Research Computing Teams Link Roundup, 22 May 2021
Hi, everyone!
This week’s RCT Newsletter is a little slow going out; the reason ties into something I’ve been meaning to write a bit more about, usual research funding grants vs nonprofit grants and what research computing and data teams can learn from that. (Or you can go straight to the roundup).
Any funder has things they want to accomplish, and the goal as a potential fundee is to find something in the intersection of “work that helps the funder accomplish their goals” and “work that we are able to do and that is aligned with our goals”. Excellent work that isn’t in that first set won’t get funding. Money attached to work that isn’t in the second set is at best a distraction, at worst drains your teams’ credibility.
Most of us in research got our experience in grants from open disciplinary competitions where the funders and fundees goals are aligned - be seen to be funding/doing the best research. That means you don’t have to think about the distinction very much. The funder wants a portfolio of projects that are promising and could have impact - some will pan out and some won’t, but such is research. So everyone is focussed on “the best” work. There’s a lot of focus on methods and technology used, because those are relevant for assessing the best work. A new technology or method might be why it’s important to fund this work now - some key observation wasn’t possible before, but now it is, and the funder and team who makes the observation now will get the impact. And methods can sabotage a project - a team that does great work with the wrong methods won’t get the best results.
Special calls - like those that research computing projects typically fall under - and calls by nonprofit funders, are different. The funder has some particular change they want to see in the world; some community they want to see better served. They are generally much less willing to take a flyer on projects with only a modest chance of success, because failures won’t serve the community they want to see served.
Methods and technology matter much less to these funders. They want to know that you can credibly deliver on the proposal, and that you have a plan, but the nuts and bolts typically are much less interesting.
A nonprofit funder absolutely wants to understand how the after-school homework tutoring program you’re proposing will interact with the community - how it will find underserved students, how the tutoring will be delivered to the students, what indicators will be used to measure success - but the behind the scenes tech stack like what task management and tutor booking software you’ll use is completely irrelevant unless it’s to justify that you’ll be able to deliver the program. (And if you are in a position where you need details like that to justify your credibility for delivering the program, you are probably not in serious contention for the funding). Every paragraph you spend talking about the cool new tutor booking software you’re going to use is a paragraph that doesn’t get spent highlighting the funder’s goals being achieved - more underserved students doing better in school.
A research computing funder who’s receptive to a “we’ll run a new research data management platform specifically aimed at [discipline X]” proposal absolutely wants to know that you’re familiar with the underserved area, that you’ve been successful delivering similar things before, and what metrics you’ll use for success. They do not care that your roadmap includes Kubernetes and some exciting new operators. Would they be disappointed if mid-stream, you pivoted to running the tasks on bare metal with Ansible? If not, why draw their attention and yours to obscure and uncertain details rather than to how your work will best advance their goals?
The thing is, this same approach applies to not just research funders, but anyone you plan to work with; any research group that contacts your team looking for something. They have a problem; the greater the up-front focus on understanding and solving researchers problem, the better the chance of success.
How will you know what the funder’s or researcher’s problems and goals are? In the funder’s case, the call will sometimes spell it out; in the researcher’s case, they’ll usually say something. In both cases, it may require some question-asking and digging deeper; the researcher’s “presenting problem” may not be the underlying issue, and the funder’s call may focus on a particular call rather than the overarching goals. But the solution is just to ask a bunch of questions.
“Will they just tell you?” I know a team in a Hackathon who went to an open pre-hackathon info session, and approached the organizer and sponsor in a gaggle afterwards. They asked the sponsor — the lead judge — what a successful Hackathon would be from their point of view. The sponsor — who, again, was the lead judge — answered with a particular problem they’d like solved as an example. That team and mystifyingly only that team delivered a partial but promising solution to the exact problem described in detail and in public, and they of course won first prize. People organize special funding calls and hackathons because they want other people to help them achieve their goals. Yes, they’ll tell you, and if you keep asking questions they’ll keep talking about it until you politely explain that you have to leave for the evening. They put that contact information there and run informational webinars for a reason.
Anyway, that’s a long way of saying sorry for being late with the newsletter. On Monday a partner / client was looking for ideas for a project. Having spoken with them a lot I had a good sense of what they were trying to achieve and what sort of money was involved. I stared at a list of their medium-term goals until I figured out a way I could help them make progress on a bundle of them with a feasible and goal-aligned amount of work on our side given the budget, then wrote up a 2-pager focussed entirely on their goals and describing only in the broadest sense the work we would actually do. I’ve spent the entire of the past week in a scramble because now they want to get started as soon as possible.
The stakeholder side of research computing isn’t rocket surgery. But listening, digging in, and focussing on their goals is still rare enough that doing it well is almost an unfair advantage.
Have questions or comments about working with special funding calls? Or anything else? Hit reply, or email me at jonathan@researchcomputingteams.org .
Otherwise, on to the (delayed) roundup!
Managing Teams
The Three Dominoes - Mike Petrovich
These are pretty good general purpose project team and management principles that apply particularly well in research computing:
Limit work-in-progress - too many things in flight makes it harder to track progress, to review each other’s work, and keeps people context-switching too often.
Minimize specialization - also makes it hard to review each other’s work, slows people down as there are more hand-offs, and decreases bus-number of specialized components.
Never sacrifice quality - goes without saying, although what quality means will depend on the team. Scope and timeline are generally negotiable; quality shouldn’t be.
Product Management and Working with Research Communities
Collaboration and Team Science: A Field Guide - L. Michelle Bennett, Howard Gadlin, Christophe Marchand, NIH National Cancer Institute
Comprehensive Collaboration Plans: Practical Considerations Spanning Across Individual Collaborators to Institutional Supports - Kara L. Hall, Amanda L. Vogel, Kevin Crowston, Strategies for Team Science Success
Operationalization, implementation, and evaluation of Collaboration Planning: A pilot interventional study of nascent translational teams - Betsy Rolland et al., Journal of Clinical and Translational Science
Research computing and data work is inherently interdisciplinary; we often bring our computing and data skills to one other team with domain expertise in some discipline that needs our help, and frequently we are part of even larger collaborations.
But managing a single team all with the same employer and goals is challenging enough. Shepherding a cross-institution cross-discipline effort is like playing the game of management on its hardest setting.
And that means that the same approaches - being explicit and intentional about expectations, giving feedback, making sure you’re getting input from everyone, planning, and communicating those plans. In the NIH NCI field guide, Bennet, Gadlin, and Marchand have sections on topics that come up routinely in this newsletter in the single-team context:
- Setting expectations
- Psychological safety and encouraging (respectful, constructive) disagreement
- Positive and negative feedback
- Building consensus around a common vision
- Handling conflict and strengthening team dynamics
The field book is a pretty comprehensive ebook with case studies about things working well and not in each area.
In “Comprehensive Collaboration Plans”, Hall, Vogel, and Crowston suggest (with citations) what areas should be covered in an explicit collaboration plan, as outlined below.
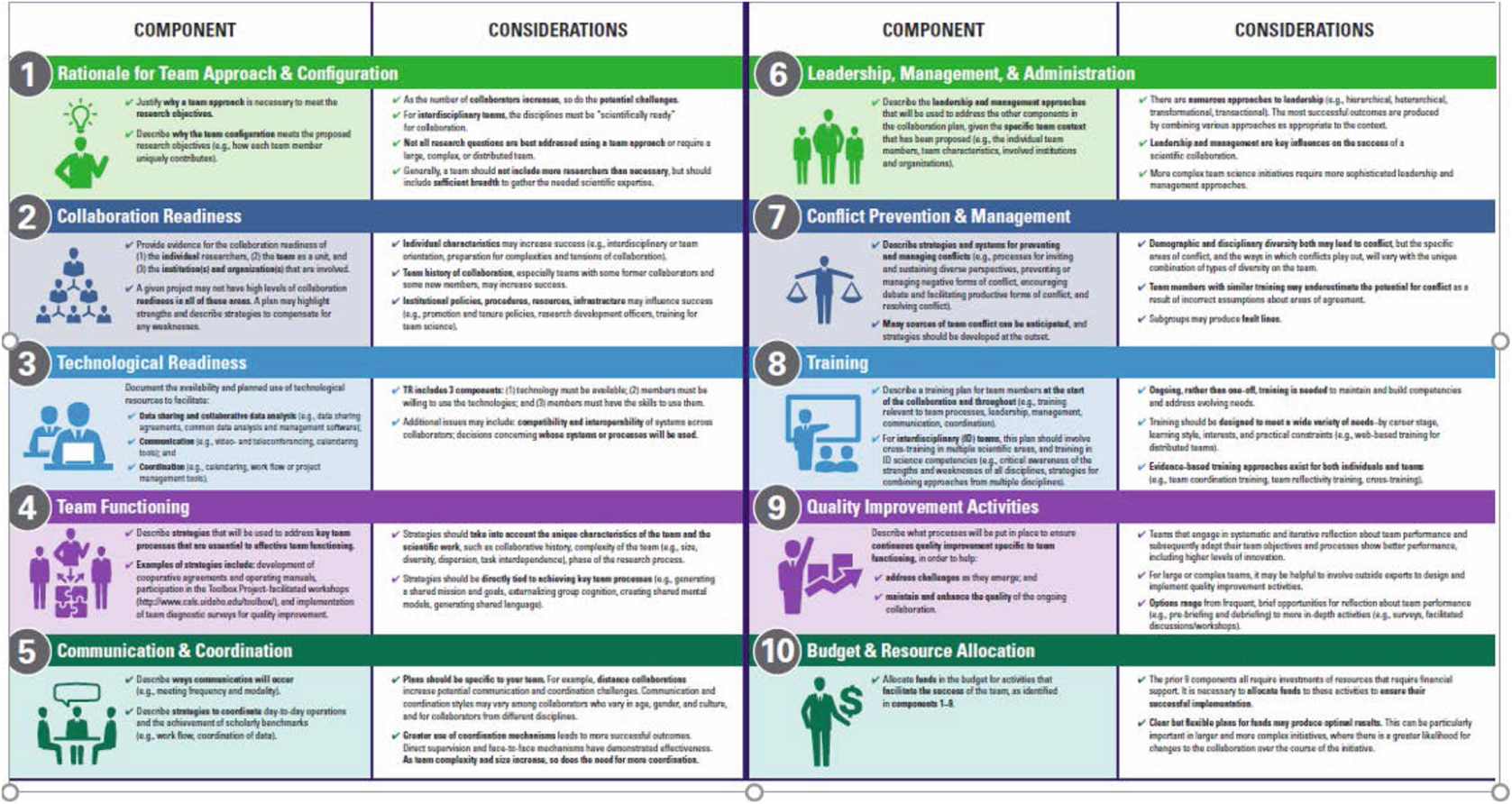
Finally, in “Operationalization, implementation, and evaluation of Collaboration Planning”, Rolland et al. offer advice from having thirteen new interdisciplinary collaborations go through facilitated sessions for doing such planning. They found that different teams needed different parts of the planning more than others, and that topics that the teams needed additional guidance were around information and data management, and more specific guidance around authorship policies and conflict management, but were broadly pleased with the results.
Obviously not every collaboration requires explicit, ten-section collaboration plan documents. But having given some thought to each of these areas, making sure there’s agreement about the items that are relevant to your collaboration early on, and keeping lines of communication open for the duration can help collaborations just as they help with individual teams.
Research Software Development
Codespaces: GitHub’s Play for a Remote Development Future - Roben Kleene
Flat Data - Ian Gazit, Amelia Wattenberger, Matt Rothenberg, Irene Alvarado
GitHub is really on a tear with things that could be of interest to research software teams. We first mentioned Codespaces when it was announced and demoed at GitHub Satellite 2020 (#23 - a year and a couple weeks ago). It’s still not in GA yet but the beta is pretty open these days - you might have to wait a bit but not long.
Kleene is a big fan, and I kind of agree. If you are used to VS Code, it’s kind of magic - you get a browser-based interface very similar to the desktop application, or you can actually use the desktop app and use it to connect to the running codespace. You have a consistent docker environment, which you can provide requirements for, containing the code you develop in an IDE available from wherever as long as you’re online.
Flat Data by Gazit et al. lets you set up a github action that runs as a cron job and downloads any kind of data (via HTTP or SQL queries against probably whatever database you run), optionally preprocess it in some way, and check it into your repository. This makes sure you can always be shipping up-to-date input data, examples, diagrams, or what have you in your repo.
Debugging: Books to Help You Get Started - Rinku Gupta, Better Scientific Software
We spend a lot of our software development time debugging, and yet never really get taught it in any systematic way. I like to think that in research we have an unfair advantage, since we’re used to the scientific method, and should be able to apply that - develop hypothesis, test the hypothesis, learn stuff, continue - but in practice after a little bit it’s pretty easy to just start flailing.
Gupta lists a number of books - whether you’re looking to improve your debugging or teach trainees or junior staff, these might be useful.
A simple way to reduce complexity of Information Systems - Yehonathan Sharvit
The data model behind Notion’s flexibility - Jake Teton-Landis, Notion
I do think that research computing broadly learned a lot of lesions earlier than the broader tech world - one is the primacy of data, whether it’s simulation output or input data for an analysis pipeline.
Sharvit is in the process of writing a Manning book on data-oriented programming, and talks about how one can do that in functional or object-oriented programming modes, and the benefits of immutable data (great in data analysis, tough to improbable in very-large scale simulations).
Teton-Landis writes about the flexible rooted tree data structure which underlies Notion pages and the kinds of use cases allows.
Getting a Repeatable Build, Every Time - Vlad A. Ionescu
Ionescu has written a pretty extensive list of tips and approaches for reproducible builds of complex packages, especially those involving scripting, Makefiles, and Docker. It starts with tips for bash scripts, collaborating in teams on Makefiles (keep it simple!), using docker wisely, and handling external dependencies. Then the tricky parts come, using caching reliably and handling secrets.
Research Data Management and Analysis
Rhumba: the fast R distribution is available on Windows! - Adrien Delsalle
It may interest those who use R or support users of R that a fast, conda-forge based R distribution is available. In #30 we talked about mamba, a reimplementation of conda that uses proper SAT solvers to make resolving environments much faster. Rhumba builds on that same approach to provide an R distribution that uses condo-forge for a large number of pre-compiled CRAN packages.
PostgreSQL: ENUM is no Silver Bullet - Duong Nguyen
A couple articles aimed specifically at PostgreSQL but that are broadly applicable to most of the big relational databases.
In the first, Nguyen goes through the options for ensuring that the value in a field is restricted to one of a finite number of values. Like so much in research computing, there’s no single “best”; it depends on how you’ll be using that value: will the application need to add new values? How easy does it need to be to map arbitrary user inputs to values? How stable are the schema? The options will likely be familiar to you — an explicitly enumerated value; check constraints, with and without the use of a function; and a separate table using foreign-key constraints — but it’s nice to have a list of the pros and cons in one place.
PostgreSQL: Detecting Slow Queries Quickly - Hans-Jürgen Schönig, Cybertec
How we achieved write speeds of 1.4 million rows per second - Vlad Ilyushchenko, QuestDB
Here’s a couple of articles that highlight why it’s a mistake to silo the broad and rich field of research computing and data into “software”, “systems”, “HPC”, “data”, etc - there’s too much potential back-and-forth knowledge transfer possible.
In the first, Schönig describes detecting slow queries in an application using an approach which would be instantly familiar to anyone who has tried to speed up a single-node compute job before - profiling. In PostgreSQL this is done with the pg_stat_statements extension; in MySQL you might use the slow query log or just turn query profiling on, or use a third party profiler. With that and a few queries of the stats table you even get something that looks like gprof output.
If HPC profiling skills would be helpful in debugging database query performance, I think better knowledge of what’s going on in databases these days could surprise and maybe inform HPC work. The HPC community is almost completely unaware of the performance work that has been happening on extremely large-scale database, which is weird because (a) the rich diversity and raw distributed size of internet-scale databases has been the big computing technology story of the last twenty years and (b) a lot of that work falls squarely within the HPC community’s bailiwick (see e.g. ScyllaDB’s Seastar library). The biggest difference between the two is that the database community started with the problems the HPC community is only starting to have to face - resiliency in the presence of failures, and unpredictable and highly-irregular communications patters, and vice versa with the HPC community having long tackled the distributed, many peer writers problem.
Time series databases are getting mature enough that they are becoming relevant for a lot of scientific data collection use cases, particularly with streaming data. Like the name suggests, these databases are optimized for gathering streams of data over time and performing analytic queries over them using things like time windows - this is a very different use case than what say MariaDB or PostgreSQL is optimized for. The usual approach in scientific computing might be to use CSVs or something for data coming in slowly or HDF5 files for faster data; those are fine if they meet all your needs, but if you want to routinely do streaming queries looking for outliers, or have a constantly up-to-date dashboard, you might want to look into time series databases like QuestDB or influxDB, or more general columnar analytical stores like ClickHouse.
Ilyushchenko’s article walks through how they ingest 1.4 million data points per second on 5 AMD Ryzen cores, including handling out-of-order datapoints so that they’re always persisted in order. The technical details wouldn’t at all be out of place in an HPC talk - C++ code, parallel sorts, comparing different memcpy implementations, AVX512 instructions, and code-comparisons with benchmarks.
Research Computing Systems
Pioneering Frontier: Planning Against Pitfalls - Matt Lakin, ORNL
This is an Oak Ridge National Lab profile of one of their staff, so it’s not an especially hard-hitting piece, but is a nice highlight of the importance of not just project management in general but risk management in particular in larger (or critical for some other reason) projects.
Like so many things in people, project, or product management - or the collaboration planning above - risk management is mostly about being consistent, deliberate, and intentional about the important things. Identifying risks to the project (in this case deployment of a big computing system, including procurement, construction, and installation), figuring out mitigations (backup plans, or doing other work to keep the risk of a given item low), keeping track of them and updating them routinely, and coordinating with other people on the project - these aren’t complex tasks; but they benefit from being done explicitly and consistently.
Also as with the collaboration planning, this is something that can usefully be done explicitly even in a greatly scaled-down manner for smaller projects. A risk register doesn’t need to be anything more than a list of bullet points that you review periodically.
Calls for Applications/Papers/Proposals
4th Advanced Course on Data Science & Machine Learning - Hybrid Online/Onsite 19-23 July, € 270- € 550, poster or presentation abstracts due 15 June
The call is out for a conference with some on-site component(!), an advanced summer course for large-scale data science/ML. Early registration (you must decide whether to register for online or onsite) deadline is the same as the submission deadline. Already scheduled lectures include intro to machine learning, probability and information, deep learning in science, data hiding and fairness, quantum machine learning, and more.
HPC: State of the Art, Emerging Disruptive Innovations and Future Scenarios, An International Advanced Workshop - 26-30 July 26-30, 2021, Cetraro – Italy, no registration fee
Another workshop with an in-person program (maybe only in person?) in Italy in July - workshop topics range from cloud and quantum computing to co-design and heterogenous systems. No registration fee, but the number of participants is limited.
SIGHPC Systems Professionals Workshop - Submissions due 17 Sept, Workshop 15 Nov as part of SC21
A workshop for HPC Systems professionals will be held again at SC; they prompt with paper ideas along the lines of
- Best practices for job scheduler configuration
- Advantages of cluster automation
- Managing software on HPC clusters
but anything from security to resilience, on-prem or cloud, dynamic or static, running or troubleshooting HPC clusters is on topic.
Events: Conferences, Training
US-RSE Virtual Workshop: “A Path Forward for Research Software Engineers”, 24-25 May, Free to register
The US-RSE virtual workshop agenda is out, with technical talks (containerization strategy for HPC, Singularity registry, installing toolchains with Spack) and talks more about RSE as a discipline itself (a sociological view, sustainability, maintaining software quality, and case studies of building a team.
I still don’t know if it’s tacky or not to highlight my own talk, but on the off chance it’s not, I’m on the schedule giving a reprise of my SORSE “Help! I’m a Research Software Manager” 10-minute crash course to some of the things we cover here in the newsletter.
NVIDIA GTC 2021 Talks Now Available On Demand
If you didn’t get a chance to register for GTC 2021, many of the talks are available online. Lots of great talks in there on datacentre and networking, data science, HPC, as well as the usual GPU programming and AI stuff.
Random
I think there’s a lot of lessons here for people supporting communities with computing - it’s not just about the amount of hardware you throw at a problem. How M1 Macs feel faster than Intel models: it’s about QoS.
The Downtime Project is a new podcast walking through public post-mortems of notable downtimes and other failures.
As you likely know, I think long term stable OS releases are a trap for research computing teams. Still, others disagree, and if you find yourself among them it may please you to learn that the first release of Rocky Linux, a CentOS alternative, is available.
Keenwrite is a markdown-based text editor with string interpolation for defining names and the like consistently across large documents.
Dragged kicking and screaming back to Javascript after a long time away? A lot has changed.
Cosmopolitan Libc aims to make “C a build-once run-anywhere language” with executables that can run on Linux, Mac, Windows, *BSD, etc.
Ever wanted to write a program using only the word “Ook”, or by creating two-dimensional images or text? Esoteric languages may be for you.
Finally, a URL Lengthener. Tired of easily and painlessly tying “ https://www.researchcomputingteams.org ” all the time? Great news, now you can tediously and excruciatingly direct your browser to https://aaa.aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa.com/a?áaaÂáaaÂáaaÂáaaÂáaaÂáaaÂáaaÂáaaÂáaaÂáaaÂáaaÂáaaÂáaaÂáaaÂáaaÂáaaÂáaaÂáaaÂáaaÂáaaÂáaaÂáaaÂáaaÂáaaÂáaaÂáaaÂáaaÂáaaÂáaaÂáaaÂáaaÂåAæãæãæaæââÁáÆáÆææææææáÅæáåäæâåäåàæáåâåAåâåÆåÄæaæäæãåÀåÅåææãåäåàåÄæâáÅåÆæáåæ
Speaking of which, once you’re there you can now search back issues of the newsletter.
Last issue, I posted a link about AWS Graviton2 vs Intel Skylake nodes on WRF; a video of a dig into the why of the performance, going into memory subsystems and MPI collectives can be found here.
In software development people use a lot of terms like “decoupled code” and agree that it’s important but there’s no single definition of what that means or looks like and it means that we’re often talking past each other.
A presentation on programming in a sensible style in APL.
The case for wireframing web pages and apps in Google Sheets.
A great story describing in detail how the 2011 RSA hack happened.
That’s it…
And that’s it for another week. Let me know what you thought, or if you have anything you’d like to share about the newsletter or management. Just email me or reply to this newsletter if you get it in your inbox.
Have a great weekend, and good luck in the coming week with your research computing team,
Jonathan
About This Newsletter
Research computing - the intertwined streams of software development, systems, data management and analysis - is much more than technology. It’s teams, it’s communities, it’s product management - it’s people. It’s also one of the most important ways we can be supporting science, scholarship, and R&D today.
So research computing teams are too important to research to be managed poorly. But no one teaches us how to be effective managers and leaders in academia. We have an advantage, though - working in research collaborations have taught us the advanced management skills, but not the basics.
This newsletter focusses on providing new and experienced research computing and data managers the tools they need to be good managers without the stress, and to help their teams achieve great results and grow their careers.
Jobs Leading Research Computing Teams
This week’s new-listing highlights are below; the full listing of 154 jobs is, as ever, available on the job board.
Manager, Research Data Services - Cedars-Sinai, Los Angeles CA USA
This role is a blend of systems and architectural skills and collaboration with clinicians and researchers. The goal is to design, build, maintain and support a world class research data and compute infrastructure. The Manager, Research Data Services is responsible for designing, architecting, and delivering systems to support sophisticated and varied operational and research workloads in a hybrid on-prem/cloud environment. This role manages provisioning project and role-based access to system resources for clinical and research end-users.
Senior Computational Imaging & Informatics Scientist - Rutgers Cancer Institute of New Jersey, New Brunswick NJ USA
The primary purpose of the Senior Computational Imaging and Informatics Scientist is to work closely with the CIO and other members of the team to ensure the success of the Biomedical Informatics mission: realizing translational medicine by working at the interface of IT, biology, and medicine to link bench and bedside using imaging and informatics software technologies. The Bioinformatics Specialist will support the computational imaging and informatics needs of researchers at the Rutgers Cancer Institute of New Jersey. Leads the activities of small groups of bioinformatics scientists and application developers, establishing project plans, monitoring progress and resolving issues regarding ongoing and new projects.
Director of Data Engineering - Exscientia, Oxford UK
Exscientia is committed to discovering medicines in the fastest and most effective manner. We achieve this by applying the latest research in Artificial intelligence (AI) to transform drug discovery. Exscientia are the first and only company to have AI designed molecules in clinical trials. We are currently seeking a highly-motivated Director of Data Engineering with a talent for developing high performing teams delivering complex systems within the drug discovery industry.
Director, Data Science - Octave Group, Montreal QC CA
At Octave Group, we believe in the power of music to inspire emotional connections in shared spaces, transforming the way people interact with each other and with their surroundings. The Director, Data science will manage a team of data scientists, engineers and analysts and lead and develop our data roadmap and infrastructure, provide business insights, scope, design and implement machine-learning models. The Director, Data science, is innovative, analytical and has excellent communication skills to work cross-functionally, with engineering, marketing, finance, and operations to support all data projects.
Head of Informatics - Sana Biotechnology, San Fransico CA USA
The Head of Informatics is a senior role accountable for providing leadership and setting strategy across technical domains that include our research computing infrastructure, partnership with IT, our company-wide initiatives on data management and data ontology, and automation scaleup including communication of strategy to senior executives. This role will lead the design, implementation, and operations of our research & process development data architecture, AWS strategy for informatics infrastructure and research data management, and automation.
Director of the San Diego Supercomputer Center (SDSC) - University of California San Diego, San Diego CA USA
Reporting to the Senior Associate Vice Chancellor for Academic Affairs within the office of the Executive Vice Chancellor, the Director is responsible for the strategic direction and operational management of SDSC, the leadership of its 220+ employees, the management of its $40 million+ annual budget, and the development and maintenance of its state-of-the-art space on the UC San Diego campus. The Director will play a key role in shaping the future of research computing nationally and will contribute to the next wave of computing innovations in a collaborative and competitive global arena. At the same time, SDSC’s new Director will strengthen its engagement and alignment with UC San Diego’s academic mission.
Senior Software Engineer, Data Intelligence - CircleCI, Remote
Product engineering teams at CircleCI are staffed with around 7-8 engineers, a dedicated engineering manager, and other members like product managers, data scientists and analysts, designers, and user researchers. You’ll be a part of the hiring and staffing process for this team - from working with engineering leadership on establishing skillset needs, to interviewing candidates, to onboarding new teammates. You’ll also have the opportunity to interact and collaborate with teams across our product and platform engineering organisation. Teams like our core engineering group, our data science and infrastructure teams, and our growth engineering teams, helping our customers engage with our platform at every step of the way.
Principal Data Manager - Biometrics - Covance, Remote US or CA
Data Management leadership on studies considered to be high complexity. Take responsibility for the development of the project documentation, system set-up, data entry and data validation procedures and processes assigned to more junior staff. Also assume responsibility for all data management activities leading to database lock according to client quality expectations, within project timelines and budgets.
Associate Director, Data Science & Scientific Informatics - Merck, Salt Lake City UT USA
Scientists in the Data Science Realization Team (DSRT) within the Data Science and Scientific Informatics group develop techniques for quantitative analysis of multi-dimensional, multi-modal datasets, focused on both the acceleration of scientific and operational activities supporting drug development. The team considers a wide range of data types, including genomic, imaging, high & low-throughput assays, and unstructured data, as well as numerous modalities within each. The DSRT is dedicated to solving high-impact, high-priority issues using any of the most appropriate tools and methods available, and thus will require a broad perspective to problem-solving, with a strong collaborative network to leverage deep expertise throughout the company.
Research Computing Manager - Cranfield University, Cranfield UK
We are recruiting a Research Computing Manager to lead a small team of technical specialists to deliver highly available, scalable and effective HPC services supporting 1,600 staff and 4,500 students. We are seeking experience of building, managing and maintaining highly available and performant HPC systems requiring in-depth knowledge of advanced IT Infrastructure, compute and storage technologies and research applications.
High Performance Computing Operations Lead - Commonwealth of Australia, Bureau of Meteorology, Melbourne VIC AU
The High Performance Computing Operations (HPC Ops) team is a member of the HPC Services section within the SIM, with the responsibility of providing operational support for the Bureau’s High Performance Computers. Our goal is to ensure that the HPC systems are supported, monitored operationally 24x7 to ensure maximum uptime. HPC Ops also plays a role in defining, delivering, and implementing future high performance computing platforms as part of the lifecycle management framework with an efficient, modern, high-quality, and secure approach
Senior Director-Knowledge, Data Analytics and Insights - Canadian Red Cross, Ottawa ON CA
You are a senior leader known for creating insights, trends and reflections from program evaluations, research and industry trends and effectively packaging and disseminating that knowledge for use with senior management and the Board, the organization more broadly, and partners and clients, as appropriate. You are an effective communicator who can partner with operational and support services stakeholders to create data platforms and tools. You can lead a team of analysts and technicians to operationalize the organizations knowledge visions and deliver value. You have experience in program evaluations, research, developing parameters for capturing and searching data as well as current state analytics and data mining tools.
Deputy Director, High Performance Computing - Mississippi State University, Starkville MS USA
The Deputy Director, High Performance Computing at the Mississippi State University (MSU) High Performance Computing Collaboratory (HPC2) will establish a synergistic interaction with the current Director of HPC2 to contribute to strategic decisions regarding the deployment of and investment in high performance computing. The Deputy Director will identify priorities for maintenance and growth, outline technical strategies and oversee a highly motivated staff. The Deputy Director will also oversee high performance computing support functions to include IT network support, facility maintenance, property control, web development and cybersecurity. The Deputy Director will support the Director in identifying, engaging, and supporting the needs of faculty, postdoctoral researchers, and graduate students to ensure projects related to their research are successful.
Lead, Cloud HPC Software Engineer - NOAA OMS NCCF - L3Harris, Suitland MD USA
Experienced software engineer to assist in the sustainment and modernization of NOAA ground systems on an existing cloud infrastructure for a new NOAA/NESDIS contract award. The project requires on-site support at a NOAA facility located in Suitland, MD. The position requires prior experience responding to break fixes to support cloud operations. The position will function as a part of a cloud sustainment team to complete approved sustainment tasks in compliance with system engineering, sustainment and quality plans meeting operational availability. The position contributes in the development of programming solutions, software system test procedures, training and documentation updates. The cloud services include, but are not limited to: Data Ingest, Product Generation (PG), Product Distribution (PD), data storage, and data stewardship.
Research Computing - Associate Director of User Services - University of Colorado at Boulder, Boulder CO USA
The Associate Director will work closely with the Research Computing team and its stakeholders to identify and implement services meant to promote the most effective opportunities for researchers to conduct their research. This position will also serve as Product Owner of the Research Computing Agile team, and will also hold the position of Initiative Director of Education and Training in the Center for Research Data and Digital Scholarship (CRDDS). The Associate Director will be expected to provide advanced level consultation and training support to researchers as needed and will lead a management team to assist in the implementation of these efforts.
Team Lead, Research Software Development - Simon Fraser University, Burnaby BC CA
The Lead, Research Software Development will lead a lean team of software developers and program analysts responsible for supporting the development, implementation, and evaluation of research computing applications at Simon Fraser University. This team, comprised of technical specialists, will work closely with individual researchers and research groups to design and implement solutions to specific computing needs while also providing general education and outreach to researchers from all disciplines across the University about the tools available to support and enhance their research activities. The role will also liaise with partners (other universities and research software entities), report on team activities, define and build a sound business model for sustainability of the unit, and support related institutional initiatives.