Research Computing Teams #109, 11 Feb 2022
Hi!
A slightly short newsletter today, as I finally claw my way back onto the Friday schedule.
One community update from last week - there was a fair amount of interest in using the Rands Leadership Slack as a pre-existing place with a large (>20,000!) leadership and management community as a place to discuss topics of interest. There is now a #research-computing-and-data channel, with sixteen members so far - some newsletter readers, but also some who had already been on rands and quickly joined once the channel was created. If that sounds potentially of interest to you, we’d love to see you there!
Otherwise this week I’ve mainly been continuing to offboarding myself from my current job. The coming week is my last (and I think the final 1:1s are going to be tougher than I was anticipating). Most of the knowledge transfer has now been done — although to wrap it up, next week I’m giving a demo of a key piece of technology to the team. Manager does a demo! What could possibly go wrong? This week there’s been a lot of 1:1:1s, with a team member and either I and my replacement, or the replacement and our boss, about transfer of responsibilities or “what’s next” conversations.
One thing I’ve been doing in my last two one-on-ones with team members is going over our work together, and putting together letters of reference which then get also turned into LinkedIn recommendations. Hopefully the team members will stay happily part of the team for a long time to come, but being a reference is a key responsibility of a manager or supervisor, especially in academia, and I want to make sure that I get these things written up while our work together is fresh in our mind. Having a record from previous quarterly reviews and one-on-one meetings is a huge help in putting these letters together. Also, routinely distilling information from those meetings into the cover sheet of the one-on-ones was a huge help when handing over managerial responsibilities to my replacement.
Like so many things in management, the preparation that is making this handover easier — one-on-ones, quarterly reviews, keeping meeting notes, distilling them every so often — was not difficult, complex, or even very much work. It just took a bit of discipline to keep routinely doing the little tasks that help things run smoothly. And that, after all, is all professionalism is. Our team members and our research communities deserve research computing and data teams that are managed with professionalism.
So, what’s next? As you know, supporting research computing and data teams in their work to, in turn, support research, is very important to me. Starting Feb 21st, I’ll be doing just that but from the vendor side of things; I’ll be a solution architect for NVIDIA (and the second NVIDIAian I know of on the newsletter list - Hi, Adam!). After five and a half years working on single project, I’m really excited to be working with a large number of research groups and teams again - a bit like my work from long ago at an HPC centre, but wearing a different hat. I’m a bit nervous about the different expectations and pace of the private sector, but genuinely pumped to be playing with a large number of different technologies to support groups trying to tackle a large number of different problems.
What does this mean for the newsletter? Not a lot of change, really. NVIDIAs policy on social media (including newsletters) is very reasonable; the changes are really going to come from me wanting to be (and be seen to be) even-handed and balanced.
I’ve been steering away so far in 2022 from commenting on specific new technologies coming out, to see how that goes; and the newsletter is actually better for it. There’s a zillion places you can go for the latest “speeds and feeds” update; that’s not what this newsletter has ever been about, even though it would slip in sometimes. So there won’t be any conflict of interest around new or updated product announcements; they won’t really come up here.
If there is some item that in some way is related to NVIDIA that I think is genuinely important for our community to know about, I will link to it in the roundup, preferably an article from a third party, but will refrain from commenting on it; and I’ll go out of my way to make sure any such links are balanced by related links touching on news from other vendors. But I expect that to be a pretty rare occurrence.
Other than that, I’ll probably have some kind of disclaimer in the newsletter — Jonathan works for NVIDIA, but opinions expressed here etc etc — but there won’t be drastic changes.
And with that, on to the roundup!
Product Management and Working with Research Communities
What is the cost of bioinformatics? A look at bioinformatics pricing and costs - Karl Sebby
This article is important to ponder even if your team’s work falls completely outside of bioinformatics.
Service delivery models gets very little discussion in our community despite its importance. That’s a shame! It’s a pretty key part of how we interact with research groups. The delivery model determines how easily communicated and sustainable providing the service is, even if there isn’t any kind of cost recovery. How the service is delivered is a key part of the service itself.
Here Sebby investigates the variety of delivery models and prices for the analysis of next-generation sequencing data. This is a pretty specific kind of problem, typically with a clear underlying task and well-defined best practices, and yet it’s still an interesting example. There is both the compute cost and the people-time cost, and it requires expertise and close interaction with the research group.
Even with this extremely well-scoped offering, there are at least four different delivery models described:
- Bespoke work negotiated per project with hourly rates for people time, and “pay-as-you-go” compute/storage
- Productized service; e.g. $150/sample for a single whole genome sequencing sample, or even a subscription service for samples
- Set up some infrastructure for the research group (e.g. the galaxy workflow environment), charge for the node, and let the group run the workflows
- Sell access to a platform (e.g. the model of DNAnexus, Seven Bridges, etc - and even within this group there are different business models)
There are pros and cons to each approach; they appeal to different potential clients, who have different expectations and different kinds of expertise available internally. The hourly rate is safest for the service provider, but is riskier for the client (how do I know how much will this cost in total?). “Productized service” is easiest for the casual researcher to understand, and transfers some of the risk to the service provider (what if this sample’s data is especially low-quality and takes longer to process?). On the other hand this approach makes it much easier to “sell” a large number of the services, and over time it should average out. Set-up-some-infrastructure is nice and readily automated for the service provider; it’s more work for the researcher but may make a lot of sense for a group that has many samples to run and its own internal expertise. And if your group was doing a lot of similar tooling setup for a lot of different clients, it might make sense to become a platform of some sort.
To be clear, this sort of service design thinking does not hinge crucially on money being charged to cost centres. How researchers know what you can do for them, how that work is packaged up into deliverables, and how do they know what it will ask of them in terms of effort and turnaround time are important questions to work through even if the service is “free”.
And if it’s not free, look at that range of prices and rates quoted - productized services for the same service range by factors of 2-3, in one case 7x; hourly rates vary by a factor of 6. And yet all of these service providers are going concerns. Maybe always being the cheapest option available isn’t the only feasible choice?
Has your team put some thought into different approaches to service delivery? Different “business models”, whether or not money changes hands? What did you consider, and how did it go? Let me know - email at jonathan@researchcomputingteams.org, or just hit reply.
Managing Teams
Prioritization, multiple work streams, unplanned work. Oh my! - Leeor Engel
Engineering managers: How to reduce drag on your team - Chris Fraser
Research computing shares with smaller, newer organizations like startups a very dynamic set of demands, requirements, and work. This distinguishes both from work in teams at many large mature organizations or in IT shops. The dynamism makes prioritization and focus especially important.
Engel describes some principles for managing work in such a dynamic environment:
- When everything is important than nothing is important - prioritize, prioritize, prioritize
- Pareto principle: what’s the most important/tricky 20%?
- Finish what you start first - (I, not uncommonly in our field, struggle with this one)
- Reduce uncertainty as soon as possible - do experiments and proofs of concept and expect a bunch of them not to pan out
- Reduce context switching by having team members on one or maybe two streams of work
Fraser’s article is superficially on a completely different topic. We’ve talked before (#39, #76) about how the key to speeding teams’ progress isn’t about urging them faster so much as removing things that make them go slower. But key items Fraser points out that cause drag are the same things Engel urges us to work on:
- Reduce context switching (reduce streams of work)
- Improve communication and clarify goals
Other items - improve trust with regular one-on-ones, and implement the tooling the team needs - are the bread-and-butter of management work.
Levels of Technical Leadership - Raphael Poss
Management is hard, and time consuming, and takes one away from hands-on work. Not everyone wants to do it, even as they grow in their careers.
It’s becoming common understanding, even in academic circles, that there’s a need for a technical individual contributor career ladder — a path for growing in technical responsibility and impact without taking on people management responsibilities.
But there’s an ambiguity there. Management, for all its challenges, has the clarity of a career step-change. HR records someone as reporting to you, or they don’t; more bluntly, you can fire someone or you can’t. There’s no gradations of in-between. What does “increasing technical responsibility” look like?
If your organization doesn’t have such a track yet, or is reconsidering one, this article by Poss gives a nice overview. It explains how the analogue nature of “increasing responsibility” allows for organically increasing responsibilities over time. There is a career ladder with expectations, which is consistent with what is described in this paper and blog post (mentioned in #94) summarizing how NCSA, Notre Dame, and Manchester’s RSE groups work or plan to work.
The stay interview is the key to retention right now. Here’s how to conduct one - Michelle Ma, protocol
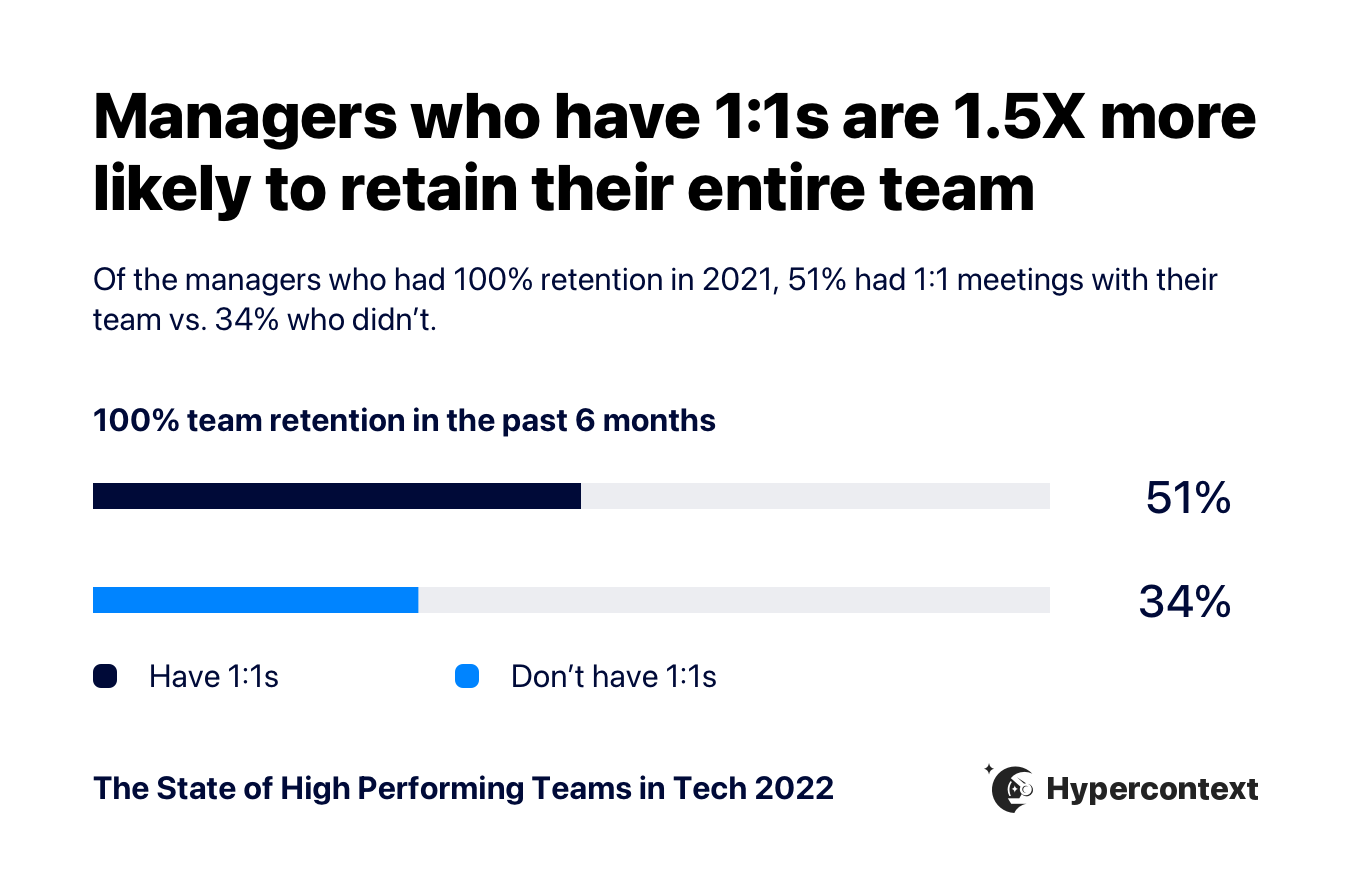
The State of High Performing Teams in Tech 2022 - Hypercontext
We’ve talked a little bit about the challenges of retaining team members these days. Most of us haven’t seen a huge exodus, but I’ve certainly seen several key members of various teams move in the past couple of months, including one on our own.
In the first article, Ma talks to Amy Zimmerman on “the stay interview” - kind of an exit interview, but while your team member is still with you. Why wait until your team member leaves to find out what was wrong?
Keeping track of how happy people are and what they’d like to be doing is a good topic to routinely bring up in 1:1s and quarterly reviews (#68), but Zimmerman goes a little deeper with some of the questions:
- “What's your favorite and least favorite thing about working at Relay?”
- “What might tempt you to leave?”
- “If you could change something about your job, what would it be?”
- “What talents are not being used in your current role?”
- “What should I do more or less of as your manager?”
Some of the others should really come up in first one-on-ones (Laura Hogan has a good set of first 1:1 questions), but are good to keep coming back to.
It may feel scary to explicitly bring up questions like “what might tempt you to leave”, but the fact is your team members are almost certainly not going to retire from their current job with you. The more frankly and frequently you can have these career direction conversations, the longer you’ll be able to align the work they do with their personal goals.
In the second article, the folks from Hypercontext did a survey on high-performing tech teams, and there’s some good stuff in there, most of which won’t be surprising to long-time readers of the newsletter (routinely communicating goals and expectations is important, managers are useful but only if they’re run well, more junior people and people from groups that are not overrepresented are less likely to be comfortable speaking up in meetings).
Key to this discussion, though, is the important of one-on-one meetings on retention. Managers who have one-on-ones with their team members do a significantly better job of retaining their staff.
Research Software Development
Code that Doesn’t Rot - Maxime Chevalier-Boisvert
Chevalier-Boisvert points out the problem of “standing on the shoulders of giants” when it comes to writing code:
How much time do we collectively waste, every year, fixing bugs due to broken dependencies? How many millions of hours of productivity are lost every single day? How much time do we spend rewriting software that worked just fine before it was broken?
Back at the start of the 90s when I was in undergrad (yes, yes, I know) we were taught to write code to be “modular and reusable”. At the time, taking advantage of reusability basically never happened because sharing and discovering code was so hard. Here in the 20s, reusing shared modular code is absolutely routine, and — well, it turns out to be a bit of a mixed bag!
Chevalier-Boisvert gives good advice about trying to reduce unnecessary breakage: pinning dependencies; minimal software design (a la “do one thing well”); and VMs of various sorts with minimal APIs and requirements.
This is all good advice, and reducing dependency on unnecessary APIs and libraries can increase the productivity of downstream users. I’m wary of recommending this advice at the early stage of research software development, though, for a couple of reasons.
First, focussing solely on productivity: reducing use of dependencies can reduce the productivity of the developer, too. And since “Early stage” research software typically ends up having very few downstream users, trading developer productivity for user productivity can be a bad trade initially.
More controversially: higher productivity is good, and I’m in favour of it, but mere efficiency isn’t the most important reason for sharing research software. Being able to immediately run someone else’s code is awesome, but the thing that makes it science is being able to see and understand and reimplement the methods. That means making code available, sure, but also extremely clearly written documentation and methods sections (e.g. “Quantifying Independently Reproducible Machine Learning” in #12). So I’m skeptical of anything that slows down the development and open-source sharing of research software prototypes, even good things like spending time to make it robust.
As a piece of research software starts to inch up the technology readiness ladder and become a tool that people (even you!) start using, then the productivity of users weighs more heavily, and tradeoffs start changing. At that stage of development Chevalier-Boisvert’s advice becomes extremely important! It’s just worth being clear at what stage of development each product is.
Research Data Management and Analysis
startr - A template for data journalism projects in R - Tom Cardoso & Michael Pereira, Globe and Mail
There’s nothing startling in here, but I just continue to be amazed that the once-niche field technical computing and computational data analysis is now a field where newspapers post their open-source tools for template data analysis project structures. The Associated Press also has one, as does the UK civil service.
I will say that if you’re looking to teach a data analysis class, this is a pretty good one to look at. There’s a bit of a tutorial on a good data analysis workflow (raw data is immutable, write in pipelines, use tidy verse tools) and a number of small but useful utility functions.
Research Computing Systems
After lying low, SSH botnet mushrooms and is harder than ever to take down - Dan Goodin, Ars Technica
A nice if somewhat discouraging overview of FritzFrog, an SSH botnet that’s unusually stealthy - it’s peer-to-peer (no easily spotted traffic to a central CnC server), there are 20 recent versions of the binary, is apparently smart enough to avoid infecting low-end systems liek Raspberry Pis, and payloads stay in memory and never land on disk. It’s not new, and has been around for two years, but has exploded in the past couple of months.
It listens on port 1234, scans constantly for open ports 22 and 2222, and proxies requests to local ports 9050, so it’s possible to detect based on network traffic. And, inevitably, some infected nodes start crypto mining, which at least is easy to spot from weird CPU + network usage. There’s a longer post here by Akamai, with a simple detection script.
Random
An optimization story of calculating a absorption spectra. Would be very curious to see how using numba and/or JAX improved the Python implementation, as for instance here with numba.
Spin up a Galaxy instance for genomic data workflows on Azure.
Firefox - like, firefox the browser - had an outage in January. Here’s a nice retrospective, and an example of how to communicate with users after things have gone badly wrong.
I can not recommend this highly enough - is your inbox too full? Just archive it all. Add an “inbox_2021” label if it’ll make you feel better. It’ll still be there and searchable and responses will still show up in your inbox.
Nice tutorial for some intermediate git (rebase, amend, log) specifically in the very concrete context of contributing to a project via github/gitlab.
Caching is hard. A decade of major cache incidents at Twitter.
Database performance is also sometimes hard. Debugging a suddenly appearing performance problem with a Postgres query.
Selecting the most recent record in Postgres - group by vs lateral join vs timescale DB vs index scan vs triggers. Also, the guts of how postgres stores rows.
Writing as idempotent as possible bash scripts.
A comparison of six ways to package Python software.
That’s it…
And that’s it for another week. Let me know what you thought, or if you have anything you’d like to share about the newsletter or management. Just email me or reply to this newsletter if you get it in your inbox.
Have a great weekend, and good luck in the coming week with your research computing team,
Jonathan
About This Newsletter
Research computing - the intertwined streams of software development, systems, data management and analysis - is much more than technology. It’s teams, it’s communities, it’s product management - it’s people. It’s also one of the most important ways we can be supporting science, scholarship, and R&D today.
So research computing teams are too important to research to be managed poorly. But no one teaches us how to be effective managers and leaders in academia. We have an advantage, though - working in research collaborations have taught us the advanced management skills, but not the basics.
This newsletter focusses on providing new and experienced research computing and data managers the tools they need to be good managers without the stress, and to help their teams achieve great results and grow their careers.
Jobs Leading Research Computing Teams
This week’s new-listing highlights are below; the full listing of 139 jobs is, as ever, available on the job board.
Head of Research Software Engineering - University of Exeter, Exeter UK
We are seeking an experienced leader to head up our Research Software Engineering (RSE) Group. RSEs will make a vital contribution to the University’s research portfolio by developing and applying professionally usable software tools to address real-world data science, modelling, simulation, and other challenges across the spectrum of computational and social science. The successful applicant will be an experienced, highly motivated, professional software developer with up-to-date skills and background in working with research data. They will have experience of leading and managing a team of RSEs and a demonstrable track record of innovation in research software engineering. Prior experience of working as an RSE within a research environment is desirable.
Scientific Data Manager, Discovery Platform - Recursion, Salt Lake City UT USA
Recursion is a clinical-stage biotechnology company decoding biology by integrating technological innovations across biology, chemistry, automation, data science and engineering to radically improve the lives of patients and industrialize drug discovery. You will be responsible for the integrity of the diverse and innovation-enabling experimental datasets for the world’s leading tech-driven drug discovery platform. You will work with peers across the company to grow Recursion’s capabilities in experimental design, data management, processing and visualization
Senior Data Infrastructure Engineer - Recursion, Toronto ON CA
Recursion is a clinical-stage biotechnology company decoding biology by integrating technological innovations across biology, chemistry, automation, data science and engineering to radically improve the lives of patients and industrialize drug discovery. You'll be on a team responsible for building, operating, and tuning a data platform that allows users to discover and query across the breadth of our data at Recursion, which includes a chemistry library of 3 billion compounds, nearly 8 PB of cellular microscopy images taken in 10s of millions of different experimental contexts involving 1 million different reagents, sparse bioassay data across approximately 48 drug discovery & development programs, and more. The data platform your team implements will be a key piece of a research platform that supports the generation and storage of petabytes of data, fast iteration of novel analyses, and rapid prototyping of new deep learning models.
Principal Research Computing Engineer - Boston Children's Hospital, Boston MA USA
Providing routine as well as leading edge support to our research community by applying advanced informatics tools, methods and technologies in support of computational biology; with minimal supervision and direction, delivering technical solutions that meet users’ needs in the required timeframe, prioritizing effectively for assigned scope of work; applying acquired expertise to analyze and solve technical problems without clear precedent; providing technical guidance to employees, colleagues and customers; delivering a high level of customer service as per agreed upon metrics.
Routinely leading, co-leading or participating in complex biomedical projects with other members from the BCH research community; setting goals and objectives for projects and demonstrating achievement of those goals and objectives; coordinating work activities with other stakeholders; contributing to resulting manuscripts and presentations.
Senior Technical Program Manager – AI/ML Architect - Azure, remote USA
Our team is part of Azure Engineering and focuses on in-bound product feedback born from hands-on customer engagements. This is an exciting time for HPC + AI, as they are undergoing a massive shift. AI technologies are being merged with existing HPC approaches, and both are moving to the cloud. At this critical juncture, the team is expanding its HPC and AI Specialized Workloads team and is looking for architects with a strong background on running and optimizing AI training and inferencing workloads at large scale [think Supercomputer Scale]. Azure Global works closely with important customers, ISVs and system integrators on some of the largest and most interesting development projects for Microsoft. From these engagements, the team extracts patterns, issues, and requirements that help drive positive change in our platform and product offerings.
This role is fully remote, and successful candidates can come from anywhere within the US. Travel would eventually be 10-20% and require ability to work remote.
Senior Software Engineer/Lead (Europe - Remote) - Tumult Labs, remote EU or Zurich CH
individual privacy. Powered by the proven science of differential privacy, and building on decades of groundbreaking privacy research by our founders and scientists, our platform gives institutions the clarity and control to manage sensitive personal data at enterprise scale. We are looking for an Engineering Lead to expand our team in Europe. You would be our second hire in this region and the first one in an engineering role. You would be taking an active role in hiring and onboarding software engineers and helping grow the resulting team. Depending on your interests, you could, over time, grow as an individual contributor or focus more on engineering leadership.
Manager, Data Sciences - Cargo - Air Canada, Dorval QC CA
Do you want to become part of the Analytics team in the fast-growing Cargo branch at Air Canada? The Cargo Analytics Team aims to provide best in class analytics, predictive and prescriptive solutions to our internal stakeholders. Increasing the customer experience by empowering our colleagues to have the right information at the right time to make business decision is our key objective. To support and enable the growth, we are looking for a Manager Data Sciences that will help us discover and deliver the strategic insights hidden in vast amounts of data. You will be leading the Data Science discipline in the Cargo Analytics team and delivering insights driven analytics to the Cargo branch by using the best analytics solutions and techniques.
Senior Research Software Engineer - Imperial College London, London UK
This role presents an exciting opportunity to join the growing community of Research Software Engineers (RSE) at Imperial College via its core team within the Research Computing Service (RCS). The RCS encompasses a dedicated team of RSEs, a managed High-Performance Computing (HPC) facility; and provides a range of training for the HPC users and researchers. The mission of the RSE Team is to increase the quality, impact and sustainability of the research software developed at Imperial, supporting the College in enhancing its world-leading research outputs. The RSE team has been in place for four years and has worked on dozens of projects across all faculties of the College. You will actively participate in research by providing advice on the application of technologies and delivering software development projects. You will contribute by developing innovative software, promoting good software engineering that ultimately accelerates research and by mentoring less experienced developers
Software Engineering Manager, Extreme-Scale Computing - Intel, Hillsboro OR USA
We are looking for a manager for a team of 5+ engineers who develop software for advanced computer architecture pathfinding and applied research. The team develops SW stacks from the ground up for novel architectures, testing those SW stacks on FPGAs and prototype hardware and porting SW applications frameworks to the new architectures. As a manager, you will set priorities for the team, get results across boundaries, ensure an inclusive work environment, develop employees, and manage performance. You will also provide architectural and technical guidance, and ensure that sound engineering practices are followed.
Assistant Director, Scientific Applications, Anvil - Purdue University, West Lafayette IN USA
As the Assistant Director of Scientific Applications, you will provide leadership in the support of computational science within Purdue’s campus cyberinfrastructure, and in support of the NSF-funded “Anvil” system. In collaboration with campus and national stakeholders, implement and oversee the strategic direction for research computing at Purdue. You will work extensively with the user communities to maintain the highest level of service and satisfaction through effective service delivery, collecting feedback on user needs, potential use case scenarios, and user priorities to be integrated in the future direction for computational resources. As well as working closely with faculty members, IT leaders, and peers at other institutions. Assist the Executive Director of Research Computing with the operational oversight of Research Computing services including budgeting, resource planning and creation of policy, procedures, and standards.
Manager, Research Software Engineering - Princeton University, Princeton NJ USA
The Research Software Engineering (RSE) Group, within Princeton Research Computing, is hiring a Manager of Research Software Engineering. You will report to the Director of Research Software Engineering for Computational and Data Science. In this position you will build and lead a growing team of Research Software Engineers who provide dedicated expertise to researchers by creating the most efficient, scalable, and sustainable research code possible in order to enable new scientific advances. You’ll oversee and encourage the professional development of the research software engineers by engaging with the broader research community, and find ways for them to give back by providing training workshops and/or participating in conferences. Finally, as part of the RSE management team, you will contribute to the strategic vision and mission for Research Software Engineering at Princeton.
Director of Research Computing - OVPR - Carnegie Mellon University, Pittsburgh PA USA
This role will serve in a senior leadership capacity for both the Office of the Vice-President for Research (OVPR) and the Office of the Chief Information Officer (OCIO). This leadership role requires proven management and leadership skills with exemplary communication skills to act as a research computing evangelist across the university’s colleges and programs. In the first twelve months in the role, the Director will be expected to work with a committee of academic and administrative designates to understand computing and data needs, current practices, and opportunities for all of the university’s colleges and programs. From there, the Director will be tasked to work with the committee and leadership to charter, build and maintain the needed service offerings, funding model(s), resourcing plan, and technology roadmap for the program to help all constituents meet their research computing, data, and security requirements. The successful candidate will have proven abilities to manage several operations simultaneously while effectively setting priorities to achieve defined goals.