Research Computing Teams #112, 5 March 2022
Hi!
My current job, like most of my previous jobs, include a lot of people who have worked for a long time in research — either as researchers themselves or in other roles, with Ph.D.s, or without.
I sometimes write about how working in research teaches us behaviours that are unhelpful when we get to management. That’s certainly worth calling out, but it’s only part of the story. Some of the behaviours and habits of mind we learn are extremely helpful, and we don’t even notice it.
In business management writing, you’ll see lots of discussion of “growth mindset” and “comfort with uncertainty”. These are real gaps they see in new hires and especially new managers. And yet it sounds like meaningless fluff to us, because we can’t even imagine it.
You don’t get into research, into the business of discovering completely new things about the world and the people in it, if you don’t believe people can grow their capabilities. You don’t go exploring if you’re uncomfortable not being sure about next steps. The frontier of current human knowledge is exactly where certainty stops. Searching out into the uncertain is a defining trait of people choosing a research path. And to be successful in that search, you have to grow your skills and trust that your colleagues can do the same.
So while “growth mindset” and “comfort with uncertainty” seem like empty phrases to us, they are high-achieving traits in other parts of the world.
Another skill is the ability to array and unify an entire team against a problem. “How are we going to…”. This is the basis of every research collaboration, and yet can be a new and foreign challenge to individual contributors in other sectors and industries who are in management for the full time.
Some of the other approaches we learn are prematurely developed advanced skills. These can actually hold us back a bit while we’re mastering the basics, but accelerate us when we’re growing responsibilities still further. The very collegial, consensus-building approach needed to get a multidisciplinary collaboration started and moving is exactly the sort of skills a senior manager or director needs to get buy-in across one or more organizations. We also need to learn the basic skills of being a bit more directive when needed while managing a single team. But the hardest part of mastering those basic skills is realizing that it needs to be done. They come down to a few easily learned behaviours. The shepherding of large collaborations is the advanced skill that we’ve already been sort of immersed of in research.
Where else have you seen (or been) research-trained folks struggle in management and leadership, and where have you seen research-honed skills shine? Let me know, by hitting reply or emailing me at jonathan@researchcomputingteams.org.
A note from #110 - when talking about my leaving my old job, and missed delegation opportunities, I glibly said “There’ll certainly need to be another hire - the team is losing a person’s worth of effort, after all.” A long time reader rightly called me on that:
Part of that transition and the elements delegated (documenting procedures, etc) would ALSO benefit from a review of what everyone else is/was doing, and what can be delegated to the floor. Just because someone leaves doesn’t necessarily require someone to be hired back in to keep an FTE count constant: volume of work could be going up, staying the same, or decreasing; assessing the work being done and asking “do we as a team need that task accomplished, or are we doing that because we did it before?”.
This is, of course, correct. It isn’t a given that the amount of work is fixed - that one person leaving means that there’s necessarily one FTE worth of work that needs to be done. Big events like people leaving are great opportunities to take stock and reprioritize. Maybe task X or project Y really should just be quietly shelved, at least for now. In our case, we had just gone through a prioritization exercise, getting focussed on some near-term goals and deliverables. After that we were more focussed but were still right on the cusp of thinking we should hire one more person. So in this case there almost certainly will need to be a new hire. But one shouldn’t just assume that’s the case.
With that, on to the roundup!
Managing Teams
Don’t Assume Consensus In The Absence of Objection - Candost Dagdeviren
Most people don’t like the conflict that comes with disagreement, and people especially don’t like disagreeing with their boss. Not hearing objections, particularly objections to something you’ve said, does not mean there’s no disagreement. It just means there’s no voiced disagreement.
So as Dagdeviren points out, you have to go out of your way to elicit disagreement. “What are things that could go wrong with this approach”, “what things does this miss”, “what are other things we could try” are all questions I tend to ask.
The good news is, it gets easier! As you continue to solicit (and react positively to) disagreement, after weeks and months of doing the same thing it will take less and less effort. People will be more comfortable raising issues. But in most teams, especially academic teams, you have to put the work in first to get there.
Gratitude Is More Powerful Than You Think - Chiara Trombini, Pok Man Tang, Remus Ilies, INSEAD Knowledge
Even in the with high levels of stress and overwork during the pandemic, simply expressing gratitude was enough to make a measurable impact on healthcare workers job (and even personal) happiness. This was especially true for doctors and nurses in this study who identified strongly with their job.
It is so easy to say thank you to your team members and give them positive feedback. It’s also really easy to forget to do so! As leads and managers our minds are often occupied with the problems and we forget to spend the moment it takes to give feedback on something done well or on time. We saw in an HBR article in #64 that there’s there’s no diminishing returns to positive feedback either, at any plausible level.
The 3 Ways Leaders Can Create Feedback Culture At Work - LifeLabs
LifeLabs has a very short illustrated ebook to view or download - there’s a button to give your email address but you don’t need to do so to look at or download the PDF. (As a general rule I don’t recommend even pretty good resources that end up with you on a mailing list)
This ebook talks about the benefits of leading with feedback, and modelling the desired behaviour. The key piece, on structuring your feedback, will give familiar advice to longtime readers; it’s very similar to manager-tools or Lara Hogan’s approach - asking if you can give some feedback, noting the behaviour, noting the impact, and ending with an ask for a change (if negative feedback). This model also has a preamble, “I wanted to share X because I think it will help us Y”.
It’s always good to review the basics, and giving good and frequent feedback is one of the most important things we can do as managers or leads. Worth looking at if you’ve felt your feedback needs some brushing up.
In general LifeLabs Learning seems to do pretty good work in the teaching-people-to-manage space. At some point I should give a quick review of their book, The Leader Lab. Their writing style is… very different than my preferred nonfiction writing style, and I expect others in research would likely have a similar first reaction. But once I get past that the information there is solid, and the basic ideas are organized into different components than I’ve seen before. It’s genuinely useful to see concepts presented in novel ways. They also focus on very specific behaviours which makes putting their lessons into practice easier.
Product Management and Working with Research Communities
The good, the bad and the tech strategy - Anna Shipman
We talk about strategy here a good deal. A great crash course is Richard Rumelt’s Good Strategy, Bad Strategy, after which you’ll recognize bad “strategy” documents littering the research landscape.
In this post Shipman shares a slide deck connecting the distilled central ideas of the book (she has a blog post expressing those ideas too) specifically to developing a technical strategy. The approach can also be applied to the strategy for a technical organization.
The first key point that Shipman emphasizes is Rumelt’s formulation of what a good strategy is - a diagnosis of the organization’s current situation, a vision of where to get to, and a coherent plan of action to get there. A good strategy focuses on one or two priorities, which means making hard choices.
The last dozen of Shipman’s focus on how that plays out for a technical org embedded within a larger organization. We can’t have a technical strategy without knowing what the larger org’s strategy is. We can’t have a sensible diagnosis or vision that’s not in formed by bigger-picture research priorities. That’s tough in academic settings, where the public strategy is, too often, “more of everything!” But VPRs or Deans or RIT CEOs typically do have specific near-term priorities that we can support. It could be growing computational research, it could be focussing on two or three growth areas, or it could be improving delivery. Either way it’s only in that context
Research Software Development
RSE Group Evidence Bank - UK RSE
This is an interesting collection of job titles and descriptions from a number of UK RSE groups for job levelling (junior/RSE/senior/head of RSE), soe articles on setting up RSE or data science institutes. Very interesting if you’re thinking of starting an RSE group. Hopefully it continues to grow.
The Biggest Mistake I See Engineers Make - Zach Lloyd
In theoretical research we tend to be trained to go off on our own and grind away for a while before returning with a partly-finished thing to show people. Lloyd reminds us that this is pretty much the opposite of what we need to be doing in tech. I’ve unfortunately learned this the hard way, as a team member (understandable) and as a manger (much, much less so).
Lloyd recommends showing people work as quickly as possible - like the next day - by breaking things up into small pieces. “Demo, demo, demo”. But another recommendation is at least as important - to define crisp deliverables with clear due dates. If that due date is “two weeks from now”, you now know the deliverable is too big and needs to be chunked down.
This is interesting - miniboss is a tool for composing applications out of docker containers with code - basically docker-compose but as a program not as a YAML file. From the README:
First and foremost, good old Python instead of YAML.
docker-composeis in the school of yaml-as-service-description, which means that going beyond a static description of a service set necessitates templates, or some kind of scripting. One could just as well use a full-blown programming language, while trying to keep simple things simple. Another thing sorely missing indocker-composeis lifecycle hooks, i.e. a mechanism whereby scripts can be executed when the state of a container changes. Lifecycle hooks have been requested multiple times, but were not deemed to be in the domain ofdocker-compose.
This seems like a decent idea for some use cases. I’ve seen a number of cases, from configuration to workflow definitions, where a static text file is fine for some uses but others really need a programming language for what needs expressing. Many simple apps need more than a static docker-compose file, but need much less than Kubernetes. I’ll keep an eye on this.
Research Data Management and Analysis
Database trigger recalculates totals, for data integrity - Derek Sivers
Database functions to wrap logic and SQL queries - Derek Sivers
It’s pretty common not to take full advantage of database capabilities, and that’s a shame. Modern databases are very powerful tools with rich capabilities - they’re not just fancy ways of storing a few CSVs.
In these two blogposts, Sivers talks about the importance of pushing logic that should wrap the data in with the data. In his words:
So that’s why I’m an evangelist now for how important it is to put your crucial code in the database itself. This is data logic (not “business logic”) and should be bound to the data.
In the first example he walks us through a simple postgres trigger for keeping aggregated data updated when new records are pushed (here, line items of invoices). In the second, he extends the first with functions to bundle particular items into a cart. Now this function can be called uniformly from any language, with consistent results.
Research Computing Systems
Australia’s NCI Adds Ceph Object Storage To Lustre File Systems - Daniel Robinson, The Next Platform
I expect to see this happening more and more often, but this is still so rare a thing as to be noteworthy. Robinson walks us through the NCI’s addition of a Ceph object store to their storage systems. The object store will be used on their large traditional Gadi HPC system, as well as by other users. NCI chose a commercially-supported version of Ceph for this their first self-hosted object system.
Initially the object storage is targeted at read-heavy workloads on static data sets (NCI hosts a lot of local .au copies of large datasets). Robinson quotes NCI staff calling out the lower cost (both in hardware and in people-time) and easier maintenance as reasons for the adoption.
I expect this to be a more common configuration. POSIX file systems are a wonder of tech, but they are hard to implement at scale. Since large HPC work does not require POSIX (e.g., MPI-IO doesn’t benefit from POSIX), object stores of one kind or another will slowly become more common. The rate limiting step is probably the updating of existing software. The desire to run codes natively on cloud computing systems will help accelerate some of that porting work.
The SSD Edition: 2021 Drive Stats Review - Andy Klein, BackBlaze
I have to admit, I started using Backblaze for backup principally because of the huge service they provide the community with their drive stats reports. They now are starting to get large enough numbers to issue SSD-specific drive statistics!
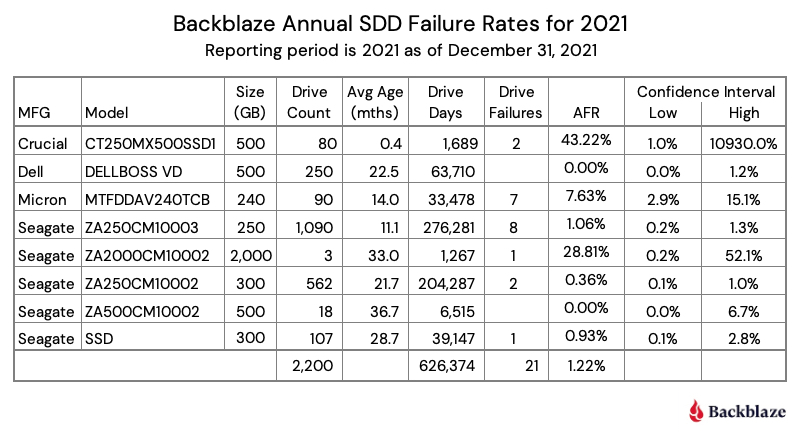
Interestingly, the roughly 1% overall SSD annual failure rate isn’t massively lower than the failure rate for similarly new HDDs (about 1.6%). We’re just starting to see large-N enough for confidence intervals tighten up, but we can already see that the Seagate 300GB drives seem significantly less likely to fail than their Micron 240GB drives.
I’ll look forward to this continuing to come out, so we can see lifetime effects and higher-confidence comparisons between manufacturers and drives.
Getting the best OpenFOAM Performance on AWS - Neil Ashton, AWS HPC Blog
I keep posting these How to Run [X] on AWS posts because they’re the best and most current information out there about what kind of resources codes in the wild actually benefit from. Being able to play with 5-10 instance types gives good, detailed understanding of the needs of these things at scale. These articles certainly help people using AWS, but they’re useful to the broader community as well. The AWS SA team should be commended for continuing to do the work, and then writing it up.
Here Ashton looks at both the meshing step (using the snappyHexMesh mesher that comes with OpenFOAM) and then the DICPCG solver. These two steps have very different requirements, and using the same instance type (and certainly number of instances) doesn’t necessarily make sense. Thus, Ashton looks at them separately, in the context of the large (35M cell) motorcycle simulation.
For meshing, which doesn’t scale well, a single AMD Milan-X based node is the cheapest way to generate the mesh, although using a few of those nodes or the 64-core Ice Lake intel nodes can get you there a little faster; similarly for the domain decomposition (where he finds the hierarchical decomposition method is uniformly better than scotch). I find it fascinating that the newest instances are the most cost effective and fastest.
The solver strong-scales quite well up to about 10 nodes on instances with EFA (e.g. high-speed networking), or up to about 750 cores depending on the node. Again, the Milan-X nodes out perform based on price, although you can just beat the speed with a few more of the Ice Lake nodes.
The article has several recommendations for running sizeable runs with OpenFOAM which seem sensible and well-motivated.
Emerging Technologies and Practices
Cloud-native, high throughput grid computing using the AWS HTC-Grid solution - Carlos Manzanedo Rueda, Clement Rey, Kirill Bogdanov, and Richard Nicholson, AWS HPC Blog
There’s not much doubt that commercial cloud providers have a huge advantage for bursty computing, and that spot pricing is very cost-competitive with on-prem for single-node jobs that can be restarted. So I’m surprised I haven’t seen more published reference architectures by cloud providers for high-throughput computing - a very common use case. You can of course run tools yourself HTCondor on the cloud, but they often won’t take advantage of managed infrastructure like databases (for job queues) or quick startup options like functions-as-a-service.
Here we see a walk through of a custom infrastructure for large numbers of HTC jobs for financial services; task definitions and payloads are fired off using a programatic SDK, data is staged into S3 and jobs are queued into DynamoDB, whence jobs are fired off into a pool of resources.
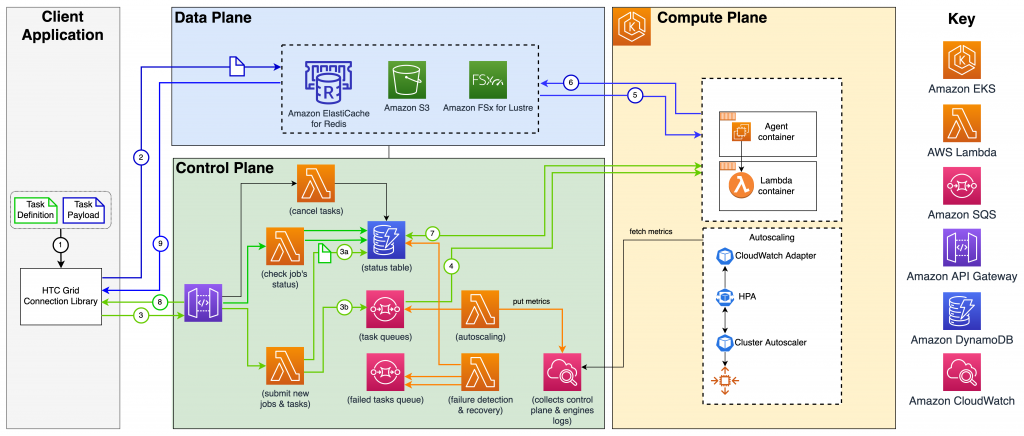
The setup here really is really set up for fairly homogenous jobs, but it’s open source and so can be modified for other job types (or one could share a pool of resources across several HTC-Grid ‘queues’ for different kinds of jobs). I look forward to seeing more setups like this; for those looking to bring cloud into a traditional research computing portfolio, this seems to be very low-hanging-fruit.
According to Chris Mellor at the pretty-well-connected Blocks & Files, Intel is still in the Optane game, planning to “enable our third-generation Optane Products with Sapphire Rapids”. This seems plausible given that the momentum around CXL, and I hope it’s true because I think a deeper memory/storage hierarchy would be a good thing for many applications.
Complex workload managers continue to get more and more important. Oliver Peckham at HPC Wire has a good short writeup about a recent arXiv preprint describing Microsoft’s ‘Singularity’ global scale AI training scheduler. Some pretty complex things are implemented in the resource manager, including checkpoint/restart preemption and migration, distributed barriers, replica splicing for time slicing of GPUs, and claim only a 3% hit in performance with their implementation. There’s a lot of nice scheduling ideas here, but sadly no code.
Random
The latest version of SQLite has significantly improved JSON functionality.
Want to join the iMessages group chat, but you’re being held back by your 68000-based classic Mac system? Messages for Macintosh is your answer.
I’m using Windows as my daily (work) driver for the first time since Windows 3.11 (which wasn’t much more than a DOS GUI). So I’m learning things about WSL and the like. Here’s a timely-for-me post on setting things up so you can SSH into WSL (including using Visual Code remote via SSH).
Play wordle entirely in C++ constexpr compilation errors.
…or using perl and cgi.
Speaking of Wordle, trying to compress the dictionary of 12,972 five-letter words in the delivered javascript is non-trivial; some simple approaches don’t work! Here’s a walkthrough of trying to compress Wordle’s dictionary using various methods.
Socket is an open source tool for protecting software from maliciously-modified dependencies.
Less sophisticatedly, here’s a way of visualizing module dependencies with cmake and graphviz.
The compelling, though mistaken, case against ligatures in programming fonts.
Speaking of - specialized programming typefaces are now mainstream enough that people are charging for them. Meet Berkeley Mono.
As the NSF XSEDE grant ramps down, the next funding and organization name will be Access. I understand the funder’s desire to evolve the emphasis and to be seen to be doing something new rather than just more of the same, but this periodic rebranding just isn’t helpful for researchers.
Interesting tracker for keeping track of job applications - huntr.co.
JupyterLite (the compiled-to-WASM, in-browser version of Jupyter which we were talking about here in #77) has become so mainstream that several of the demos on the official Try Juptyer page now use JupyterLite instead of binder.
If you use gmail for work you can use multiple inboxes to keep things organized.
That’s it…
And that’s it for another week. Let me know what you thought, or if you have anything you’d like to share about the newsletter or management. Just email me or reply to this newsletter if you get it in your inbox.
Have a great weekend, and good luck in the coming week with your research computing team,
Jonathan
About This Newsletter
Research computing - the intertwined streams of software development, systems, data management and analysis - is much more than technology. It’s teams, it’s communities, it’s product management - it’s people. It’s also one of the most important ways we can be supporting science, scholarship, and R&D today.
So research computing teams are too important to research to be managed poorly. But no one teaches us how to be effective managers and leaders in academia. We have an advantage, though - working in research collaborations have taught us the advanced management skills, but not the basics.
This newsletter focusses on providing new and experienced research computing and data managers the tools they need to be good managers without the stress, and to help their teams achieve great results and grow their careers.
Jobs Leading Research Computing Teams
This week’s new-listing highlights are below; the full listing of 160 jobs is, as ever, available on the job board.
Senior Scientific Manager - DNA Pipelines - Wellcome Sanger Institute, Hinxton UK
Here at the world-famous and internationally respected Wellcome Sanger Institute, we have an exciting opportunity for a highly experienced Senior Scientific Manager to join the DNA Pipelines Research and Development (DNAP R&D) team. Manage a team of experienced scientists to deliver project work for the development and improvement of existing and novel sample preparation and nucleic acid sequencing technologies. Work with the Head of Technical Development, contributing to strategic thinking, project prioritisation and resource allocation. Initiate and manage collaborations with members of scientific programmes and operational teams to ensure that the correct workflows are being delivered to agreed schedules and specifications.
Senior Research Infrastructure Developer, Centre for Advanced Research Computing - University College London, London UK
The UCL Centre for Advanced Research Computing (ARC) is UCL’s new institute for infrastructure and innovation in digital research - the supercomputers, datasets, software and people that make computational science and digital scholarship possible. A Senior Research Infrastructure Developer will be responsible for designing, building and maintaining the computational software and infrastructure that drives UCL’s research. They will build both persistent services with large numbers of users, and also bespoke solutions for specific research groups.
Superconducting Hardware Manager, National Quantum Computing Center - UK Research & Innovation, Didcot UK
A purpose-built National Quantum Computing Centre will be built and operated by UKRI at the Science and Technology Facilities Council (STFC) campus in Oxfordshire. The Centre will be open and operational by December 2022. Until then, the NQCC’s activities are taking place in other facilities on the Harwell Campus or at partnering institutions. The NQCC will sit alongside other departments within the STFC National Laboratories and will be part of the broader National Quantum Technologies Programme (NQTP).
Senior Director, Academic & Research Computing - Rush University System for Health, Chicago IL USA
The Senior Director, Academic & Research Computing is accountable for the strategy, leadership, direction, and delivery of ongoing operations of the systems and technologies used by the University and Research communities. Manages large complex projects and programs. Coordinates both team member and manager resources to meet IS and implementation team’s strategic goals. Drives strategic planning for new IS facilities to optimize organizational design and effectiveness. Provides innovative solutions to complex issues that integrate the facility transformation program with IT strategic direction.