Research Computing Teams #129, 9 July 2022
Hi!
I write a lot here about challenges our teams face, but I don’t think I mention often enough the huge advantage our background in science is in our work (or in similar work in other environments).
Whether we were trained in science or just picked up that mindset by immersion in the ecosystem, the skills we have are skills that (say) tech companies pay real money to train their staff in. The advanced collaboration and influencing skills we have to develop in scientific collaborations is a huge advantage all the way up the management or technical leadership ranks, for instance. Being willing to think in terms of experiments when making changes (like Beinbold’s article, below), or having a “growth mindset” (current jargon for believing that people can develop new skills(!!)), or being able to synthesize information - these fundamental skills, skills we don’t even bother mentioning in our environment, are in high demand.
It’s not just people skills, either - I see an article about staff engineer interview skills that include being able to estimate well, something every quantitative scientist does without thinking about it, or another article this week about how tech companies are having to relearn basic performance things like array-of-structs vs struct-of-arrays, which many of us have had to learn optimizing scientific code.
These skills are in real demand everywhere, because they are valuable.
Within research computing and data teams, I think we don’t take full enough advantage of those skills because we take them for granted. We’re really good at turning our scientific mindset onto the actual science stuff we’re supporting, but less good when thinking about how we work. Experimenting with new approaches, documenting processes as protocols, collecting data about how well our team is working - our scientific skills are really powerful tools that can be used in a lot of contexts.
Anyway, I’ll write more about that later - for now, on to the roundup!
Managing Teams
Seven Skills to Save Software - Making Change Happen in Complex Software Environments - Mathiew Beinbold
This article is in the context of leading a massive software rearchitecting effort - that’s the ‘complex software environment’ and ‘save software’ bits. But Beinbold describes very clearly what it takes to make change happen in any complex group.
Skip down to about 1/3 of the way through, to the “The seven skills” slide, and go through the rest. This is an extremely lucid overview of what it takes to make change in an organization. The bits about getting people on board - have new identities for participants, having onramps for people to get involved at all levels of commitment, have ways of allowing people to publicly identify with the change - are great.
This scale of engagement is important when trying to make change happen in a large organization, but even in smaller teams - even just your own small team - these are the steps to go through. With a small team a lot of these things can be done collaboratively, especially coming up with a clear vision.
Beinbold’s steps are:
- Crafting a compelling vision
- Start at the end - what are you celebrating?
- Recast obstacles as outcomes, not absences (e.g. as positives, not negatives)
- The vision must include an articulation of why the current state is not sustainable, an attractive plausible future, a new identity for participants, and a path connecting it together
- Coalition building
- Create onramps for people to get involved
- Start organizing efforts
- Communication
- Evoke the reasons for change they already have
- End with a call to action (and provide schwag!)
- Work via experiments
- Small experiments == less resistance
- Short term wins
- Celebrate the wins
- Empower others
- Terraform the culture - new practices need deep roots
Towards a National Best Practices Resource for Research Computing and Data Strategic Planning - Schmitz, Brunson, Mizumoto Jennewein, Strachan
Why Most Strategies Lack Clarity - John Cutler
The first link is a summary of a workshop at PEARC21 about strategic planning for RCD work, and a survey of challenges. It’s a pretty good distillation of why things are so challenging and confusing in strategic planning in our line of work. It ends with a wish list of thing that would help:
- A repository of templates, examples, and models of strategic planning
- A collection of narratives and use-cases that describe successful programs
- Examples and practices for communication strategies related to strategic planning
- A program of mentoring and identifying expertise related to strategic planning
Another request by a participant listed elsewhere in this document is for “common strategies”, which I think reflects some of the confusion about strategy in our line of work. But the nature of strategies is that they’re very customized to a particular situation. Strategy examples and models, yes, for sure. Case studies are an absolutely classic ways to learn strategy by example. And a list of common tactics is a perfectly sensible thing to want; tactics are applicable in many contexts.
Honestly, I think the terms “strategy” and “tactics“ cause more confusion than they’re worth. We’re not on a battlefield. There’s some outcomes you want, and current problems in the current context preventing reaching those outcomes; a proposed way of solving a problem and achieving an outcome in that immediate context; and a plan to implement the solution. That’s all there is. Using buzzy ill-defined words to describe those things clouds thinking and leads to people talking past each other.
Also listed are some challenges in executing operationally, I guess as inputs into what’s feasible when planning:
- Funding
- Rapid changes in compute needs
- Vast storage needs
- Difficulty finding, hiring, and retaining staff
An issue that comes through in several places is that there’s often not a very good overall direction set at the institution level or even at the research level, so it’s hard to see what to plug into. Also, research computing and data often crosses several organizational boundaries - VPR, Libraries and Central IT which typically report up into something like a VP Operations, and often various schools have their own research computing efforts. At best, those individual service providers have clearly defined directions and focuses which collectively leave gaps or overlaps in the overall effort; the more typical case is even those efforts are kind of fuzzy about what they do. Either way there has to be some kind of bottom-up and top down approach to putting something coherent together across an institution.
In the second, Cutler gives his opinions as to why there’s a lack of clarity and coherence in so many strategies. His argument is that people think strategies have to provide certainty, and everything is uncertain, so people are unwilling to commit to a strategy. I definitely think that’s part of it! I think another part is that any meaningful strategy — really, any meaningful decision about the future at all — means explicitly closing the door on other perfectly good possible options, and people are incredibly uncomfortable doing this.
Technical Leadership
Large batches obscure your bottlenecks - Jonathan Hall
Here’s a good technical analogy for technical leaders - large batches are often something we do to hide latency. If we are working in large batches - lots of work in progress, for instance - it’s hard to see what the bottlenecks, the latency issues, are in a team’s work.
The easy way to find bottlenecks, targets for improvement, is just to reduce batch sizes so you can more clearly see where the bottlenecks are in a team’s processes.
Managing Your Own Career
Advice for Engineering Managers who Want to Climb the Ladder - Charity Majors
A good article by Majors on how being a director (in title or in role - a manager of managers) is very different than being a manager. It involves a lot of similar activities, but the function is very different - the broader scope means there’s much more emphasis on working with peers across the organization, stakeholders, and upper levels.
Here’s an announcement on twitter by Dr. Anna Krystalli that she’s started her own freelance R RSE practice. This is fantastic, and I’d like to see more of it. There are advantages to working embedded in an institution, but disadvantages too. After two years of mostly working remotely, researchers have gotten very used to working with research computing and data staff remotely, and there’s no reason (other than slightly easier billing) that such services can’t be offered from outside the institution.
Product Management and Working with Research Communities
Quantum games and interactive tools for quantum technologies outreach and education - Seskir et al., SPIE Optical Engineering
How Effective Is Quantum Education Really? - Kenna Hughes-Castleberry, The Quantum Insider
The amount of educational and training material available for quantum technologies is absolutely remarkable. A lot of this is due to the recent explosion in interest in quantum computing, but quantum materials science etc has meant that a lot of materials predate this. There’s even an EU-funded effort, Quantum Technologies Education for Everyone (QuTE4E). Seskir et al, as part of that effort investigate the state of a number of games and other tools for outreach and education, and Hughes-Castleberry summarizes. This might be of interest for people looking for community outreach tools for quantum efforts in their own institutes, or to survey ideas for outreach and education tools in other fields.
Research Software Development
Synchronization Overview and Case Study on Arm Architecture - Ker Liu, Zaiping Bie, Arm
Arm has a different memory model under concurrency than x86 does (there’s a nice overview by Russ Cox discussed in #81), and a lot of software everywhere very much has an “all the world's an x86” assumption baked in. The white paper described by this blog post gives an overview of Arm’s memory model and synchronization mechanisms, and gives three cases studies (OpenJDK, DPDK, and MySQL) of analyzing problems caused by broken assumptions, and fixing them.
Using Graphs to Search for Code - Nick Gregory
Code static analysis tools and libraries have become so available and powerful that it’s possible to write custom tools to look for particular code idiosyncrasies without too much effort. Here Gregory uses semgrep to search for one patterna across 11,659 Go GitHub repos just by writing one rule, and wrote a (much faster but custom) go program to do the same.
Research Data Management and Analysis
What the F(ederation): Synthesizing the many recent data strategies, white papers, and reviews - Jessica Morley
Morley summarizes and synthesizes a series of nine strategy documents from the past three-ish months(!!) for or relevant to the UK’s National Health Service (NHS) data in healthcare plans. In areas of Direct Care, Managing Population Health, Planning NHS Services, and Research, Morley distills key points under the topics of Platforms, Privacy and Security, Information Governance, Ethics Participation and Trust, and Workforce and Ways of Working.
If you’re interested in considerations around health research data and health research data policy, this summary (and links therein) is a great resource for understanding how a national government that is probably furthest ahead (along with Australia) in thinking about these topics is coming to understand the needs, opportunities, and challenges.
RETRO Is Blazingly Fast - Mitchell A. Gordon
Gordon writes about a paper a team from Google’s Deepmind published at the end of 2021, describing their RETRO model. It’s a large-language training and inference process that uses a database (an index into a dataset plus a way of querying) rather than just flat data, in both the training and inference stages to pull out relevant data. It greatly speeds training, allows for a smaller model (albeit with an associated database).
Docker for Data Science - Alex K Gold
A chapter of a larger online “DevOps for Data Science” book aimed specifically about creating and using reproducible R and Python containers for both day-to-day data science and publishing reproducible workflows.
Research Computing Systems
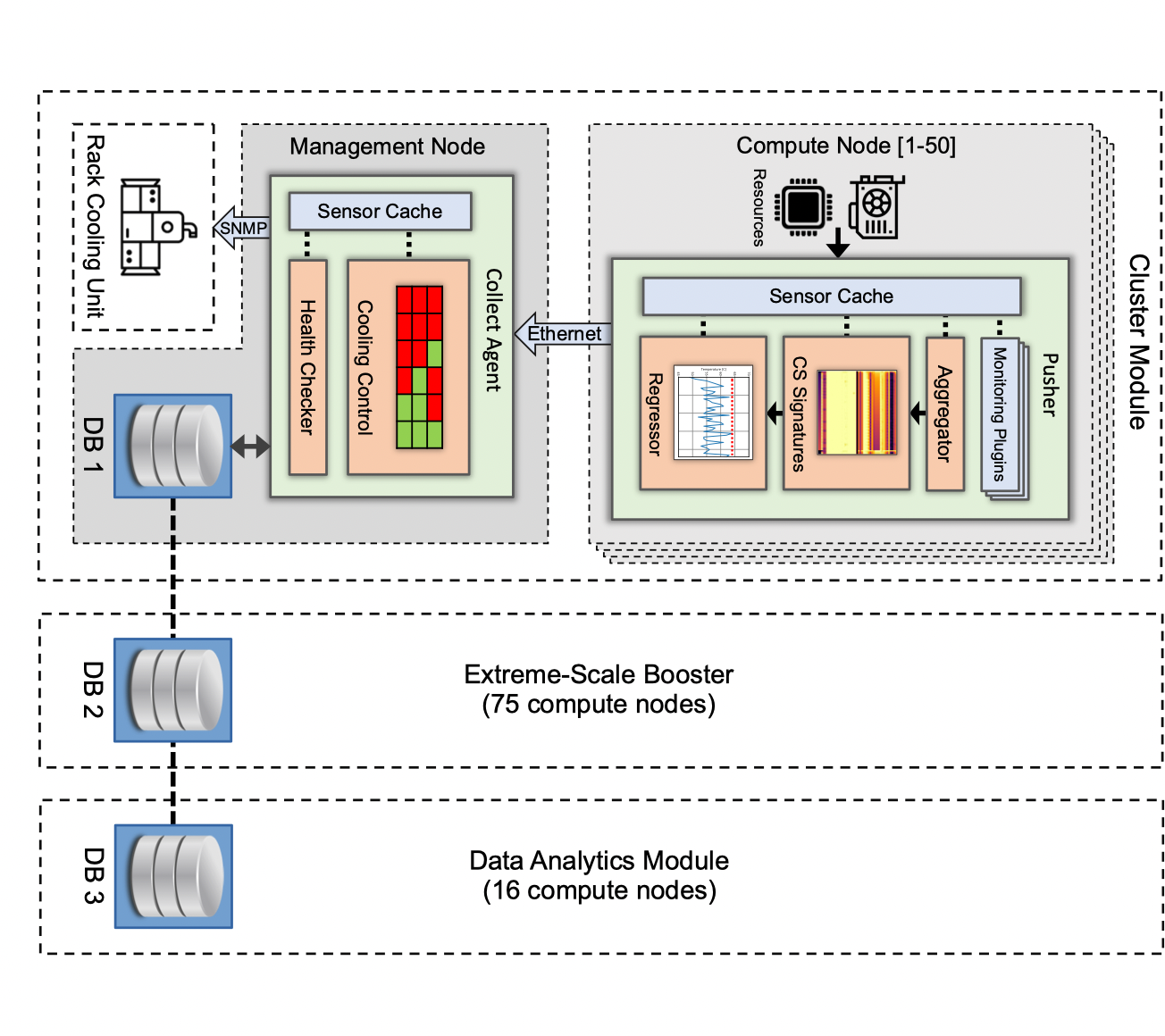
Operational Data Analytics in Practice: Experiences from Design to Deployment in Production HPC Environments - Alessio Netti, Michael Ott, Carla Guillen, Daniele Tafani, Martin Schulz
This is a cool paper by a team from Leibniz, Jülich, and Fujitsu describing near-real time data analytics of HPC clusters operational data for visualization (ODAV) or real-time control (ODAC). At Liebniz, on SuperMUC-NG, they monitor CPU performance, memory activity, and other such metrics (27 in total) through an analysis pipeline and store the data in database for near-real time visualization of jobs as well as being able to go back through job history. (Monitoring these metrics resulted in overhead on the compute nodes well below 1%).
On Jülich’s hybrid DEEP-EST system, with a similar architecture (shown below) they one step further: the system is
used to perform predictive optimization of the system’s warm-water cooling infrastructure. It is in active use since October 2020.

The practical guide to incident management - Incident.io
The Incident.io team has a pretty comprehensive guidebook to incident response. Even if most of our teams don’t do on-call, the other material on responses, and improving based on what is learned is very relevant, as are the playbooks and reading lists.
Random
Measuring memory usage in Python: it’s tricky! Multiprocessing also has its quirks. Finally, CPython 3.11 is 10-60% (average: 25%) faster than Python 3.10, which is good news all around.
NASA Computers in Spaceflight, 1958-1987.
A JIT-ting tool for parallelizing shell scripts(!?) [PDF link]
A very sensible approach to monitoring tiny web services in a minimal way.
An utterly deranged approach to implementing a new programming language, by bootstrapping it through seven layers of abstraction using only assembly language and the layers beneath.
Implementing an assembler entirely in C++ templates.
Simple hypercard-inspired web programming for those new to coding with Anaconda’s PyScript.
Finally, we can do deep learning inference on our Commodore 64s, with Tensorflow Lite for Commodore 64.
You…. you don’t have a Commodore 64 lying around? Ah, you must have been a TRS-80 sort like me. That’s cool, we’ve got you covered. A C64 emulator for the Raspberry Pi.
There’s a new ghostscript PDF interpreter, which is how I found out that ghostscript is still a thing. (Quick, ask me how much I miss having a Linux workstation as my daily driver, if I can hear you over the sound of my laughter).
The history of Coherent, a cheap ($100) commercial UNIX clone for x86 from the early 90s.
TIL that SQLite will give index recommendations.
Style guide for markdown lists, with a markdownlint configuration, to make the lists and version control diffs as readable as possible.
A simple if hacky approach to having a multi-user AWS ParallelCluster by creating posix users as part of the node initialization.
An RSS tool to generate RSS feeds from pages that lack them, RSS Please. As a newsletter author, may I say — please, please, please, put RSS feeds on your websites.
That’s it…
And that’s it for another week. Let me know what you thought, or if you have anything you’d like to share about the newsletter or management. Just email me or reply to this newsletter if you get it in your inbox.
Have a great weekend, and good luck in the coming week with your research computing team,
Jonathan
About This Newsletter
Research computing - the intertwined streams of software development, systems, data management and analysis - is much more than technology. It’s teams, it’s communities, it’s product management - it’s people. It’s also one of the most important ways we can be supporting science, scholarship, and R&D today.
So research computing teams are too important to research to be managed poorly. But no one teaches us how to be effective managers and leaders in academia. We have an advantage, though - working in research collaborations have taught us the advanced management skills, but not the basics.
This newsletter focusses on providing new and experienced research computing and data managers the tools they need to be good managers without the stress, and to help their teams achieve great results and grow their careers.
Jobs Leading Research Computing Teams
This week’s new-listing highlights are below; the full listing of 190 jobs is, as ever, available on the job board.
HPC Devops Lead - AstraZeneca, Cambridge or Macclesfield UK or Waltham or Gaithersburg USA or Gothenburg SWE
The Scientific Computing platform is a foundational capability to deliver HPC and scaled computing solutions for AstraZeneca’s R&D. Embedded within the Research D&A organisation it provides the backbone to domain-specific analytic products around computational chemistry, imaging, multi-OMICs, structural biology, data science and AI engineering. The successful candidate will promote DevOps engineering practices and technologies inside the scientific computing team as well as outside of the enterprise. The role is on the IC track. It is encouraged to spend 40/30/30 on hands-on development, and leadership activities like coaching, mentoring and driving the Platform Ops strategy.
Research Data Architect - Plant & Food Research - Science New Zealand, Aukland or Palmerston North or Christchurch NZ
We have a new and exciting opportunity in our Information & Knowledge Services team where you will be responsible for the development, design and implementation of Plant & Food Research's new data management framework that operationalises our Research Data Management Policy. Your extensive experience, ability to collaborate, and self-motivation will be essential in being the leader for the research, development, implementation, testing, and maintenance of IT solutions that support our data analytics and scientific computing platforms (which include Plant & Food Research's High-Performance Computing and MLOps environments). You will ensure that this aligns with the business and researcher's requirements, and platforms that enables our research mission.
Senior Product Manager - Q-Ctrl, Sydney AU or Los Angeles CA USA or Berlin DE
As a team made up of physicists and engineers through to our world leading product, design and marketing teams, our diverse experience leads to an incredibly impactful and creative environment. Q-CTRL is looking for an experienced Senior Product Manager to lead one of our emerging Products. Join a team that’s tackling the hardest problems in the world’s most impactful new technology – quantum computing. Q-CTRL builds software to enable customers to deploy the most effective quantum controls to suppress errors in their quantum hardware – combining modern product design and engineering with state-of-the-art quantum control techniques. This role will report into our Head of Product.
Senior Bioinformatics Scientist - Project Manager, Dept of Obstetrics, Gynecology, and Reproductive Sciences - UC San Diego, San Diego CA USA
Applies advanced computational, computer science, data science, and CI software research and development principles, with relevant domain science knowledge where applicable, to perform highly complex research, technology and software development which involve in- depth evaluation of variable factors impacting medium to large projects of broad scope and complexities. Designs, develops, and optimizes components / tools for major HPC / data science / CI projects. Resolves complex research and technology development and integration issues. Gives technical presentations to associated research and technology groups and management. Evaluates new hardware and software technologies for advancing complex HPC, data science, CI projects. May represent the organization as part of a team at national and international meetings, conferences and committees. Assists in the design, implementation and recommends new hardware and software technologies for advancing complex HPC, data science, CI projects. Acts as a project manager and may lead a team of research and technical staff.
Director Research Computing - Radiology - Washington University in St Louis, St Louis MO USA
Position manages the administration, support, operational, and developmental functions for Research Imaging Division facilities specialized computing systems and resources. Coordinates with Senior Director of IT regarding overall Department and University policies and procedures, standards, processes, and projects.
Technical Lead, Data - BenchSci, Remote CA or US or UK
We are looking for a Technical Lead - Data to join our growing Data team! Reporting to the Engineering Manager, you will evolve our data models, operationalize production-grade data pipelines, and contribute to our document mining/information retrieval initiatives as we expand our ability to extract valuable insights from scientific publications and databases. You will get to lead specific data projects that directly contribute to our client's understanding of drug discovery research. This is a fit for you if you excel at pulling meaningful insights from data, love making an impact and want to share your technical creativity and expertise with the folks around you. The technical lead role is a unique expansion of the scope of a Senior Data engineer that takes on multiple facets of technical leadership, team building, and defining our technical roadmap.
Euro-BioImaging Bio-Hub – Scientific Project Manager – AI4LIFE - European Molecular Biology Laboratory, Heidelberg DE
The successful candidate will be an integral part of the highly international and still young Euro-BioImaging Bio-Hub team at the EMBL in Heidelberg. The scientific project manager will have the opportunity to work collaboratively in a small but diverse team with expertise in imaging technologies, image data management and analysis, project management, communication and outreach, training, industry relations and science policy. The postholder will also work closely with the scientific coordinators of the AI4LIFE project, and various project partners.
Director, Scientific Applications - Purdue, West Lafayette IN USA
As the Director of Scientific Applications you will provide leadership for the support of computational science within Purdue’s campus cyberinfrastructure, and in support of the NSF-funded “Anvil” system. In collaboration with campus and national stakeholders, implement and oversee the strategic direction for research computing at Purdue. you will work extensively with the user communities to maintain the highest level of service and satisfaction through effective service delivery. Collect feedback on user needs, potential use case scenarios, and user priorities to be integrated in the future direction for computational resources. You will work closely with faculty members, IT leaders, and peers at other institutions, and assist the Executive Director of Research Computing with the operational oversight of Research Computing services including budgeting, resource planning and creation of policy, procedures, and standards
Director of Technology - The Carpentries, Remote
Candidates for this role should have demonstrated experience in managing technical projects and providing strategic direction. They should lead with empathy and value a team culture that emphasizes collaboration and effective communication. We seek candidates who are dedicated to the growth of The Carpentries team and ready to mentor their colleagues. Additionally, we seek candidates who have previous experience working for an open-source project or for a non-profit organisation, and candidates who understand the specificities of providing services and designing products for a large, diverse, and global community of volunteers. Experience hiring and managing independent contractors is also preferred.
SubChapter Bioinformatics Lead, NGS Algorithms Development - Roche, Santa Clara CA USA
We are seeking a talented and highly motivated Sub-Chapter lead for the Next Generation Sequencing (NGS) algorithms development team at the Director/Sr. Director level. The team supports development of Roche Diagnostics Molecular Assays, especially using NGS platforms, that will impact patient care globally. This position requires a broad experience developing NGS algorithms for multiple sequencing platforms and multiple clinical diagnostic assays for somatic oncology and inherited diseases. The candidate should have extensive experience developing NGS algorithms and analysis pipelines for RUO, LDT, and IVD assays for one or more disease indications and applications including NIPT, Inherited disease screening, Genetic disease testing, Somatic tumor tissue profiling, liquid-biopsy based cancer screening, and immune-repertoire profiling.
Manager - Research Software Engineering - Chan Zuckerberg Biohub, San Francisco CA USA
The Chan Zuckerberg Biohub has an exciting opportunity for an exceptional candidate to be our new Manager of Research Software Engineering (RSE). In this highly technical, hands-on role, you will form and lead a team of RSEs that will be focused on developing, optimizing, testing, and maintaining research pipelines and frameworks in multiple scientific domains such as genomics, proteomics, and image informatics. This role will be partnering with multiple teams across the Biohub to provide expert level software engineering support to research teams and applications that run across a variety of hardware.
Lead Bioinformatics Engineer - Volt (Recruiter), Remote UK
I'm working with a leading genomics research and healthcare company who are working towards bringing genomic healthcare to all who need it, alongside enabling new scientific discovery and medical insights by using their unique genetic code to help diagnose, treat and prevent illnesses to compare many people’s genetic code for new discoveries that continually improve genomic healthcare. This role is for a software engineers with extensive experience in bioinformatics to be responsible for developing and operating digital products aiming at solving a wide variety of bioinformatics needs and solving bioinformatics needs in genomic medicine by crafting production quality code
Deputy - Chief Information Security Officer for Research - University of Auckland, Auckland or remote NZ
We have a newly created role for a Deputy - Chief Information Security Officer. You will ideally be based in Auckland, but we are open to offering remote working options from within New Zealand. The purpose of this position is to work across three large entities, the University of Auckland (UoA), National eScience Infrastructure (NeSI), and Auckland UniServices Limited (AUL). You will be charged with leading a programme of work designed to enhance our cybersecurity capabilities via new systems, adapted processes and staff training improvement projects. You will also work to improve our reporting capabilities to highlight where we are now, where we are going and how we are tracking towards our targets.
Public Health Senior Research Scientist - ICF, Remote USA
ICF is a rapidly growing, entrepreneurial, multi-faceted consulting company, seeking a full-time Senior Research Scientist. This role will be part of our team working in support of CDC, NIH, SAMHSA, HRSA, private and nonprofit organizations, and state governments on a range of ongoing research and evaluation projects in the field of public health. A successful senior research scientist at ICF must be able to conceptualize and lead study methods, apply appropriate quantitative and qualitative techniques for data analysis, and synthesize findings from various sources for a range of audiences. A solid grounding and experience in public health, evaluation science, social science, or behavioral science is necessary
Quantum Services Offering Manager - IBM, Various US
IBM Quantum is looking for a Services Offering Manager to build our future quantum services offering portfolio including advisory, design, build and manage services. You will define differentiated offerings, assist with the offering enablement for sales, solutions and delivery teams and will collaborate across a network of IBM Quantum industry, research and systems experts to build upon and further accelerate IBM leadership in the market. Responsibilities include: Develop a differentiated market-leading value proposition based on deep knowledge of quantum computing and industry use case applications, emerging technology market, and the competitive landscape. Prioritize profitable and high growth industry and market segments for quantum services
Software Development Manager - Quantum Software - Xanadu AI, Toronto ON or Remote CA
Xanadu is looking for an experienced Software Development Manager to lead the Core Quantum Software team. The team is developing PennyLane, an open-source framework for quantum machine learning, quantum computing, and quantum chemistry. Although quantum software development experience is not required for the role, an advanced degree in physics, math or computer science is preferred.
Senior IT Research Software Developer, NeuroImaging and Surgical Technology Lab - McGill University, Montreal QC CA
The NIST lab is part of the Brain Imaging Center (the BIC) at the Montreal Neurological Institute (the Neuro), a multidisciplinary group studying the brain. The NIST lab has developed IBIS, an open-source image-guided surgery platform (http://ibisneuronav.org/) that is used in multiple labs to support world-leading research for image-guided surgical interventions in the brain, spine and other regions of the body. The Senior Research Software Developer creates, manages, and maintains software and technical infrastructure for the IBIS core platforms. Provide senior expertise in leading and setting direction for the IBIS technical development team in order to support world-class research in image guided surgery, working closely with remote developers and stakeholders.
Manager, Infrastructure and IT Security, Research Institute - McGill University Health Center, Montreal QC CA
Under the Research Informatics and Information Technology Division Director, the incumbent plays a vital role in collaborating with and providing support to the User community at the Research Institute of MUHC. He or she is responsible for designing, implementing and maintaining cloud services, shared services, and platform solutions to address complex business issues and provide technical leadership for the research community. The ideal applicant will thrive in a highly collaborative workplace and actively engage in the development process.
{kind=link}