Research Computing Teams Link Roundup, 10 Sept 2021
Research computing and data is increasingly a single discipline, a single area of practice. It’s a complex one, too; one which includes the support of first tentative steps which themselves may be research activities, all the way through to production operations of routine infrastructure.
You can read more, or go straight on to the roundup.
There was a good discussion on twitter (it happens) about software as a facility, as a tool for enabling research rather than merely as a research output itself.
I think there’s truth to that, but that’s not the end state for all research computing and data efforts - nor should it be - and, crucially, it’s not all just about software.
I like to think about research computing and data support going from the testing out of early ideas as a proof of concept, supporting the development of prototypes, then the development of a product and, and outreach and community building around that, until finally it matures into the routine operations and maintenance of a piece of well-understood research infrastructure.

At each step, the fundamental question being asked is different:
- Proof of concept: “Will this even work?”
- Prototype: “Will this solve real problems?
- Product: “Will others find this useful?”
- Proven: “Will a community be able to depend on this?”
The questions being asked at each level are important to keep in mind, because they set priorities. Issues like “technical debt” are irrelevant distractions at stages 1 or 2, when the questions being asked are about whether or not this is even a useful approach. At stage 3, the biggest question is around building a community, identifying their needs, improving reliability, and navigating a path towards sustainability. Only at stage 4 do things like long-term maintainability and professional operations play a big role.
Not every effort will, or should, make it to the “proven infrastructure” readiness level. Most really innovative proofs of concept won’t pan out - they may just not work, or might be ahead of their time and require other components not ready yet. Learning and disseminating that information is useful. Many successful prototypes or products may be useful for generating new ideas, or useful for individual groups and their research, but be too specific to gain very widespread use; that’s still a success. Our job isn’t to get every tool to the infrastructure level, but to enable as much experimentation in the early stages as possible, and make sure that no unnecessary barriers stand in the way of tools’ evolution to wherever they’re going.
The other thing to notice about all of this is that technological readiness level applies not just to software, but to novel systems, new curated data resources - and increasingly, combinations of all the above. Research computing and data isn’t three silos - research software, research systems, and research data - and the highest impact tools we provide these days are combinations of two or all three. Science gateways, interactive exploration and analysis of provided datasets - these don’t fall into one of the three silos. The highest impact COVID computing efforts combined all of the above - rapid computation and analysis using novel tools of collected COVID data.
And it’s always been that way. Even though data, software and systems are converging ever closer in this software-defined and data-enabled era, it’s not new. Ever since the beginning, those providing research computing systems have also had to provide curated application software stacks, and the means for analyzing generated or input data. Research software developers have always had to consider the systems the code is to run on. Those curating data resources do so in order that the data can be explored and computed on.
For these integrated systems, keeping in mind the readiness level of the product is even more important. The complexity of the effort makes it even more important to keep in mind the key questions at each stage, and to get feedback and input. The wider the effort the easier it is to lose track of the big picture, and focus purely on internal technical criteria. It’s important to remember the question you’re trying to answer.
And now, the roundup…
Managing Teams
Let’s Discuss Attrition - Subbu Allamaraju
We’ve talked about people leaving before, and that post pandemic such departures will rise. Allamaraju reminds us that this is good and healthy and not to freak out:
- Attrition is natural
- Reasons for attrition vary
- Attrition is an output - you can only control the inputs
In my team we do a relatively good job of celebrating new opportunities for team members where they go. This is one of the things academia I think does right - recognize that people moving on is just part of their career development. We pretty actively stay in touch - so much we may get our first boomerang team member this year if we play our cards right!
But Allamaraju makes another good point, and one which I don't see called out very often:
Every exit gives you, the manager, an opportunity to improve the team structure and dynamics. Attrition loosens the team fabric and gives you a chance to reshape it. Don’t let go of that opportunity.
The departure of even a valued high-performing team member is an opportunity to grow the team in new directions.
The culture of process - Cate Huston
The defining transition between hobbyist and professional, between someone in research who codes a little or does a bit of sysadminning and running a professional team providing research computing and data services, is that you no longer just focus on mean quality but also variance. You’re no longer trying to just get good results, but consistently good results. That means, painful though it might be, introducing some process.
Huston has a few ways to think about process as, frankly, a fabric connecting the team members:
- Process as an agreement about how we work.
- Process as a way to answer questions.
- Process as (documented) culture.
and this suggests a starting point for process - documenting how the team does things, ideally after some discussion, so that as new people join they can get up to speed quickly.
But as a team grows or its needs change, process can’t stay rigid - agreements shift, different questions are asked, culture updates. New processes may need to be created, and old ones retired, ideally after discussion. Huston describes changes to processes in her team - growing the hiring process of a team, trying “process experiments” on a team (and tossing out the ones that didn’t work), and building support for change. She also points out that any process change is going to get a mix of obliging and enthusiastic support, and questioning and out-of-hand disagreement. I don’t know if it’s useful to think of that in terms of personality types, but certainly accepting that any process change will lead to a variety of reactions is important.
Towards the end, Huston emphasizes that with process - as with technical decision logs! - it’s important to explain the why. That helps build agreement, and helps make it clear when it’s time for a process to be updated or retired.
9 metrics to help you understand (and prioritize) DEI - Kat Boogaard, Culture Amp
Every job posting in academic or academic-adjacent institutions has some boilerplate about the importance of equity, diversity, and inclusion. But research computing and data is worse than both academic research and tech when it comes to any kind of representation.
We’re scientists, and we fix things by collecting data and then performing experiments to see what makes the measurements improve. Boogaard suggests nine metrics to find out where you are and where you’re going, in three broad categories - the employee “lifecycle”, the employee experience while they’re with you, and company makeup.
Employee “lifecycle”
- Hiring - diversity of applicant pool and hiring panel
- Representation - finding out where you stand now
- Retention - are you attracting diverse talent just to preferentially lose non-white men because of lack of support?
- Advancement - again, are you attracting diverse talent but only promoting some of the usual suspects?
Employee experience
- Job satisfaction and engagement - are there common threads between employees who aren’t happy and engaged?
- Employee resource group participation - if you have such resources, are they being underused?
- Accessibility - do all employees have the tools and resources they need?
Company makeup
- Leadership - does your leadership look like your organization?
- Suppliers - are EDI issues hiding in vendor relationships?
How Many People Can Someone Lead? - Pat Kua
Whenever I give my “Help! I’m a Research Computing Manager!” talk, this is a question I get. Kua here says 5–7 (I often say 7 ± 2), but says it depends and gives a very helpful list of things it depends on. It includes the obvious things (a more experienced team - individually and working collectively as a team - requires a little less of a manager/lead, so you could lead more of them; similarly a more experienced lead can lead a few more people).
But there are a couple of nice other points here. The basic idea is that the manager/lead has a finite time budget, and the more of it goes into other things, the fewer people they have the time to effectively manage. Some of the things he points to are:
- If the level of institutional bureaucracy is high - and for many of us, it is - then more time is spent on paperwork and administrative tasks, and so there is less time available to effectively manage or lead people
- Leadership scope/leadership roles - if you are not just responsible for the people but also coordinating project delivery and also technical leadership, (a) that’s an exhausting role and (b) you’re not going to be able to lead as many people effectively. (Personal note: it looks like we’ll be getting a technical project manager shortly for our team and I can’t even tell you how excited I am about it).
Managing Your Own Career
Ok. So, You Can’t Decide - Michael Lopp
Sometimes you just can’t decide. Lopp’s experience is that this is from one of two causes:
- There’s something you know in the back of your mind that you need to find out first, or:
- You just need to suck it up, take the plunge, and decide
I think those of us who came up from academia are more often stuck in the second case than the first. There’s always one more thing you can read! But at some point you just need to decide.
Product Management and Working with Research Communities
Making World-class Docs Takes Effort - Daniel Stenberg
Documentation is incredibly important for a product’s adoption and use - whether the tool is software, data products, systems, or (increasingly) a combination of the three. It takes a lot of work, but that work pays off later with more adoption and less support effort per user.
Stenberg highlights what he’s found to be important for documentation: that it be:
- Stored with the code, for convenience and so updates are kept in sync, but
- Not generated from the code
- Filled with as many examples as possible
- Documenting every interface
- Easily accessible and browsed, and
- Easy to contribute to.
Stenberg then describes work he’s doing to improve the documentation of curl/libcurl, including constantly iterating, adding examples, and generating some simple automated checks for consistency and making sure cross-references stay current.
Research Software Development
Demo-driven development - Jade Rubick
From earlier in the year - Rubick describes his method for introducing stories and planning into software development, by starting with routine demos, backing from that into introduction of user stories by structuring the plans for the next demo, and then from there moving out into routine planning. What’s nice about this is that it keeps the important thing - always be delivering something useful - in the forefront.
Paranoid Scientist - Maxwell Shinn
Research software is subtle, and correctness issues can be fiendishly tricky to track down. I’ve spoken fondly of languages like Ada (e.g. #64), with contracts at function level, and formal methods (e.g. #46) for proofs that a routine correctly implements a function. Having such functionality available - preferably in a way that can be turned on and off and implemented incrementally, focussing on the most subtle and error prone parts of the code - could be extremely useful in research software development.
Shinn’s package, Paranoid Scientist (GitHub, preprint, tutorial), is a package for Python code which lets the developer create pre- and post-condition contracts for functions, enable or disable checking them at runtime (at about a 2x runtime penalty when enabled), and run a property-based test suite (e.g. #56) which automatically generates unit test cases against the post-conditions.
Why Every Software Engineering Interview Should Include Ops Questions - Charity Majors
Are Dockerfiles good enough? - Mathew Duggan
As I mentioned at the start, the line between “software” and “systems” is as fuzzy as it’s ever been. In any area of research software, a developer needs to think about how their software will be deployed, operated, updated, and maintained, even if it’s not hosted software. And if it is going to be hosted software, then operability is at least as important as code quality in terms of its impact on the team.
It’s not unusual to ask scripting/software questions to sysadmin/operations candidates, and Majors pushes us to including operations questions when interviewing software developer candidates. Some are particularly relevant even for non-hosted software:
- “What are some of your favorite tools for visibility, instrumentation, and debugging?
- “What’s your favorite API (or database, or language) and why?” followed up by “… and what are the worst things about it?”
In the second, Duggan points out that Dockerfiles - not containers, not even Docker, but Dockerfiles - are written by and for developers, and so they have a tendency to make assumptions that make sense to developers but cause operations teams unnecessary pain. Some common issues Duggan call out are:
- Reproducibility issues:
- FROM: [whatever]:latest
- apt-get upgrade
- Embedded brittle shell scripts
- Build performance issues:
- Killing caching by copying/adding in local code before installing dependencies
- Security issues
- Secrets in ENV
- Installing random software from who-knows where
- Over-optimization:
- Obsessing about container sizes over what the ops team knows
- Being overly cute with terse code over readbility
Duggan recommends combinations of dockerfiles and reproducible tools like Ansible (over bash), using packer, or at the very least using a Dockerfile linter like hadolint.
Research Data Management and Analysis
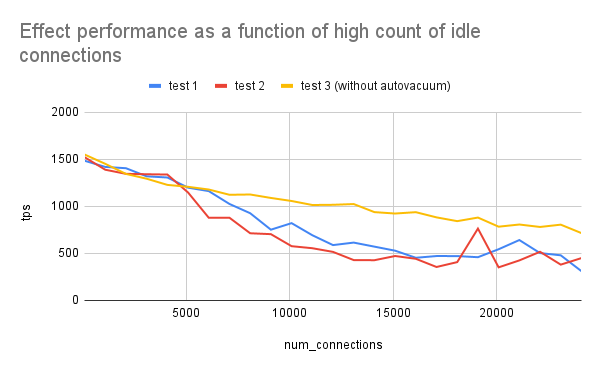
When Less is More: Database Connection Scaling - Richard Yen
10 Cool SQL Optimisations That do not Depend on the Cost Model - Lukas Eder
A few performance issues to keep in mind with relational databases.
In the first, Yen reminds us that allowing large numbers of connections - even if they’re idle, or even if they’re not used! - can impact PostgreSQL (and many others) performance. The connection table entries take memory, they have to be monitored periodically which take linear time.
In the second, Eder gives a master class in SQL and areas where optimizations can always be made:
- Transitive Closure
- Impossible Predicates and Unneeded Table Accesses
- JOIN Elimination
- Removing “Silly” Predicates
- Projections in EXISTS Subqueries
- Predicate Merging
- Provably Empty Sets
- CHECK Constraints
- Unneeded Self JOIN
- Predicate Pushdown
SQL engines are very good at automatically identifying many but not all of these statically - particularly those involving joins, check constraints, or provably empty sets; so these are useful for knowing where to automatically rewrite, as well as just being a nice deep dive into practical relational algebra.
Facebook’s Golang Object Relational Mapper Moves to the Linux Foundation - Mike Melanson, the New Stack
New ORMs have been getting steadily more sophisticated. Here is a quick brief on Ent, Facebook’s Golang ORM that has just been contributed to the Linux Foundation. It relies on code generation (though will rely much less on that shortly, with Golang generics becoming standard), but is more notable for having quite sophisticated semantic relationships between entity types, and for having graph concepts built in so that one can implement simple (presumably not too deep) graph analyses on top of relational databases.
Research Computing Systems
The CXL Roadmap Opens Up the Memory Hierarchy - Timothy Prickett Morgan, The Next Platform
Morgan gives a state-of-play of CXL v2.0, a switched-fabric cache-coherent interconnect protocol over PCIe-5+ protocols, that has a set of functionality for I/O, cache, and memory - with cache and memory optimized for latencies comparable to larger caches, and I/O targeted more at bandwidth (and is closest to native PCIe). It will be competing with, amongst other things, IBM’s OpenCAPI.

Where I’m most excited about this is allowing a common interface to a deeper memory hierarchy, including off-node memory and devices with different bandwidth/latency tradeoffs. The desegregated composable infrastructure stuff is cool too, but that’s mainly an efficiency play. I’ve been dusting off out-of-core memory algorithm papers since NVMe started playing a big role, and I’m more interested in the range of new capabilities that this could allow.
Emerging Technologies and Practices
Introducing AWS ParallelCluster 3 - Brendan Bouffler & Rye Robinson
CFD Direct From The Cloud v9 Released - CFD Direct
A couple of interesting HPC-in-the-cloud items:
AWS Parallel Cluster 3 is a complete rearchitecting of AWS’s HPC-cluster-as-a-service tool. I haven’t tried it yet, but Parallel Cluster 2 had a surprising number of sharp edges to it, so I’m anxious to try this one. The big outwardly-visible changes are a new API and updates to the CLI, for much more flexible control; a tool for custom VM images; much improved network configurations; better permissioning; and customization scripts at runtime for compute nodes.
I’ve seen a number of “HPC cluster in the cloud” projects which are terraform scripts or whatever which faithfully implement an on-prem static cluster on more expensive, software-defined infrastructure - and, not to put too fine a point on it, it’s utter lunacy. On-prem clusters are designed that way for a reason, the design has trade-offs, and those trade-offs only make sense when you have a lot of static hardware you have to use and very little automation available to you. We all know - or quickly learn - that having a single massive globally-shared parallel filesystem that everyone uses for both active and near-line use is just a terrible idea, and one that’s done grudgingly only because it’s all that’s feasible on-prem. The idea of recreating that in the cloud is absurd. Tools like Parallel Cluster allow you to spin up what’s needed per job, and you can have a Parallel Cluster per user or per group, or per-larger-organization but with filesystems per job class, and with data staging in and out.
CFD Direct’s OpenFOAM environment is really nice to see as a step beyond that, building an application on top of some similar infrastructure - with a specialized interactive application that runs directly on the cloud infrastructure over a high-performance Remote Desktop. Whatever the future is of routine (non-hero-calculation) HPC, on the cloud or on-prem, it’s going to look a lot more like this than slurm scripts.
Calls for Submissions
Applications Open for the 2022 Better Scientific Software (BSSw) Fellowship Program - Webinar 13 Sept, Application Due 30 Sept
Each 2022 BSSw Fellow will receive up to $25,000 for an activity that promotes better scientific software. Activities can include organizing a workshop, preparing a tutorial, or creating content to engage the scientific software community
SC22 Planning Committee Applications - Applications due 30 Sept
If you’re interested in being part of the planning committee for Supercomputing ’22, apply here by the end of the month.
19th Annual Workshop on Charm++ and Its Applications - Abstracts due 30 Sept, Virtual Workshop 18-19 Oct
From the call:
Authors are invited to submit abstracts or short papers describing research and development in the broad themes of parallel processing emphasized by Charm++, AMPI, and Charm4Py including runtime adaptivity, message-driven execution, automated resource management, and application development.
International Symposium on Computer Architecture (ISCA) 2022 - June 11-15, 2022, New York, NY, Abstracts Due 16 Nov, Papers due 23 Nov
Paper topics of interest to research computing teams include Processor, memory, and storage systems architecture, Datacenter-scale computing, Evaluation and measurement of real computing systems.
9th European Conference on Service-Oriented and Cloud Computing (ESOCC 2022) - 22-243 March, Lutherstadt Wittenberg, Germany, Papers due 31 Oct (research papers) & 14 Jan (Projects, PhD Symposium, Industrial)
The European Conference on Service-Oriented and Cloud Computing (ESOCC) is the premier conference on advances in the state of the art and practice of service-oriented computing and cloud computing in Europe. The main objectives of this conference are to facilitate the exchange between researchers and practitioners in the areas of service-oriented computing and cloud computing, as well as to explore the new trends in those areas and foster future collaborations in Europe and beyond.
Events: Conferences, Training
SciDataCon - 18-28 October, Virtual, registration (per-session) free
Organized by CODATA and WDS, it includes talks on the following topics:
- Implementing and Assessing FAIR
- Data Skills
- Data Stewardship
- Data Centres and Repositories
- Research Infrastructures
- Global Open Science Clouds, Platforms and Commons
- Data for the Sustainable Development Goals and Disaster Risk Reduction
- Data in Cross-Domain Research
- Data in the Earth Sciences
Random
Running X11 GUI apps in docker containers.
Update in what’s coming in C’23 including digit separators (const int a = 1’234’567), else-if preprocessor macros, and better integer types including a fundamental type for N-bit integers.
This is interesting - a company called BuildJet is offering drop-in replacement of cheaper GitHub actions on bigger instances. I have no idea who they are or whether their offerings are any good, but all things being equal, competition there is good for us.
Writing a PC game that fits entirely in the boot sector.
Speeding builds of rust projects.
Amazon’s EKS-anywhere is an entire open source Kubernetes and management tools distribution, allowing an AWS-consistent management experience for on-prem kubernetes deployments.
That’s it…
And that’s it for another week. Let me know what you thought, or if you have anything you’d like to share about the newsletter or management. Just email me or reply to this newsletter if you get it in your inbox.
Have a great weekend, and good luck in the coming week with your research computing team,
Jonathan
About This Newsletter
Research computing - the intertwined streams of software development, systems, data management and analysis - is much more than technology. It’s teams, it’s communities, it’s product management - it’s people. It’s also one of the most important ways we can be supporting science, scholarship, and R&D today.
So research computing teams are too important to research to be managed poorly. But no one teaches us how to be effective managers and leaders in academia. We have an advantage, though - working in research collaborations have taught us the advanced management skills, but not the basics.
This newsletter focusses on providing new and experienced research computing and data managers the tools they need to be good managers without the stress, and to help their teams achieve great results and grow their careers.
Jobs Leading Research Computing Teams
This week’s new-listing highlights are below; the full listing of 163 jobs is, as ever, available on the job board.
Principal Technical Program Manager, Quantum Computing - AWS, Pasadena CA USA
The Amazon Web Services (AWS) Center for Quantum Computing in Pasadena, CA, is looking to hire a Principal Technical Program Manager to coordinate and manage research and development activities across a diverse team consisting of scientists, hardware engineers/technicians, and software developers. We are committed to the growth and development of every member of the Center for Quantum Computing. You will receive career-growth-minded management and mentorship from a software and science team and also have the opportunity to participate in Amazon's mentorship programs. You will work closely with quantum research scientists and have opportunities to learn about quantum computing technology and contribute to the development of scientific software for quantum computing at AWS.
Technology Delivery Manager (Research Computing Service) - Imperial College London, London UK
ICT is transforming support for Researchers with several initiatives concerning Research Data, High Performance Computing (HPC) and Research Software Applications. These initiatives include provision of a secure data facility, implementing a Cloud offering for HPC, redesigning processes and services to improve the researcher’s experience; and reassessing the software supporting Open Access publications and research data. Here is an opportunity for a technically-skilled professional with a solid understanding of project delivery to support world leading research. The role will coordinate multiple groups across both ICT and the wider college and support teams with planning, impact analysis, scheduling and implementing changes and releases and making decisions.
Manager, Fraud Data Science - RBC, Toronto ON CA
Fraud Management employs deep subject matter expertise to identify, mitigate and control Enterprise fraud risk. Within Fraud Management, the Data Science & Analytics (DSA) team develops and optimizes fraud detection strategies, to maximize operational efficiency and minimize client impact. As Manager, Fraud Data Science on the Analytics Partnerships team, you will develop analytics to support planning and decision management, contributing meaningful insights and informing sound business decisions. You will collaborate with internal and external analytic CoEs and develop fraud risk models and features that contribute to optimizing performance across the pillars of fraud loss, operating cost, client experience and risk framework.
Manager, Research Computing Services - Columbia University, New York NY USA
Reporting to the Sr. Director, Research Services; the Manager of Research Computing Services (RCS) manages the research computing service offerings, interacts with leaders of other research support groups including the CUIT High-Performance Computing team, Office of the Executive VP for Research (OEVPR) and other CUIT groups. Current research computing services include managing embedded support staff (research support personnel embedded within departments), the Secure Data Enclave (SDE), electronic lab notebooks, research data platform, cloud , research data transfer. Key initiatives to be accomplished by the incumbent include assessment and procurement of research tools to address research needs across the research data lifecycle. Additionally, the Manager leads collaboration efforts with other central research support entities at Columbia University.
Team Lead - Coiled (managed Dask), Remote
We’re looking for a Team Lead for our Cloud team. In this role, you will manage "own" a few product features from conception to delivery, including helping with scoping and reporting on status. You will also manage two to four software engineers within the larger team, and help with their growth. We expect this role to be a player / coach: you'll spend up to half of your time on development and code review, but the majority on growing your team and managing feature development and delivery.
Deputy Director - National Computational Infrastructure - Australian National University, Canberra AU
The NCI Board and the ANU are seeking an outstanding leader for the next phase of NCI’s development. The Deputy Director will play a significant role nationally and internationally, to promote NCI and the development of eResearch in Australia. Successful applicants will be innovative and inspirational leaders with relevant expertise and experience in high-performance computing, a passion for creating and nurturing positive collaborations, and the ability to manage a service-oriented organisation with highly qualified professional staff. An attractive remuneration package will be negotiated.
Associate Director - National Computational Infrastructure - Multiple Positions - Australian National University, Canberra AU
We are looking for five (5) Associate Director positions to lead our integrated hardware, services and expertise to drive high-impact research and groundbreaking outcomes for ANU and Australia. Associate Director – Cloud Services (Senior Manager 3); Associate Director – High Performance Computing (HPC) Services (Senior Manager 3); Associate Director – Storage Services (Senior Manager 3); Associate Director – HPC Performance Optimisation and Productivity (Senior Manager 3); and Associate Director – Data Management (Senior Manager 3). To be effective in this role, you will be an exceptional leader, communicator, collaborator and networker who can successfully build and nurture relationships with key stakeholders and create an environment that encourages innovation and continual improvement to support the University. Your demonstrated experience with the development, implementation and management of higher performance computing in a complex environment to help drive the strategic objectives of the University.