Research Computing Teams Link Roundup, 16 July 2021
Hi, everyone:
I hope you're doing well.
I’ve neglected the “managing your own career” section lately, which I'm going to try to fix; we spend a lot of time here talking about helping our team members develop their skills, which is good and we certainly have an important role to play there, but we have to look after our own careers as well. Luckily in the past week several very relevant articles have crossed my browser, and so I present for you this week an attempt to bring that back into balance a bit.
Are there particular things you're doing to track your own career progress, or get ready for future next steps? Are their particular gaps you're not sure how to address or questions about how to progress? Please feel free to email me at jonathan@researchcomputingteams.org or just hit reply, and I'll answer as best as I can and with your permission ask the newsletter readership to chime in, too.
For now, on to the roundup:
Managing Teams
A Manager’s Guide to Holding Your Team Accountable - Dave Bailey
A lot of research computing team managers - especially those of us who came up through the research side - aren’t great at holding the team accountable. It’s pretty easy to understand why - the whole idea of being accountable for timeline and scope is a bit of an awkward fit to that world. Something took longer than expected, or someone took a different tack than they had committed to earlier? I mean, it’s research, right? If we already knew how to things were going to go ahead of time, it wouldn’t have been research.
But supporting research with computing and data is a different set of activities, and to give researchers the support they need we need to hold team members accountable for their work, and team members need to hold each other - and you - accountable. Mutual accountability is what separates a team from a bunch of people who just happen to have similar email addresses.
So going from a role in one world to one in the other takes some getting used to. It’s easy, as Bailey reminds us, for accountability conversations to feel confrontational - maybe especially to the person starting the conversation. But he summarizes our role as:
- Asking probing questions about what happened
- Clarify [our] report’s explicit and implicit commitments
- Deliver feedback clearly and constructively
In particular, he distinguishes between “holding someone to account” and “giving feedback”. Holding someone to account involves clarifying the expectations and asking probing questions about what happened; giving feedback means providing your reaction about what has unfolded.
There are familiar points here for longtime readers - Bailey includes discussion of the Situation Behaviour Impact (SBI) feedback model - but distinguishing between holding to account and feedback is useful and new, and the article is worth reading. Bailey also gives a helpful list of probing questions:
- What were you trying to achieve?
- What was your plan?
- What options did you consider?
- What drove your decision?
- What actually happened?
- How did you react?
- When did this happen?
- What did you learn?
- What would you do differently?
As well as some starting points for accountability conversations.
Secret tips for effective startup hiring and recruiting - Jade Rubick
How do you identify great engineers when hiring? - Yenny Cheung, LeadDev
These articles read together give a sense of what a really good hiring process could look like. Rubrick’s article starts well before the job ad goes out, and continues well past the hiring of any one candidate; it’s about strategy pipeline, and iterating. But it’s intended to quite a wide audience, so doesn’t go into the details of interviewing for a particular type of role, which is where Cheung’s steps in.
Rubick’s article starts very early on in the process. What is your hiring strategy? Why should someone work on your team as opposed to any of the other myriad of opportunities out there? What does your team offer, what can you be flexible enough or emphasize? A clear and well articulated set of reasons and benefits here can be used in a number of places - your careers page, how you recruit, where you post ads, and more.
Rubrick then recommends putting real thought into the job description and ad, testing the application process to see what it looks like, (he also has a nice article on creating an interview plan), and moving quickly.
A great idea I haven’t seen anywhere else is to start assembling useful information for candidates - like an FAQ, and which can be added to with real candidate questions - and when it’s big enough to be useful, to begin sending it to candidates as part of the process once they get through the resume screen stage. He also recommends giving feedback to and asking for feedback from candidates, keeping in touch with promising candidates, and actively recruiting based on everyone’s network.
Cheung’s article goes into the process of interviewing. She starts with some basics, like having clear expectations up front; having gone through the resume and detail and mining for questions; and staying away from hypothetical questions (I can’t agree with this enough; either have them do the thing and evaluate it, or ask them how they have done the thing in the past, don’t ask them to just make up how they might do the thing).
The secret sauce, in her estimation (and again, I strongly agree) is in the followup questions. If you’re not digging deeply into the answers with more questions, you might as well just have people email in their responses. Digging deep into the whats and hows is how you get the information you need to evaluate the candidate.
Managing Your Own Career
Dropbox Engineering Career Framework - Dropbox
We’ve talked a lot in the newsletter about career ladders, but it’s generally been for our team members - the path of increasing technical seniority. What about us? How do we know what skills we should be developing; how do we know if we’re making progress?
In our line of work career progression is slow and comes in fits and starts, but that doesn’t mean we can’t be levelling up our skills. Dropbox has an unusually clear engineering management ladder, starting with M3 (the link above) through a more senior (but still front-line) M4, through an M5 Lead-of-leads (Senior Manager), M6 (Director - manager of senior managers) and M7 Senior Director. It has plain language descriptions of what they expect to see - in terms of behaviours and outcomes - for leaders at each level.
Areas covered are the big picture scope/collaborative reach/impact levers (how you get things done), Results, Direction, Talent, and Culture.
Do those line up with what you’d expect a research computing manager to be or aspire to? What are the biggest gaps?
Writing is Networking for Introverts - Byrne Hobart
This is an older (2019) article that recently started circulating again, and I really like it.
Relationships are a key part of being an effective leader, and for building your career. Trust speeds collaboration, and we trust people we already know and have interacted with.
Increase the circle of people who trust you (and you trust) so you can have more effective and frequent collaborations requires building your relationship network. “Networking” has come to sound like a suspiciously disreputable process, especially to people like us in research, but it needn’t be. Meeting and interacting with other people who share our interests, and in doing so building professional relationships, is a good and healthy thing.
It’s also super hard to start doing if you’re an introvert, which many of us at the intersection of research + computing are.
Hobart encourages those of us who find in-person networking uncomfortable to think of writing as a way to build our professional network; as he points out,
- You don’t have to introduce yourself to anyone.
- You don’t have to conversationally grope around for something to talk about.
- Your conversational partners are pre-selected for having shared obscure interests.
As an example, you might want to start a blog or a newsletter. You know, hypothetically.
I’d add that in our work, giving a talks at conferences is another great way to speed networking for introverts. Once you’ve given a talk the rest of the mingling events at the conference are way easier to navigate. People come to you to ask questions about something you were interested enough in to give a talk about.
Timeboxing: The Most Powerful Time Management Technique You’re Probably Not Using - Nir Eyal
I’m a little surprised to see that timeboxing hasn’t come up on the newsletter as often as I would have thought - it was one suggested strategy out of five in one article we covered in #53. It’s a very useful technique for making sure you get things done, and for scoping those things.
Problem with a to-do list include:
- Many of us aren’t great at breaking down the to-do items into discrete-enough chunks, so there’s a lot of open scope
- It doesn’t help deal with distractions
- There’s always more stuff on the todo list, so at the end of the day you feel like you haven’t done enough.
Timeboxing involves actually blocking off time on your calendar to do certain tasks - or classes of tasks, and assigning items to any particular box. It’s great because it actually schedules you to do task X in an hour on Tuesday afternoon, meaning you’ve scoped it better than just a bullet point saying “X”, and by committing to that you’re less likely to be distracted during that hour.
Eyal cautions us to:
- start small,
- iterating to get it right,
- sticking to the schedule - if something came up and you didn’t do X, follow the schedule anyway and do Y next
- learn what works for you.
Research Software Development
Easy Guide to Remote Pair Programming - Adrian Bolboacă, InfoQ
Bolboacă walks us through the how and why of remote pair programming, and InfoQ helpfully provides key takeaways (quoted verbatim below):
- Remote pair programming can be an extremely powerful tool if implemented well, in the context where it fits.
- You need to assess your current organization, technical context, and the time needed to absorb change before rushing into using remote pair programming. There are useful sets of questions for that.
- Social programming means learning easier together, pair programming is a form of social programming, and ensemble programming (also known as mob programming) is another form of social programming.
- Tooling is important when using remote pair programming, and you can learn how to make the experience great, depending on your context.
- Remote pair programming doesn’t work everywhere, and we need to understand and accept that not everyone likes pairing.
The points that stand out to me is that pair programming isn’t a good thing in and of itself, it’s a practice that can help you achieve specific good things; and you’re more likely to achieve the good things you want if you keep the goals in mind. Maybe it’s knowledge transfer and mentoring juniors, or a second pair of eyes on some particularly sensitive code, or being faster than waiting for a code review on a PR. Those are all great objectives, but they’re different, and how you roll it out the practice will affect how well those objectives are met.
Bolboacă also highlights areas where it’s not likely to work well:
- Very soliary developers
- It’s not supported by the organizaiton
- It’s introduced in a rush
- It’s used on simple tasks
FAIR is not the end goal - Daniel S. Katz
FAIR - Findable, Accessible, Interoperable, Reusable - is a term of art in research data, expressing requirements for how to make the data useful. There are a few talks and write-ups on "FAIR for software” out there, but as Katz points out, code is different than data; we want to be able to successfully use it, build upon it; it decays without maintenance in a way data doesn’t, and it should be robust for use in different situations.
We could stretch the Reusable definition a great deal from where it’s useful in data to where it’s meaningful in software, but at that point it starts to look so different, what’s the point?
Katz also thinks software (but not data??) should be citable and credit given to contributors.
The Developer Certificate of Origin is Not a Contributor License Agreement - Kyle E. Mitchell
There’s been some discussion lately of a “developer certificate of origin”, where a developer asserts where the code comes from and that they are able to grant a license to the project. It’s a simpler document, and avoids the more complicated contributor license agreement approach, so it’s attractive for small open source projects.
Unfortunately, as Mitchell points out, it falls short in not actually granting an explicit license, which greatly limits what the open source project can do with it. Maybe that’s good for your project, but it would hugely complicate re-licensing the project, even to an updated version of the same license (e.g. GPL 2→3).
Research Data Management and Analysis
Introducing PyTorch-Ignite's Code Generator v0.2.0 - Victor Fomin, Quansight Labs
PyTorch Ignite, which just came had an 0.4.5 release, is a high-level library for the PyTorch - think Keras for Tensorflow, but newer (and so less mature).
Even with such libraries, for a lot of common workflows - computer vision or text classification - there is common boilerplate that fly off the fingers of those experienced in the field but that are a barrier to those getting started. Ignite Code Generator doesn’t really generate code so much as provide a set of templated starting points - think cookiecutter or similar templates - that let you set file prefixes, iterations and stopping points, checkpointing, logging, etc.
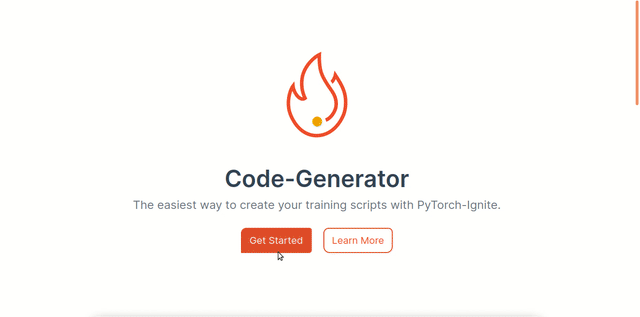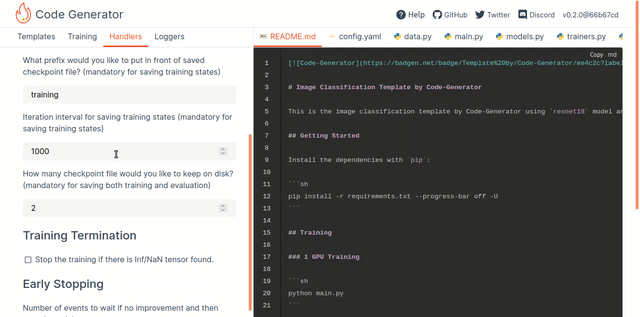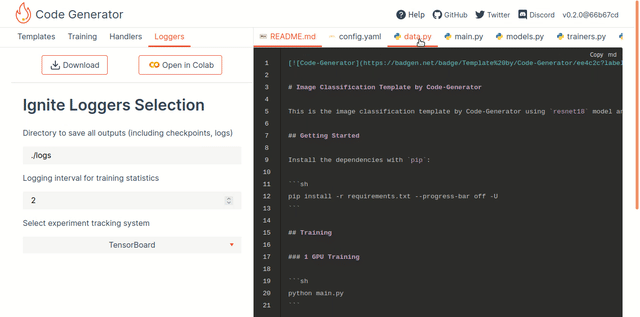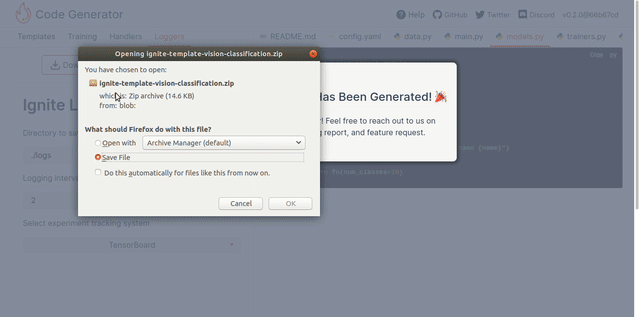
To be clear, my comparison with cookiecutter is meant as positive - these ready-to-go workflows are both extremely valuable and relatively easy to contribute (and to the Quantsight team’s credit they set up an extremely helpful contributing guide right from the start). Any effort which helps improve a research computing team’s productivity by reducing toil and tedium while increasing knowledge sharing is an effort I’m likely to support.
From Data Processes to Data Products: Knowledge Infrastructures in Astronomy - Christine L. Borgman and Morgan F. Wofford, Harvard Data Science Review
I’ve been thinking for a while that to get really complete description of a process involving people, you sometimes need to enlist an outsider, or find someone who’s very new to the process and the ecosystem it’s embedded in. Otherwise you end up with a situation like having children explain to a pretend robot how to make a peanut butter sandwich; steps that are “obvious” or so important as to seemingly go without saying just get omitted.
A couple of careers ago I was in astrophysics; observational astronomy has a long history with data and data sharing, and so I read this paper by Borgman and Wofford at the UCLA Centre for Knowledge Infrastructures with some interest. Actually - and I’m not proud of this - I read it with some initial skepticism of “outsiders” reporting on how astronomy groups handle data. But it’s a great overview, and I recommend it to others who aren’t in the field (or haven't been for a while) who want to know how modern astroinformatics is done, current data practices, products, and infrastructure with the examples of a large project (the Sloan Digital Sky Survey) and two smaller pseudonymous groups.
Astronomy has a lot of advantages over other fields - a single 2-d sky (although there were bitter fights ending only fairly recently to get everyone to agree to a common coordinate system) to study at various wavelengths, no privacy concerns, and relatively common and structured file formats (although again the file formats were not an easy battle for the community). Even so there are a lot of challenges that practitioners will find familiar; the multiple roles of participants, both of which are pretty important, but only one provides recognition:
each member of the group has two roles: “one as a pretty independent scientist...and then [as] support [for] the general, larger project of the group…”
the issues of funding those maintenance and support activities:
“[Maintenance] tends not to be addressed, and it’s boring. ... at some point you have to do it, you have to paint your house, you have to have the roof replaced, it’ll happen to every house. ... it would be really great if the agencies would say, ‘Okay, we need to put money into keeping these going. What are your maintenance needs for the next three years?’ ...[eventually] you’re on a legacy platform that isn’t supported anymore, or that has security holes a mile wide....”
the more general issues with funding long-term products (including archival data storage) with project-based funding:
Multiple commitments to house and maintain the data “all have finite lifetimes, and [they] haven’t figured out what to do after the lifetime ends”
It’s also interesting to see how far things have come over quite recent periods of time. The Sloan Digital Sky Survey started in ~2000, and - I had forgotten about this - it initially relied on proprietary software in their analysis pipelines, something that would be completely unthinkable for a major project starting today.
The paper ends with some recommendations, including (paraphrased):
- Funders should distinguish between knowledge production (papers) and open data release tasks, and fund both
- Invest in data sources that have long-term value
- Fund software maintenance
- “More investment in the staff who sustain the knowledge infrastructures that make science possible” - a refrain everyone reading likely agrees with.
Research Computing Systems
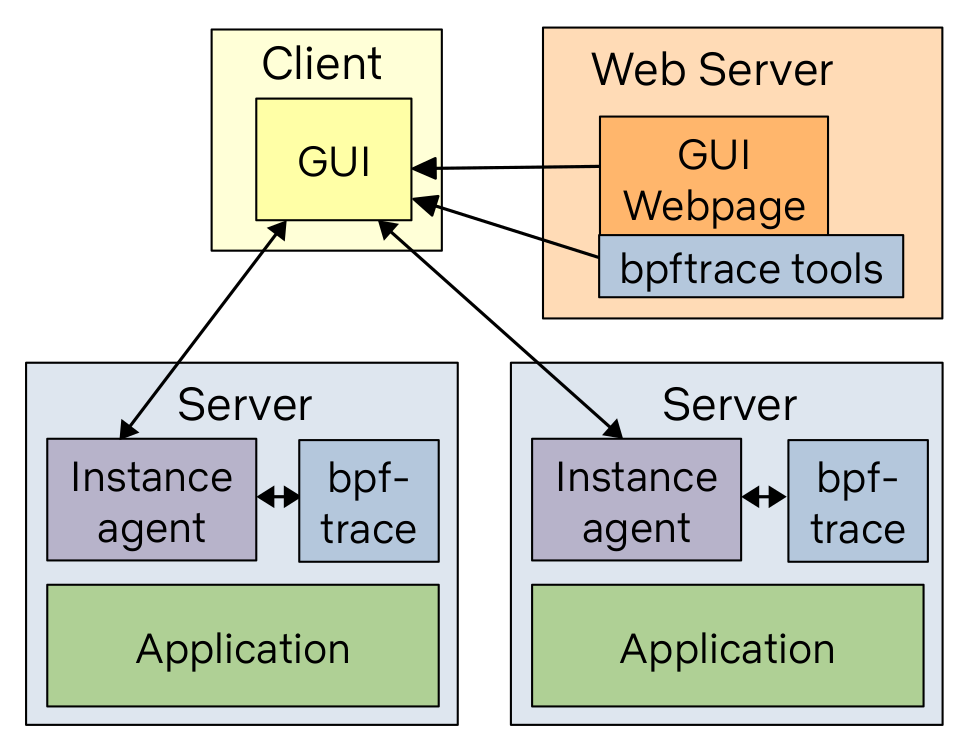
How To Add eBPF Observability To Your Product - Brendan Gregg
If you contribute to or maintain system monitoring software - and many systems teams do - this primer walks through the process of adding simple existing eBPF functionality - the example here is execsnoop, for reporting new processes by tracing execve() system calls - into your existing tools, along with giving suggestions for other tools and how best to visualize their results.
Emerging Technologies and Practices
How the FPGA Can Take on CPU and NPU Engines and Win - Timothy Prickett Morgan
I’ve been doing this stuff for a while - 25 years now? Depends on what you count - and have been assured for most of that time that the age of FPGAs for general research computing was just around the corner.
As communities are gaining more and more comfort with dealing with different kinds of accelerators though and more diverse CPUs, handling the complexity of FPGAs starts to seem less farfetched than it did back in the day when Sun workstations and SGI boxes roamed the earth.
Morgan walks us through the recent history and the current state of FPGAs, looking at a particular vendor’s product (Xilinx’s upcoming Versal units) as a concrete example. With increasingly large numbers of complex “hard blocks” (I/O controllers, cryptographic engines, ports, etc) already supplied on-socket, there are more batteries included then there used to be - and with high bandwidth memory and fast interconnects available, sending enough data to the FPGA to be worth the effort of crunching on it there seems increasingly plausible.
Programming these devices remains challenging, and that is going to be the bottleneck - but as we saw with “GPGPUs” back in the day, once the devices get powerful enough, some pioneering research computing teams will start doing it successfully and showing others a path towards productive adoption.
Calls for Submissions
SIAM Conference on Parallel Processing for Scientific Computing (PP22) - 23-26 Feb, Submission 14 Sept for contributed lecture, 1 Oct for Proceedings
SIAM PP is a big conference for parallel computing in science, with topics ranging from compilers and programming systems to algorithms, simulation + ML, uncertainty quantification, reproducibility, tuning, and more. It’ll be held in-person in Seattle this year. Instructions for submissions can be found here.
Random
Phys. Rev. Fluids posted a thoughtful editorial policy on publishing machine learning papers - “We suggest that when ML is integrated in such efforts, there are at least three important aspects to address: (i) the physical content and interpretation of the result; (ii) the reproducibility of methods and results; and (iii) the validation and verification of models.”
In which someone on the internet says bad things about xargs, which is wonderful so he must be wrong.
An overview of DNS resource records - like A, CNAME, MX, etc. All 80 of them.
“In my day, we coded WebAssembly by hand”.
An argument that now, with webassembly, virtual file systems, GPU access, and raw TCP and UDP connections, the browser is the universal virtual machine which finally lives up to the promise.
CBL-Mariner, Microsoft’s internal Linux distribution (that is still so weird to type).
Writing your own Bash Builtin and loading it with “enable”. I don’t think I knew you could do that.
The seven different timers in curl and what they mean. Useful if you use curl to benchmark things or debug latencies.
Figuring out how mesh VPNs work by writing a simple one.
Cute visuals for explaining the various flavours of JOIN.
Examples of more realistic workflows for performing complex SQL queries using R.
A nice overview of Python 3.8’s protocol types, arguably formalizing an idea that’s been in Python since the beginning.
That’s it…
And that’s it for another week. Let me know what you thought, or if you have anything you’d like to share about the newsletter or management. Just email me or reply to this newsletter if you get it in your inbox.
Have a great weekend, and good luck in the coming week with your research computing team,
Jonathan
About This Newsletter
Research computing - the intertwined streams of software development, systems, data management and analysis - is much more than technology. It’s teams, it’s communities, it’s product management - it’s people. It’s also one of the most important ways we can be supporting science, scholarship, and R&D today.
So research computing teams are too important to research to be managed poorly. But no one teaches us how to be effective managers and leaders in academia. We have an advantage, though - working in research collaborations have taught us the advanced management skills, but not the basics.
This newsletter focusses on providing new and experienced research computing and data managers the tools they need to be good managers without the stress, and to help their teams achieve great results and grow their careers.
Jobs Leading Research Computing Teams
This week’s new-listing highlights are below; the full listing of 203 jobs is, as ever, available on the job board.
Manager, Cloud Research Architecture - Athabasca University, Athabasca AB CA
The Manager, Cloud Research Architecture will partner and provide technical advisement to the Associate Vice President, Research in the IDEA Pilot: Athabasca University's Virtual Research Domain and work closely with AU's strategic collaborations team at AWS. The Manager, Cloud Research Architecture, oversees cloud research architecture for both infrastructure and applications, designing, developing, and communicating processes, tools, and standards with the Cloud Architects, Cloud Systems Administrators: Architecture, DevSecOps, Security and Cloud Systems Technicians and helping to define and implement DevSecOps methods and practices.
Lab Manager - EMBL Heidelberg, Heidelberg DE
EMBL is seeking to recruit a Lab Manager in the Structural and Computational Biology Unit at EMBL Heidelberg. The position is available in the group of the Head of the Unit, Dr. Christoph W. Müller. Interests of the group are mechanisms of transcriptional regulation in eukaryotes. A particular focus of the group is the structural biology of transcription complexes. The group uses cryo-EM as principal technique combined with other structural, biochemical and biophysical approaches. The Lab Manager will be involved in the production, biochemical and biophysical characterization of proteins and protein complexes, as well as the overall organization of the laboratory.
Responsible AI Senior Manager - Accenture, London UK
At the forefront of the industry, you’ll create, own and make it a reality for clients looking to better serve their connected customers and operate always-on enterprises. We are not just focused on increasing revenues – our technologies and innovations are making millions of lives easier and more comfortable. Join us and become an integral part of our Applied Intelligence team with the credibility, expertise and insight clients depend on. There will never be a typical day at Accenture, but that’s why people love it here. You will be working with famous brands and household names – no worrying about how to explain what you do to your family again!
Strategic Research Computing Director - Oregon Health & Science University, Portland OR USA
This position is responsible for providing leadership on strategic research computing with a focus on key collaboration, future initiatives and architecture for the OHSU HPC Cluster. To do this they will need to build a strong collaboration between the research computing community and Information Technology Group (ITG) to ensure that funds and technology architecture are effectively utilized and planned for in order to support research computing at OHSU. This position must work with all levels of the organization, including Vice Presidents, Administrators, Department Directors, Managers, Faculty and Staff, working specifically with the CRIO, CHIO, RDA directors, and members of the Exacloud Steering Committee and Informatics Governance Group, in which they will hold memberships. This position will work with vendors on design, development and implementation of research computing applications and hardware for multiple technical platforms.
Senior Research Software Engineer - UK Atomic Energy Authority, Culham UK
Acting as the RSE lead on significant projects and other activities (including supervising the work of others). Forming strong partnerships with domain experts and project managers to make sure aims are understood and achieved and successful collaborative development is established. You would contribute to the success of our world-leading programmes including STEP (Spherical Tokamak for Energy Production) which aims to establish a pathway to supply net energy by the early 2040s. Upcoming projects include: work on software for plasma modelling, engineering design for future fusion reactors, and control systems for experiments and robotics. We are particularly keen to hear from people with expertise in: C++ (including hardware interaction / control systems), experience of engineering design workflows and tools, or improving portability and integration of existing research software, eg through containerisation.
Senior Research Computing Systems Engineer - University of Southampton, Southampton UK
This is a key role in support of the research being carried out using the University of Southampton’s High Performance and Data Intensive Computing (HPDIC) facilities. Following a recent restructure you will be joining a team of dedicated research computing engineers who are supporting the current systems and their use in a diverse range of research topics from Quantum Chemistry simulations and AI modeling to Climate modelling, medical imaging and COVID-19 research. We are currently planning for a refresh of the facilities and this role will play a key role in supporting the planned and commissioning process. Take a leading role in delivering and maintaining the University’s High Performance and Data Intensive Computing facilities. Take a leading role in the planning of major systems installations and upgrades. Deliver training programmes to research students and mentor colleagues.
Senior Research Software Engineer - The University of Sheffield, Sheffield UK
The role is ideal for someone with a passion for research software looking to lead a team to drive collaborative software development and reproducible research to make an impact on research projects across the whole of the University of Sheffield. We are looking for applicants who are highly passionate about reproducible research through development of robust software and are committed to advocating software best practice through engagement with the academic community. A key responsibility of the role will be to advocate the RSE group within the academic community to strengthen the provision of RSE support including collaborative working and facilitation of training. Applicants should have extensive experience of collaborative software development and an appreciation of how to work with academics and researchers to specify, develop, improve and deliver research software.
Scientific Team Leaders - NOMAD project, HU Berlin, Berlin DE
Coordinate one of the project teams in the NOMAD HUB (NOMAD Data Center at HU Berlin). Lead a small cross-functional team. Be responsible for setting up and delivering internal milestones, providing regular progress reports. Represent the project at national and international conferences, workshops, and in scientific publications. Frequently travel and coordinate activities with partner institutions. Occasionally work at different project partners
Scientific Project Manager - NOMAD projectHU Berlin, Berlin DE
Lead multiple interdisciplinary teams. Assistance in all areas of the project, including software developments for synthesis, theory and experimental data management, as well as digital infrastructure. Responsible for setting up and delivering internal milestones, providing regular progress reports. Represent the project in national and international conferences, workshops and scientific publications. Frequently travel and coordinate activities with partner institutes
Contribute to third-party funding acquisition
CIRES/ EARTH LAB PyOpenSci-Community Manager and Developer Advocate - University of Colorado Boulder, Boulder CO USA
Earth Lab at the University of Colorado, Boulder is encouraging applications for a Community Manager and Developer Advocate to facilitate the creation of an inclusive pyOpenSci community that is dedicated to high-quality Python open source software that supports open science workflows. pyOpenSci promotes the development of open, peer-reviewed, standardized, well-documented, discoverable software for working with scientific data. pyOpenSci also builds capacity to contribute to open source software through outreach, training and mentorship. pyOpenSci will strive to increase participation of groups that have been traditionally underrepresented if not missing from the open source community through both mentorship and strategic partnerships with existing organizations such as pyLadies, geoLatinas, and others.
Director of Engineering, Clinical Workflows - flatiron, New York NY USA
In this role, you will lead an initiative of six engineering teams to equip physicians with the information and tools to deliver high quality care to America's oncology patients. Reporting to the Head of HC Engineering, you will provide technical management and guidance while working cross functionally to set the direction of the business line. In addition, you will also:
AbbVie - Manager - Data Science, Lake County IL USA
Abbvie’s OBI group is looking for Manager, Data Science responsible to define, manage and build a scalable Business intelligence and Data Science platform and solutions that will enable business process metrics and advanced analytics for Operations. The individual will be in involved in actively managing and contributing to a high performing team of data scientists and engineers who are building the foundational pillars of advanced machine learning solutions to solve some of the most relevant business problems. The candidates strong data science background should include innovation in a robust experimentation framework that enables simultaneous testing of multiple levers – timing, cadence, verbiage, channel etc. building core elements of NLP framework that enables real time intelligent conversations with business; recommendation engine that helps determine the next best action etc.
Technical Manager for High Performance Computing - Durham University, Durham UK
This role will be engaged with the continued operation of the DiRAC Memory Intensive service, both routine maintenance procedures and also research and development projects leading to new capabilities and facilities for both users and support staff. The applicant will liaise with DiRAC researchers in cosmology and other areas to understand their codes and develop expertise in the efficient running of these codes on HPC facilities, including some code development to optimise use with new hardware. The applicant will also work with other support staff and with the other DiRAC technical support teams to deliver an effective HPC service for users, including responding to user queries.
Director of Scientific IT - Excientia, Oxford UK
As the Director of Scientific IT you will be responsible for: Experience working in a senior operational IT role, The ability to define and agree strategic roadmaps in co-operation with vendors and business stakeholders, Experience co-ordinating application awareness training, either directly or through managing that function, Able to co-ordinate within a multi-disciplinary team to define and meet agreed deliverables, The ability to deliver in a hands-on role whilst enabling an environment that allows you to move to a more strategic position
Product Manager - Pipelines Delivery - Bioinformatics Delivery - Genomics England, London UK
We're looking for someone who can help run our genome analysis pipeline product, which is a key component of the Genomic Medicine Service, which is a live service run in partnership with the NHS. The product utilises cutting-edge genomics techniques to analyse genomes and provide insights on diagnosis, prognosis and therapeutic outcomes for patients. Some of the problems to solve in this area will require you to work collaboratively with users and inject more innovation to the methods we use. For example, improving our algorithms using Machine Learning techniques. As a Product Manager here, you'll be the facilitator of the products we build. This is an opportunity for you to combine your communication, leadership, pipelining and defining skills to take responsibility for our groundbreaking scientific products that will directly impact the advances of personalised genomic medicines in the UK.
Senior Scientific Manager - DNA Pipelines - Wellcome Sanger Institute, Hinxton UK
You will be responsible for managing one of the DNAP core operational teams, ensuring that the team provides high quality leading edge services to support the changing scientific and capacity requirements of the Wellcome Sanger Institute. You will lead and manage a diverse operational team to ensure that they provide a customer focused, timely, high quality service to our faculty groups, external stakeholders and third parties. You will develop & maintain close and effective working relationships other DNAP teams, DNAP Technical Development and faculty groups to improve operations and be a key driving force to ensure continuous improvement and the deployment of new pipelines into operations smoothly.
Data Science Manager - Mozilla, remote CA or remote US
As a manager on the data science team, you will own a critical piece of the Mozilla organization. Data scientists work closely with our policy, legal, and business development teams to enable decisions and contribute insights that push our mission forward and in the right direction. They build models and design experiments that improve our understanding about the operation of our business and products to ensure that we are optimizing our decisions for maximum impact on the market. We are looking for an opinionated manager with technical chops who is excited to marshal a data science team to shape the future of the Web. You will manage a small team of data scientists and will be responsible for career mentorship and technical guidance. You will work with leadership to define and execute strategies that demonstrate the value of the data contributed by our users while maintaining an ethical set of principles to guide your practice.
Senior Software Project Manager- R&D - SCIEX, Vaughan ON CA
As a global leader in mass spectrometry, SCIEX delivers solutions for precision detection and quantification of molecules to help protect and advance the wellness and safety of all. You will play a meaningful role in driving software product development efforts spanning our software platform and vertical applications for our scientific analytical product lines. Our software projects follow Agile development methodologies and build products for MS-Windows and cloud-based systems. Some projects also integrate with hardware projects developing our Mass Spectrometer instruments and peripherals.
Director of Industry Engagement, Computing and Data Sciences, University Research - Boston University, Boston MA USA
In this newly created role reporting to the Associate Vice President, the Director of Industry Engagement, Computing and Data Sciences will be responsible for developing and implementing the University's Industry Engagement strategy for the Computing and Data Sciences industry vertical, creating meaningful and sustainable relationships with industry partners leading to increased investment in University priorities in alignment with corporate priorities.
Web & Interface App Lead Engineer - Ohio Supercomputer Center, The Ohio State University, Columbus OH USA
As the technical leader of the OSC Gateways Group, this position develops and supports "science gateways," web-based interfaces for advanced computational resources. The group supports specific gateways for OSC clients and projects and also contributes to the OSC-led open source project Open OnDemand deployed at more than 200 supercomputer centers worldwide. As the technical lead of the OSC Gateways Group, this position will: Help with center-wide goals and initiatives such as supporting the deployment of a new HPC cluster. Create and maintain Open OnDemand apps deployed at OSC (all open sourced at OSC's GitHub) like RStudio and Jupyter. Support classroom use of OSC's HPC resources.
Eukaryotic Annotation Team Leader - European Bioinformatics Institute, Hinxton UK
You will lead the Eukaryotic Annotation team comprising approximately 25 staff with a range of expertise (curators, bioinformaticians and software engineers). You will have strategic oversight for the gene annotation and comparative genomics components of Ensembl, and will work closely with other Team Leaders and senior staff at EMBL-EBI to develop overarching annotation strategy for Ensembl and other collaborating EMBL-EBI resources. You will also lead the EMBL-EBI contributions to WormBase and AGR, collaborating with partners and stakeholders both in the UK and internationally to develop both high-level scientific strategy and detailed technical strategy.