Research Computing Teams #131, 23 July 2022
Hi!
A question came in from a reader - I’ve talked before about how to not do things, and in my recent talk I said “do whatever researchers ask for” isn’t a reasonable strategy. We have finite resources, and we owe it to our communities and to science to focus those resources on the highest-impact things we can be doing. But what does that actually look like when you've been asked to do something well out of scope? Below’s a lightly edited version of what I sent back:
It’s important to pay attention to user needs, and thank them for their requests - if nothing else it’s useful data! But we can’t fall into the trap of trying to do everything a researcher asks for (or even every thing many researchers are asking for!). People want a lot of things, and our time and resources are finite. It’s perfectly ok for people to ask us for things, and it’s perfectly ok for us to say no.
Here’s a partial list of examples where it wouldn’t make sense for a team to provide a service that’s asked for:
- The request is an XY problem - people asking for X when what they really need is Y. (Consultants deal with this all the time). An example from the last newsletter is research computing and data team leads saying they want a template strategic plan when what they really mean is “A funder/stakeholder/institution has asked for some strategic documents and I don’t know what to give them”
- The request is for something that would be helpful to the researcher but would pull resources away from areas where the team is having more impact
- The request is for something that is close to something the team is doing now, but the team is looking to move away from that sort of work
- This request is going to be a one-off or a rare request that isn’t worth the ramp-up effort to support
- There are other ways to get the needed outcome, possibly involving other service providers
- The request is for something that is does not support institutional/funder/stakeholder priorities
- The team just doesn’t have the time/expertise/funds - doing something poorly is worse than not doing it at all
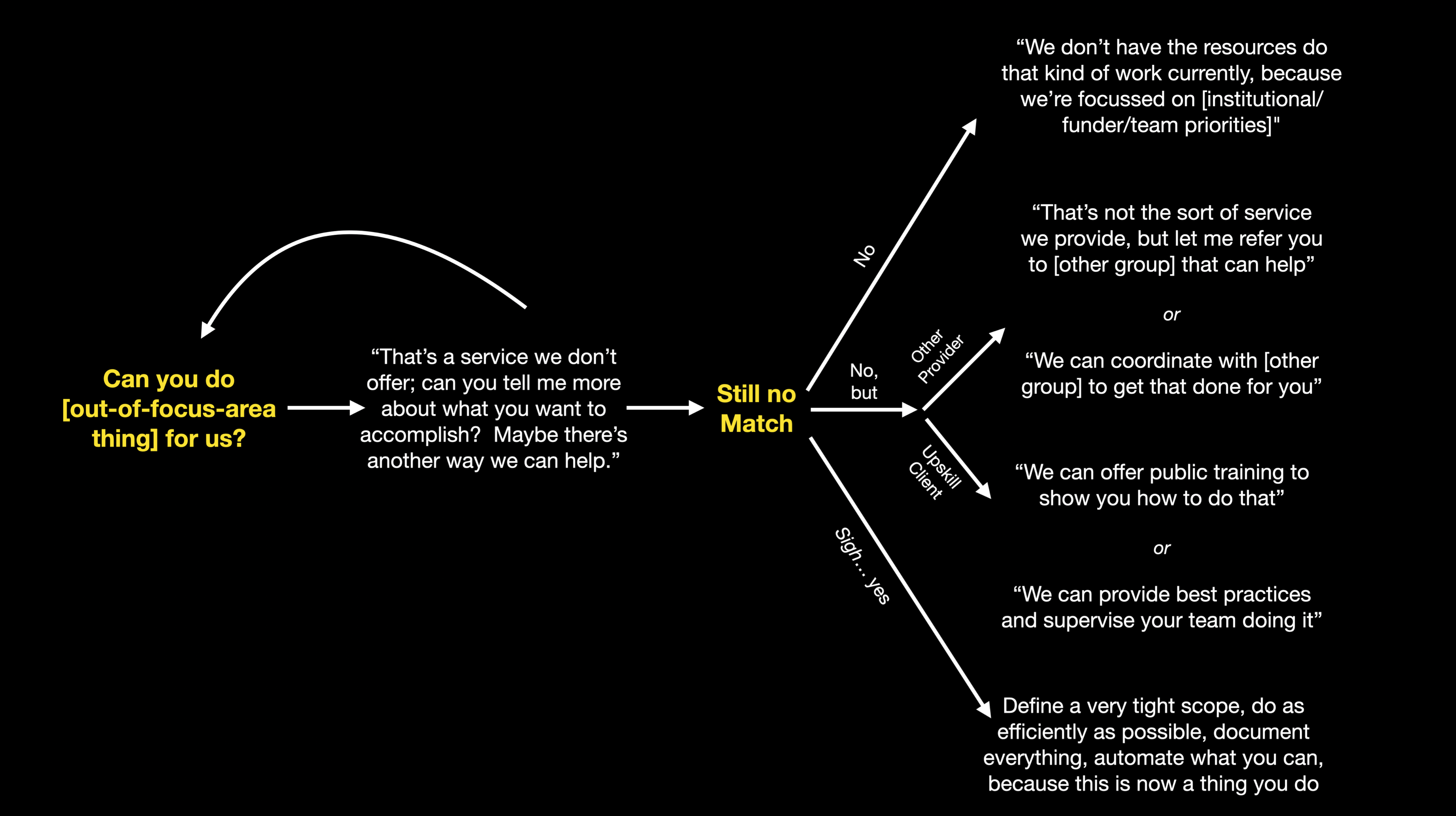
Ok, great. There’s reasons for not doing the thing. But what now? Here’s a few ways to decline providing a service:
- “That’s a service we don’t offer; can you tell me more about what you’re trying to accomplish? Maybe there’s another way we can help”
- “We don’t have the resources do that kind of work currently, because we’re focussed on [institutional/funder/team priorities]"
- “That’s not the sort of service we provide, but let me refer you to a group that may be able to help”
Not doing the thing ourselves doesn’t mean we can to support the request; there’s some things we can do without getting fully drawn into the team doing it themselves. A partial list includes:
- Offering to coordinate with another provider to get the work done
- Offering to do the literature scan and provide best practices
- Offering training or consulting on how to do the work themselves
And we can at least to try to constrain the involvement if it’s something that’ll be ongoing:
- Have a very tight scope, clear efficient process for it, automate it as much as possible, and deliver it as a productized service or a product, constantly iterating it to be as low-effort as possible
But beware of this last option. There’s no such thing as a one-off in a service organization. If you do the thing, one way or another it’s going to be known that this is a thing you do now.
I’ve tried to summarize that as a diagram:
What do you think - do you have other suggestions for our readers? Let me know!
And if you have a question or topic you’d like to see discused, just email me at any time. Send to jonathan@researchcomputingteams.org, or hit reply to one of these emails. I’ll also set up a simple poll at pollly where people can submit questions pseudonymously and we can vote for priorities - I’ll seed that poll over the weekend with some questions that have come up over time that I’ve never written down answers to.
In the meantime, here’s the roundup! I’ve been involved in a hackathon last week (and the next week), so maybe unconsciously this week’s links tilted a little software-heavy.
Managing Teams
We're hiring - how do we assess candidates for RSE jobs? - Sheffield RSE Team
We’ve talked in the past about providing candidate packets (e.g. Jade Rubick, #84), or about telling candidates what to expect from your interviews (from Julia Evans, way back in #33!). Here’s a great RCD example - the University of Sheffield RSE group giving a clear brief overview of how they assess RSE candidates. Nice!
How to present to executives - Will Larson
A nice complement to last issues's posts on working with advisory boards, here's how to present to decision makers like institutional leaders, funders, and advisory board members:
The foundation of communicating effectively with executives is to get a clear understanding of why you’re communicating with them in the first place. [...] When you’re communicating with an executive, it’s almost always one of three things: planning, reporting on status, or resolving misalignment.
Although these are distinct activities, your goal is always to extract as much perspective from the executive as possible. Go into the meeting to understand how you can align with their priorities. You’ll come across as strategic and probably leave with enough information to adapt your existing plan to work within the executive’s newly articulated focuses or constraints.
I'd also add that in our case we have another focus area - to advocate for things we need, such as resources or support with particular stakeholders.
Either way, the advice is good - communicating as concisely and effectively as possible is a key part of the process. Larson suggests a SCQA format (I've seen variants of this with different letters, but the basic idea is the same):
- Situation: what is the relevant context?
- Complication: why is the current situation problematic?
- Question: what is the core question to address?
- Answer: what is your best proposed answer(s) to the posed question?
Beyond that Larson gives several suggestions, all of which are relevant in our context:
- Never fight feedback. Whether it strikes you as fair or not, it's their perception, so you're going to have to learn to deal with it
- Don’t evade responsibility or problems.
- Don’t present a question without a possible answer.
- Avoid academic-style presentations - this is true even when the people involved are academics. You're not teaching them about something that will be on the exam, you're giving them crisp status updates or jointly aligning on a plan or adovocating for a result or agreeing on next steps.
- Don’t fixate on your preferred outcome.
Product Management and Working with Research Communities
A Farewell to XSEDE: A Retrospective & Introduction to the ACCESS Program - Ken Chiacchia, HPCWire
Chiacchia summarises John Town’s presentation (.pptx) describing the history of both incarnations of XSEDE, and referring to the end-of-XSEDE1 and admirably frank end-of-TeraGrid final reports.
The talk gives a great overview of the challenges faced when running inherently multi-institution support for a rapidly diversifying range of needs and users. XSEDE admirably focusses on the users and research for metrics. All research metrics - like the XSEDE choices of papers, citations, and dollars of funding - are inherently limited. But they are vastly closer to tracking outcomes that actually matter than number of jobs run, or cycles or bytes used.
Chiacchia also summarizes talks about the upcoming ACCESS programme which will take over from and evolve XSEDEs models for operations, allocations, and support - I can’t find those talks online, I hope they’ll be public at some point.
Towns also talks about the importance for supporting the increasing professionalization of research systems, software, and data staff. Our newsletter community, helping support the professionalization of the leads and managers of those crucial staff, are an important part of this!
Stop Raising Awareness Already - Ann Christiano & Annie Neimand, Stanford Social Innovation Review
As I’ve said before, our community in research software, systems and data can learn a lot from the nonprofit and social enterprise communities. Those two groups are often lumped together into a category of “mission-driven organizations”. And, after all, that kind of describes our teams, too.
Christiano & Neimand describe the Information Deficit Model, the mental model that begins “If only people knew about…”. I’ve seen teams in our communities fall into the same trap. “If only researchers knew our team was here, ready to help, they’d come knocking on our door.” So they send emails to new faculty, slip in brochures into new grad student arrival materials - and nothing happens. Repeat with “If only researchers knew about the importance of FAIR data” or “about how useful version control is” or “about reproducible workflows” or…
Because it doesn’t work that way, right? We’re probably dimly aware of our own institution’s print shop or machine shop or stats help desk or… and merely knowing that they exist doesn't change our behaviours. We each could easily list a half-dozen behaviour changes that would improve our lives, and hey that reminds me, how are your 2022 New Year’s resolutions going? Yeah, mine too.
The article talks about awareness leading to harm or backlash. Our cases are less dramatic, but there’s certainly anecdotes of, e.g., “reproducible open science/good software development practices/cluster computing is the right way to do things” actually turning people away from teams that could help them. People don’t want to be seen to be doing the “wrong” thing.
In the context of public interest journalism, Christiano & Neimand describe a four step approach:
- Target Your Audience as Narrowly as Possible
- Create Compelling Messages With Clear Calls to Action
- Develop a Theory of Change
- Use the Right Messenger
For us, we want people to not just know about but engage with our teams, so we’d want to make specific targeted outreach, find out what they want and need, make it clear what we can do and help with for the teams, show how that could lead to more of what they want. That’s almost always going to be the much more labour intensive individual interaction rather than just sending out broadcast messages for “awareness”. But getting people engaged is hard work.
Research Software Development
What NOT to fix in a Legacy Codebase - Nicolas Carlo
We work with a lot of legacy code, and the temptation is just to leave it completely alone until we get so sick and tired of it that we just want to rewrite the whole thing. But code bases are large, and generally known-working (or at least the limitations are well-understood). Carlo counsels us to focus on the highest-impact work (which is good advice for managers and leads in general!)
- Don’t rewrite the whole thing - just work on a piece
- Don't fix what’s not in your way - refactor code that’s actually a problem, add tests, etc
- Don't waste time on easy refactorings - focus on the high-impact changes, complex parts of the code base that you have to work with often
Relatedly, I’ve been meaning to read Marianne Bellotti’s Kill It With Fire. People seem to really like it. It also takes a very pragmatic view of working with existing software, and not getting carried away with massive rewrites of code that isn’t causing problems. Has anyone read it and have some comments?
Debug logs are a code smell - Jonathan Hall
Logs, too, are something that a lot of research software either does not have at all, or that expose every printf("Here! 123\n") debug statement that was ever useful. Neither of those are great.
Hall has an analogy I like here - the ssh debug statements in verbose mode:
The important thing to recognize here is that (usually) this type of debugging output does not exist to debug the program itself (
sshin this example), but it exists to help debug a larger process (i.e. network communication). As such, it needs to be well written, (grammar/spell check advised), clear, and descriptive, because it’s part of the program’s UI.
Logs are to describe (in increasing detail) what a program did, and maybe why it did it. That’s often useful in knowing what part of a code base to take a look at! But active debugging statements are a debugging tool one might use in the moment, not useful logging behaviour.
Write The Docs has a really good “beginners guide to writing documentation” page focussed on the why and hows, based on an earlier presentation.
If you really love your project, document it, and let other people use it.
Research Data Management and Analysis
Solving Society’s Big Problems Means Funding More Than Supercomputers - Tobias Mann, The Next Platform
Playing catch-up in building an open research commons - Bourne et al, Science
I am heartened to see, now that people can run HPL at a new round number of flops per second, that the community’s attention is starting to turn back to more important research computing and data needs. Mann summarizes and gives some context to Bourne et al.'s article calling for more data (and associated compute, and of course software) resources along the lines of open research commons. Some regions are doing passably well at this (like Europe, although sustainability remains a challenge) as well as some fields, but elsewhere it’s pretty grim.
Research Computing Systems
We Learn Systems by Changing Them - Jessica Kerr
I don’t think Kerr’s premise is controversial in our community - new sysadmins and ops staff learn by building small systems or components of systems, for instance. And whenever even experienced staff make changes to long running systems, there are almost always Exciting New Discoveries.
And yet the tendency is to keep research computing systems as encased in amber as possible, frozen in stasis so that things don’t break. That’s a reasonable goal, but it also leads to loss of learning about what’s going on. It leads to fading understanding about the current state of the system and its interactions as previous mental models grow out of date.
This is the basic idea behind “chaos monkey” or disasterpiece theatre (#5) approaches, where changes are deliberately introduced to systems to test understanding of the system. Of course, for that to work, there has to be a clear plan, hypotheses tested, and new knowledge documented. Or, as myth busters reminds us:

Random
There seems like a surprising level of interest in the C++ community for Carbon, a Google-initiated project. Carbon explicitly aims to be a path towards a successor to C++, maintaining source code interoperability with existing C++ codebases but breaking ABI compatibility (after a controversial vote in the C++ committee to not do such a thing). It has very Rust-inspired syntax but hews much more closely to a C++ view of the world.
Some cool things are making it into C23, including embed for embedding binary data directly into executables (this will reduce the need for so many hacky convert-to-ASCII scripts and so much makefile chicanery), along with C++-style auto, nullptr, true and false keywords, and constexpr.
A very cool hands-on practical introduction to deep learning by the fast.ai team. (They also have a solid data ethics course).
The case against symbolic links.
Getting good Rust performance - the Rust Performance book.
Pleasant debugging with GDB and DDD. DDD’s data plotting capabilities made it very useful back in the day for working with small numerical codes. Sadly it seems to be moribund now, and there don’t seem to be any alternatives that have anything like DDD’s data visualization capabilities.
This is cool - making use of H5Web (serving HDF5 data) for purely local data visualization within VSCode - vscode-h5web.
Solving ODEs with Haskel and Taylor Series.
A complicated machine with simple interaction (pull the black handle of the rope) written entirely in CSS.
Microsoft’s FOSS fund is now offering (modest) support for curl, as well as GNOME, MSYS2, Leaflet, and systemd. Which, you know, good, and it would be awesome if we could get routine funding for research-critical open source software other than from the goodness of tech giants’ hearts.
Lego is issuing a new 70s-style Space Lego set in August. Pew pew! Zoom!
Finally, lasers have a use for us theorists and computational researchers. Ultrafast cold-brewing of coffee by picosecond-pulsed laser extraction. Which, when you think about it, is also Pew pew! Zoom!
That’s it…
And that’s it for another week. Let me know what you thought, or if you have anything you’d like to share about the newsletter or management. Just email me or reply to this newsletter if you get it in your inbox.
Have a great weekend, and good luck in the coming week with your research computing team,
Jonathan
About This Newsletter
Research computing - the intertwined streams of software development, systems, data management and analysis - is much more than technology. It’s teams, it’s communities, it’s product management - it’s people. It’s also one of the most important ways we can be supporting science, scholarship, and R&D today.
So research computing teams are too important to research to be managed poorly. But no one teaches us how to be effective managers and leaders in academia. We have an advantage, though - working in research collaborations have taught us the advanced management skills, but not the basics.
This newsletter focusses on providing new and experienced research computing and data managers the tools they need to be good managers without the stress, and to help their teams achieve great results and grow their careers.
Jobs Leading Research Computing Teams
This week’s new-listing highlights are below; the full listing of 134 jobs is, as ever, available on the job board.
Manager, Computational Bioinformatics - Pfizer, Groton CT USA
Pfizer is seeking a talented, self-motivated Manager, Computational Bioinformatics, with strong background in developing analytical algorithms, data processing pipelines, and data management to support data analytics and next generation sequencing (NGS) efforts in biomarker analysis in Early Clinical Development. The successful candidate will analyze data from next generation sequencing (NGS) and other high-dimensional omics data types, providing bioinformatics and data science support to various programs in the fast-paced environment of early clinical trials. This work will elucidate the molecular impact of early clinical assets, and therefore has the potential to inform proof of mechanism and proof of concept decisions for advancing these assets, or to re-prioritize therapies in the pipeline for disease.
SAFe Product Manager/Operations Scientist - Square Kilometer Array Observatory, Cheshire UK
For managing the software development of the project, SKAO has adopted the Scaled Agile Framework (SAFe®) for Lean-Agile development processes. The Operations Scientist / SAFe® Product Manager will represent the interests and priorities of the SKA Operations team for the construction and operation of the SKA Telescopes. They will be responsible for ensuring that the SAFe® teams deliver value to the Observatory and its users by specifying and prioritising features and capabilities, as well as developing and maintaining the roadmap for data processing software products. The Operations Scientist / SAFe® Product Manager will be responsible for coordinating with stakeholders and development teams to define work and assess and accept work when it is complete. As such, the Operations Scientist / SAFe® Product Manager will need to understand software development practices and technology.
Program Manager, Applied Science - DeepMind, London UK
The role of the Program Management team is to coordinate and enable our teams to be the best at what they do and to make fast-paced progress towards our mission. We continually pursue scalable and sustainable ways to optimize work on real world applications, cultivating an environment where people can be both highly collaborative and deeply creative, making responsible and pioneering research progress at pace. We build strong relationships with teams and team members, bringing clarity to ambiguity and providing stability during change. We continually deepen our domain knowledge, working alongside engineers, researchers, and product managers to execute on programs and projects with Google / Alphabet partners.
Research Manager, Machine Learning - Invenia Labs, Cambridge UK
We use algorithmic decision making and optimisation to help electricity grids to operate more efficiently, reducing greenhouse gas emissions and economic waste. We have a new opportunity for a skilled people manager with some technical expertise to lead this group, playing a vital role in nurturing research talent and coordinating between teams. Since Invenia is growing quickly, there is room for a wide variety of skills. This is an opportunity to sculpt a role to your own strengths and goals - whether you want to maintain some level of technical work alongside management, gain more experience in business planning, or have another idea
Pricipal Scientist, Data Science - XPO Logistics, Chicago IL USA
As the Principal Scientist, Data Science, you’ll turn data into information, information into insight and insight into business decisions. You will conduct full life-cycle analysis to include requirements, activities, and design. In our team, you’ll have the support to excel at work and the resources to build a career you can be proud of.
Senior Scientist - HPC and Simulation - Apple, Cupertino CA USA
Apple’s Exploratory Design Group (XDG) is seeking an exceptional and energetic senior computational expert to conceive, develop and execute break-through computational models, algorithms, tools and investigations. Working with an outstanding multi-disciplinary team on an inspiring long-term mission, you will use your top-to-bottom knowledge and skill in state-of-the-art computational innovations to model, enable, advance and perfect an unprecedented class of new Apple products. Available resources and the opportunity to lead and build a team will be limited only by your ability to deliver impactful results, your drive, and your ability to describe and promote a compelling vision.
Associate Vice President for Research Computing - Virginia Tech, Blacksburg VT USA
The Associate Vice President for Research Computing provides strategic leadership, vision, and execution for advanced research computing services to support the Virginia Tech research community and to advance the competitiveness and success of the university’s research enterprise. Recognizing the importance of computation, visualization, and data to its research mission, Virginia Tech has made significant and continuing investments in cyberinfrastructure and professional personnel in computational science, visualization, support, and operations.
Geospatial Software Engineering Lead, Geospatial Technology and Research Team - Azavea, Remote USA or CA or Philadelphia PA USA
Azavea is a civic technology firm based in Philadelphia that uses geospatial data to build software and data analytics for the web. As a B Corporation, our mission is to use advanced geospatial technology for positive civic, social, and environmental impact. Most of our work deals with local governments, non-profit organizations, and academic or federal research projects. Azavea is looking for an Engineering Lead to join our Geospatial Technology and Research Team (GTR). The GTR team leverages open source tools to design large scale data processing pipelines in the cloud, and leads Azavea’s machine learning and research efforts. The Engineering Lead role at Azavea is a Software Engineer role that includes management responsibilities and provides technical leadership for the team. Engineering Leads are expected to spend about 50% of their time on team management and leadership activities, and 50% of their time directly contributing to project and research work.
Team Leader - Health Data Research - Barcelona Supercomputing Centre, Barcelona ES
The Life Sciences Department from the Barcelona Supercomputing Center seeks a team leader to establish a new team on Health Data Research within the Life Sciences Department that will collaborate closely with the INB/ELIXIR-ES unit. The selected candidate will work on the acquisition, normalisation and standardisation of Health Research Data, potentially incorporate new members to the team in the near future, and drive projects in the area in close collaboration with domain experts in the clinic (collaborators).
Product Manager, Quantum Computing - NVIDIA, New York NY or Austin TX USA
We are looking for a technical, user-focused Product Manager to build exciting new products to enable researchers in the area of Quantum Computing. As a product manager for the product you will establish a vision, gather requirements, set product roadmaps and provide go-to-market strategies. You will work with software developers, hardware developers and research scientists to enable scientific breakthroughs in this exciting area.
Manager, Research Informatics - London Health Sciences Centre, London ON CA
Reporting to the Director, Research Corporate Services & Finance, the Manager, Research Informatics is a key member of the research institute’s leadership team. The Manager is responsible for providing direct and indirect leadership to a small team of system analysts and developers who support a variety of research related technology solutions. These solutions include ones related to specific research studies / initiatives, as well as technology infrastructure that supports the core operations of the research institute. The Manager works closely with colleagues in Information Technology Services to ensure research practices and technical solutions are aligned with corporate technology standards (i.e. data management, data security, software development standards, etc.)
Engineering Manager, Machine Learning - Lilt, Montreal QC CA
In collaboration with our Director of Research, the Engineering Manager, Research will manage a team of (~4) software engineers that are part of the Research organization. This role will work remotely from Canada until such time as the Company establishes permanent office premises, at which time this role will be expected to work in the office in a hybrid capacity.
Data Architect, R&ED Scientific Data Engineering - Bristol Myers Squibb, Redwood City CA or Princeton NJ USA
The Associate Director, R&ED Scientific Data Engineering - Data Architect, is accountable for the development and evolution of data architecture for R&ED. The Data Architect will create a model and a strategy that will enable integration of complex scientific data across R&ED to enable advanced analytics and machine learning. This role will work in partnership with a broad range of partners in IT and in R&ED, including IT Business Partners, enterprise engineers and architects, Digital Capability Managers, scientists, and software development teams to deliver innovative data capabilities while ensuring adherence to data architecture standards and best practices. This position resides within the R&ED IT organization.
Chief Data Architect - Pacific Northwest National Laboratory, Richland WA USA
The Environmental Molecular Sciences Laboratory (EMSL) is a Department of Energy, Office of Science, User Facility sponsored by the Biological and Environmental Research (BER) program. At EMSL, our scientists focus on fundamental biological and environmental research. EMSL is seeking a chief data architect to lead EMSL’s data management activities. The candidate will be responsible for developing and implementing EMSL’s overall data strategy according to sponsor’s expectations, identifying and prioritizing data collection points and storage needs, collaborating with domain scientists as stakeholders relying on the data systems, and maintaining database systems/architecture for secure and efficient performance.
Associate Director, Data Architecture, Stewardship, & Analytics – Research Informatics - Moderna, Cambridge MA USA
Moderna is rapidly growing across our Research Science portfolio. That growth is not limited to new team members joining an organization, but also to the Data that these teams create. The Digital for Research Product Team is looking for a Data Architecture and Stewardship leader to be a keeper of the processes, policies, rules, and standards by which our Research Scientists define and consume their most critical data. This role will also be a maker of analytics and visualization dashboards, so familiarity with scientific facing BI tools (Spotfire, Tableau, Vortex) is a must. This position reports into the Director, Research Informatics and is based in Moderna’s Cambridge, MA office.
Director of Software Engineering, Research Data Platforms - Flatiron Institute, New York NY USA
In this role, you'll manage 2 platform engineering teams supporting the Evidence engineering division of Flatiron. In addition, you'll also: Provide mentorship and career development to tech leads, managers and senior software engineers, Hire and foster an inclusive culture to retain world class engineering talent, Partner with a senior product manager to lead the ideation of the next generation of shared tooling, infrastructure and processes to increase the Evidence engineering teams’ velocity
Director, Faculty of Arts & Sciences Research Computing - Harvard University, Boston MA USA
Harvard University’s Faculty of Arts & Sciences (FAS) seeks a Director to lead its FAS Research Computing (FASRC) organization. The newly reconceived Director position reports jointly to the Assistant Dean of Research in the FAS Division of Science and to the Vice President for Information Technology & University Chief Information Officer in her capacity as FAS’ chief information officer. The Director will provide leadership in the ongoing development and management of research-computing resources for faculty across all of FAS’ divisions and thus will play an important role in advancing Harvard University’s research mission.
Head of High Performance Computing - Lambda, Remote USA
Lead and grow Lambda’s high performance computing team. Build a team that can design high-performance and cost-effective servers and clusters for deep learning. Hire, develop, and retain world-class engineers. Establish effective collaborations with customers, suppliers, and other teams within Lambda.
Scientific Data Architect, Canadian Centre for Computational Genomics - McGill, Montreal QC CA
The Data Architect will be responsible for the architecture of clinical and genomics data in various projects within C3G, solving challenges arising from the management and analysis of such scientific data. By creating blueprints, implementing and maintaining data management systems, the candidate will develop novel methods to increase interoperability and discoverability of data and metadata across life science research fields, fulfilling the C3G engagements towards Open Science. This will involve frequent interactions with partners at other academic institutions, and international standards organizations such as the Global Alliance for Genomics and Health (GA4GH).
Principal Bioinformatics Research Scientist - St Jude Children's Resarch Hospital, Memphis TN USA
A Principal Bioinformatics Research Scientist position is immediately available in the lab of Dr. Jinghui Zhang, Chair of the Department of Computational Biology, for a highly motivated candidate to lead omics-based investigation on the etiology, response and therapeutic targets of pediatric cancer. Candidates with a strong background in computational biology, cancer genomics/epigenetics or cancer predisposition are highly encouraged to apply for this position. Successful candidates shall have a well-established track record in cancer genomic/epigenomic research, in-depth experience in data analysis, excellent critical thinking and manuscript preparation. Experience in software development and mentoring for junior staff is highly desirable.
Bioinformatics Manager - Illumina, Cambridge UK
You’ll be joining a high performing team that work closely with other teams across ILS, including Software Engineering, Laboratory Operations and ILS Development teams. Day-to-day activities involve leading the bioinformatics scientific input multiple development projects, capturing user needs and requirements, DOE, driving to completion verification and validation activities and documentation deliverables as required as part of our Quality Management System. This lead-analytical role will be expected to guide multidisciplinary groups to deliver software and laboratory solutions to support cutting-edge sequencing operations and data analysis that make a difference to peoples’ lives.