our success in informatics is encouraged by our dedication to our patients, to our business partners, and handle to use technologies that deliver critical business value. Further, we at Amgen are building upon long-term dedication to patients by developing a whole new class of novel molecules – and we need top talent to ensure these molecules become medicines and realize their potential for helping patients.
Senior Storage Systems Administrator - University of Bristol Advanced Computing Research Centre, Bristol UK
A new and exciting opportunity has arisen for a skilled and motivated Systems Administrator to join the University’s Advanced Computing Research Centre (ACRC), one of the UK’s leading centres for High-Performance Computing (HPC) and Research Data Storage. The role holder will support a wide variety of researchers and workflows and will have the opportunity to engage with many cutting-edge storage technologies. The RDSF uses IBM’s Spectrum Scale parallel file system backed by many petabytes of disk and SSD storage. An innovative Hierarchical Storage Management system couples this to tens of petabytes of tape storage. The backend storage libraries and arrays are connected by a Fibre Channel SAN to highly available cluster of servers providing network attached storage to several thousand users.
Principal Exascale Software Engineer - Cambridge Open Exascale Lab, Cambridge UK
The COEL is housed within Cambridge Research Computing Service a long standing and leading UK National Supercomputing Center, providing HPC services to world leading scientists, medics and engineers across the UK. We operate the UK’s most powerful academic supercomputer, the UK fastest academic AI system, the UK’s fastest data storage solution and the UK’s first production 10 petaflop GPU/X86 heterogenous system. The Principal Exascale Software Engineer will manage a small team of highly technical research software engineers on multiple projects to develop and optimise advanced scientific applications for the next generation of supercomputing technologies. The successful candidate will work with closely with the technical programme manager, key academic collaborators and external stakeholders to define and assure successful delivery of the projects.
Principal Exascale Systems Engineer - Cambridge Open Exascale Lab, Cambridge UK
The COEL is housed within Cambridge Research Computing Service a long standing and leading UK National Supercomputing Center, providing HPC services to world leading scientists, medics and engineers across the UK. We operate the UK’s most powerful academic supercomputer, the UK fastest academic AI system, the UK’s fastest data storage solution and the UK’s first production 10 petaflop GPU/X86 heterogenous system. The Principal Exascale Systems Engineer will manage a small team of highly technical engineers working on several projects focussed on integrating and optimising a variety of systems middleware, high performance filesystems, advanced networks and accelerators in order to take advantage of upcoming state-of-the-art supercomputing, Big Data and AI technologies.
Manager, Data Science - Harlequin, Toronto ON CA
You will be a strong and confident communicator, can tell stories through data visualization, who is adaptable to many different levels of data availability, analytics maturity and technology platforms/toolsets and juggling multiple priorities. You will have an opportunity to work with a brand driven, industry leading publisher to grow your skills across the full spectrum of data science in the field of analytics.
Science Manager/Managing Consultant - UK Met Office, Exeter UK
You will be leading, and developing, a team of scientists and scientific consultants working in environmental, public health and marine projects on scales ranging from short-term to seasonal and climate time scales. You will also be managing and delivering projects closing the gap between science and society, within the spirit of the UN Sustainable Development Goals.
Climate Data - Team Lead - Lewis Davey (Recruiter), London UK
You will be able to manage the Data Collection Team and develop the team to build the corporate engagement function. Manage the process of allocation of collection tasks. Be responsible for Quality Assurance of emissions data collected. Increase quality and coverage of data collected. You will build team expertise in understanding of GHG protocols and emissions data. You will build team expertise in understanding of science-based targets and EU taxonomy. Lead the corporate engagement – build relationships with ESG reporting related areas of large corporates. Work alongside the Head of Climate Risk and Snr. Climate Analyst to expand the data and analytical offering.
Head of Scientific Computing - Diamond Light Source, Harwell UK
Advances in data management, data storage, automation and remote access ensure Diamond remains world-class and world-leading. As a result we are now searching for an IT Leader who can drive our IT strategy within our specialist scientific computing services and core infrastructure. One of the defining features of many modern scientific facilities, from hadron colliders to gene sequencing factories, is the avalanche of data they generate. We will require you to develop and design a 5 year strategy to substantially expand our IT hardware (disk farms and compute clusters) to support an additional data centre, of around 1MW capacity.
High Performance and Research Computing Manager - University of Hertfordshire, Hatfield UK
The School of Physics, Engineering and Computer Science is seeking to appoint a High Performance and Research Computing Manager to support scientific computing across research and undergraduate / postgraduate teaching. SPECS is a research-active School with a strong track record in Physics, Astronomy, Engineering and Computer Science with many researchers requiring high-performance computing support; many students on our undergraduate and postgraduate programs also require access to such facilities. We currently operate a 5000-core Linux-based HPC facility that was designed and built within the School and are expecting considerable expansion over the coming years with a particular focus on teaching support.
Director, Scientific Computing - Janssen R&D, Springhouse PA or Raritan NJ or San Diego CA or Titusville NJ USA or Leiden NL or Allschwil CH or Beerse BE or High Wycombe UK
Statistics & Decisions Sciences (SDS) focuses on statistical and data evaluation needs for discovery, clinical trials, manufacturing, and safety sciences data. The Scientific Computing Operations (SCO) team within SDS excels in delivering value to the community and its partners through the use of computer technology. Primary responsibilities of the position includes identifying, establishing collaboration with, and supervision of external partners and their services at multiple locations. Strategic and technical leadership is required both internally and externally. This includes collaborations with statisticians, researchers, and information technology professionals. There is a large diversity of needs to serve, such as end-to-end management of software applications for statistical evaluation or for business processes, education in-classroom and e-learning, knowledge sharing, user interface navigation, software/application acquisition and training, and high performance computing for intensive data evaluation, simulations, and statistical research. Just as important a responsibility and accountability is formal management of a global team of direct reports and contract partners.
Technical Architect (Digital, Data & Technology) - National Crime Agency, London UK
To be successful in this role you will have strong technical architecture expertise combined with areas of deeper knowledge of technologies and practice, broad understanding of all architecture domains, and strong stakeholder and consultative skills.
Director Scientific Computing (System Infrastructure) - St. Jude Children’s Research Hospital, Memphis TN USA
Director of Scientific Computing will play a leading role in supporting incredible growth in St. Jude research and the new 6-year strategic plan for 2022-2027. Director of Scientific Computing has responsibility for scientific computing and digital innovation under the leadership of Vice President of Research Information Services in support of the St. Jude research. This high-profile position serves as an important advisor to the Vice President of Research Information Services team and will contribute to the formation and execution of the St. Jude scientific computing technology vision and strategy. The Director of Scientific Computing position provides the opportunity to be at the intersection of computer science, basic science and translational research, and systems and computational engineering to ensure the St. Jude computational architecture keeps up with the rate of innovation in the nationally recognized research hospital.