Research Computing Teams #104, 11 Dec 2021
Hi!
There seems to be something in the air - in the past week I’ve had or heard a number of conversations around leadership and managmement.
Leadership vs management is a fun conversation to have in the same way that “is a hotdog a sandwich” is a fun conversation; it can clarify your own thinking but is unlikely to change too many minds.
Still, I think the basic outlines are clear and well agreed on. Management is a specific set of skills and activities particularly useful in particular jobs — people management especially, but also product or project management. It’s a woefully under-appreciated set of skills and behaviours, especially in academia-adjacent areas, and that means that you you can get significantly better at it than most peers pretty easily. By caring enough about it to subscribe to a newsletter, gentle reader, you’re already comfortably in the top 50%.
Leadership is broader; it is a set of skills that enable getting stuff done when a number of people are required. And almost anything of any import at all requires the contributions of a number of people.
In this newsletter, we tend (naturally) to think of leadership within research computing teams. That’s good and useful, essential to helping those teams perform effectively. But as we get ready to face the opportunities 2022 brings, it’s worth thinking about external leadership, the leadership that research computing teams neessarily exert within their research communities.
Leadership is at its most basic a catalyst to getting things done. And research computing, by the nature of it’s enablement role supporting research, has an outsized ability to shape what gets done very fundamentally — by changing what is possible to do.
When we focus on service to research, it’s all too common — for ourselves and others — to adopt a mental model where the research drives, and that research computing necessarily follows dilligently behind in the direction given. But as soon as we type or read those words, the illusion disappears; that’s obviously just not the case. Research computing is in the service of research, but as research computing advances, different areas of resarch suddenly become more feasible. Rather than one trailing the other like baby ducks following a mother, the two disciplines are dancing together, cutting captivating but unpredictable paths across the dance floor.
Even if we tried to avoid it, research computing would play a leadership role in research. It is only one of many leaders, only one of factors driving new directions, but it has a leadership role nonetheless. And knowing that leadership role exists, we’re obligated to be responsible with it, to keep our eyes on new capabilities that could help our research communities advance.
This newsletter began because research computing teams are too important, as individuals and as groups, in their own right and in their role supporting research, to be managed with anything less than the professionalism they deserve. In countless ways in the last two years we’ve seen where current research computing capabilities made research and policy responses possible where ten years ago they wouldn’t be. This is too big a responsibility to treat lightly.
On that note, this will be the last newsletter of 2021; we’re all super busy to get things wound up before the holidays (which is why, I’m afraid, the last three issues have been late) and to get the new year off to a good start. This community has had 73 research computing team managers and leaders join since January; it’s been terrific hearing from so many of you over the past year, who have taken the time not just to read these very long newsletters but also to write back. Feel free to let me know what you’d like to see in 2022, anything you’d like changed in the newsletter, questions you’ve been wrestling with, or anything else you care to share.
For now, on to the last roundup!
Managing Teams
Learning from Success and Failure - Robert I. Sutton, HBR
The end of the year is a time of reflection for teams, and it’s always good to think about how to do this constructively.
This is an old article, but I think timelessly relevant. We tend in retrospectives - either after a sprint or at the end of a year - to focus on and try to learn from the things that didn’t go well. That’s good and useful. But it’s not all we should be learning from.
Sutton reports on research specifically from US Army teams, but the work has been reproduced elsewhere (firefighters, companies including tech companies like Cisco, and more), on retrospectives. Crucially, teams that do retrospectives on both events that went well and that went poorly, and focus equally on both, learn faster and do better.
This makes sense - there’s a million ways things can go poorly, and only a few that can turn out well, and if you squander the opportunity to focus on what went well then you’re throwing out tonnes of useful data.
From one of the papers:
Then, two months later, these same two companies went through two days of navigation exercises. The results showed that, although substantial learning occurred in both groups, soldiers who discussed both successes and failures learned at higher rates than soldiers who discussed just failures. Soldiers in the group that discussed both successes and failures appeared to learn faster because they developed “richer mental models” of their experiences than soldiers who only discussed failures.
Hiring (and Retaining) a Diverse Engineering Team - Gergely Orsoz, Sarah Wells, Samuel Adjei, Franziska Hauck, Uma Chingunde, Gabrielle Tang, and Colin Howe
Hiring a diverse team, especially in research computing, is not the default. As empirical evidence, I offer… gestures widely. Therefore, default processes won’t get you there.
With that the case, and because there’s moral and effectiveness imperatives to making sure you’re not excluding good candidates from opportunities on your team, then you need to change how the processes play out, which means change management. And the thing about change management - like anything in management, really - is that it requires sustained effort and attention to the basics.
In this post, Orsoz hands the keyboard over to six leaders who have built successful and diverse teams. Their stories aren’t easily summarized, and many of them apply to larger organizations than our own (although could easily be adopted by our institutions), but the basic idea of having a goal, making sure the steps you are taking are consistent with that goal, and maintaining that sustained effort are key.
How to make accountability a core part of your workplace culture - Hiba Amin
We’ve talked before about how what makes a team a team, as opposed to just a bunch of people with logins to the same slack, is mutual accountability. Team members job satisfaction is heavily influenced by being able to rely on their fellow team members, and good team members are happy to be able to be relied on.
Amin summarizes some areas to focus on to increase the level of mutual accountability within your team:
- Lead by example, holding yourself accountable first (honestly, a lot of research computing team leads and managers I’ve seen are quite good at this, probably better than in other sectors)
- Set team goals (also generally pretty good)
- Give good feedback (this is where things get dicier)
- Create a culture of two-way feedback - to you, and to fellow team members (dicier still)
- Make accountability a habit
- Keep track of your commitments, holding each other acountable
- Use an accountability framework so you know who’s responsibile for what
Managing Your Own Career
How To Do an Annual Reflection to Get The Most Out Of The Year Ahead - Ashley Janssen
Your Calendar = Your Priorities - John Cutler
As with reflecting back on the work of your team, the end of the year is a good time to reflect back on what you personally have seen and done. But while we know to do this in a structured way with our team, it can be easy to turn self-reflection into a lazy rehashing the same old events. Janssen suggests a more structured approach - actually collecting information from your calendar, email, plans/goals/reviews, and what have you over the past year, evaluating what actually matters, and viewing them through some questions you care about. You can then use that processed information to make some concrete goals, instead of just ruminating and vowing that next year will be different.
Maybe most importantly, Janssen councils to do that with some kindness to yourself - it’s been quite a year.
Going a little more specifically, Cutler points out that our scarcest resource is time. There’s a saying in policy circles “Show me your budget and I’ll tell you what your priorities/values are”; in research computing managerial work, where our budget is typically pretty constrained, it’s our time which reflects our implicit priorities. Those implicit priorities may not be what they should be! Looking at your calendar (and making sure your calendar reflects what you actually do - e.g. blocking off time for working on things) is one of the most powerful tools you have to make sure your effort is being focussed where it should be.
So You Want to Become a Sales Engineer? - Allen Vailliencourt, Teleport
In both academia and the private sector, people who have only been in one or the other tend to overestimate the differences in the day-to-day work between the two. The incentives and timelines can be quite different, but people are people, and applying technology to user problems is applying technology to user problems.
I follow teleport’s blog because they do cool stuff with ssh certificates and write well about it, but take a look at this outline of what a sales engineer looks like. It’s not that radically different from the day-to-day of support staff in research computing centres. Learning new stuff, taking calls with with researchers and peers, demoing things, and helping them solve their problems.
Product Management and Working with Research Communities
Great engineering teams focus on milestones instead of projects - Jade Rubick
Scatter-Gather - Tim Ottinger
One recurring issue with research computing is that we typically get funded for projects, but we’re really building products — tools, outputs, and expertise that will (hopefully) outlast any particular project.
For different reasons, Rubick strongly recommends that your team focusses on milestones rather than projects, but this change in focus can help be an intermediate stepping stone between project-based thinking and product-based thinking. He recommends defining progress in terms of milestones which are small, high-quality (e.g. not proofs of concepts), understandable, and independently valuable. His definition of milestone might a bit smaller (1-3 weeks) than makes sense in our line of work, but even 1-2 month milestones, when something can be delivered (whether it’s information or working integrated code) can be a really useful transition from focussing on the requirements of any given project to building a long-lasting product.
Ottinger focusses on a different problem with long-lived projects - work gets farmed out “scatter-gather” in a way that is hard to integrate, can lead to silos (“front end” vs “back end”, for example), and its hard for team members to see how their work contributes. Instead, Ottinger recommends a similar approach - delivering output in small unified chunks that involves significant subsets of the team working together.
Research Software Development
What to do with broken tests - Jonathan Hall
Hall’s article gives maybe counter-intuitive advice about what to do when you come into a situation - maybe you’re joining a new team, maybe an existing team is just realizing it’s dug itself into a hole - where there are a bunch of broken CI tests.
The key thing is that tests play a technical role, sure, but more importantly, they play a process role. You don’t want people to be in the habit of ignoring tests, or not caring that they check in code that breaks another test (or was it one of the others that were already broke? Who can tell?)
So Hall’s advice is not to be a hero and fix everything - almost the opposite:
- Disable broken tests. Have whatever test pass visibly pass.
- Automate the tests. Have them running a lot
- Fix the broken tests that you can easily fix. “As a very rough rule of thumb, don’t spend more than 5-10 minutes trying to fix any individual test.”
- Delete broken tests.
- Make sure people write tests for all functionality changes.
With this you can fix the processes, and then start getting things moving in the right direction.
This tracks as 100% right to me. 20 years ago, when the Earth was young and new, I was at the FLASH centre at the University of Chicago, and we made a big functionality change - during that change a lot of tests were broken ‘as expected’, so we just let them fail and the dashboard went red (one new grad student had actually set up nightly test suites with a dashboard - this was in the late 90s, so this was pretty cutting edge for research code at the time). While we let those tests sit there broken, a lot of bad stuff happened in the code that we didn’t realize at the time, because we had intentionally broken our way of noticing new bad-code-stuff.
Modernizing your code with C++20 - Phil Nash, SonarSource
If you have a C++ code base, Nash walks you through a number of small quality-of-life improvements that go beyond the new “spaceship operator”.
Scaling productivity on microservices at Lyft (Part 2): Optimizing for fast local development - Scott Wilson
Wilson writes about microservice development, but I think the HPC developer productivity discussion referred to in #102 comes down to this - that it’s easy (or can be made relatively easy) to develop services, workstation codes, web development etc for the local developer, but HPC codes or software requiring special resources for research computing is nowhere near there yet. It’s comparatively straightforward to set up environments which enable that in the cloud, but it can get speedy. On-prem systems still make this really hard.
Wilson talks about how at Lyft they support local microservice development, which to be fair does have its own challenges - running locally is very different form running in prod. But in this case, existing third-party tooling plus a willingness to put in the effort to make local development easy (including, interestingly to me, a commitment to making sure services can run cleanly “natively” on their standard dev machines, not requiring containers) has sped development.
Scaling the Practice of Architecture, Conversationally - Andrew Harmel-Law
We’ve talked about Architectural Decision Records (ADR) for quite a while here, going back to at least #38. Here Harmel-Law recommends a ground-up approach to scaling architectural decisions, where anyone can propose (or even make) architectural decisions after writing it up in essentially an RFC as a proto-ADR and consulting the groups that will be effected by it and those with relevant expertise. This has the advantages of distributing (and so scaling) decision making, having architecture being a series of ongoing conversations, and greater asynchrony.
Research Data Management and Analysis
Some Indexing Best Practices - Michael Christofides
I think we all go through this - or certainly I did - stage one of database use maturity being “what’s an index, exactly?”, and stage two being “INDEX ALL OF THE THINGS!!”. But not only does that slow down writes, it can actually prevent some optimizations entirely.
Christofides talks about the pros and cons of indexes, the various types, and where to focus your indexing. The article is written int he context of Postgres, but the concepts are pretty general. His summary is:
- Don’t index every column
- Index columns that you filter on
- Only index data that you need to look up
- Consider other index types
- Use indexes to pre-sort data
- Use multi-column indexes, but sparingly
- Look after your indexes
- Pick your battles
The Gamma: Tools for open data-driven storytelling - Alan Turing Institute
This is a fairly mature tool, but one I’ve only just heard about. It provides javascript code-based and interactive spreadsheet-like live preview and environment for exploring data sets and generating nice visualizations.
Research Computing Systems
RCE 0-day exploit found in log4j, a popular Java logging package - Free Wortley, Chris Thompson, LunaSec
Ugh, this is a really bad one. If you have some publicly accessible Java-based services running, look into this now; systems are already being scanned at scale for this (and people are putting together blocklists of IPs doing those scans - see this twitter thread). Tools like syft or grype can help you check to see if you’re using log4j in your dependency chain, and here’s a simple python scanner.
A bit like the issue with maliciously-crafted WiFi SSIDs locking iPhones, the issue is with formatting in logging code - but here it can be leveraged into remote code execution, which is really bad given how widely used this library is. The only good news might be that really old code which hasn’t been touched in years might be on log4j 1.x; but that leaves a lot of 2.0-2.14.1 systems out there. It also appears to have a dependence on JDK versions.
Stacking Up AMD MI200 vs NVIDIA A100 Compute Engines - Timothy Prickett Morgan
A look at the A100 vs MI200, and some considerations for what’s next for the next generation, “Hopper”, compute GPUs from NVIDIA. A lot of what’s going to make the next few years interesting for compute is different CPUs, GPUs, network cards, and choosing very different tradeoffs. AMD looks to have gone all-in on double precision floating point computation for the MI200. Will Hopper follow, or do something different? Interesting times….
Memory Snapshots Bring Checkpointing into the 21st Century - Timothy Prickett Morgan, The Next Platform
Many of you will have experience with DMTCP, an open source tool for transparently checkpointing the state of software without modifying the software itself (or with only very modest modifications, depending on what you’re doing). I remember proof-of-concept-ing this out at SciNet, and it feeling like magic that I could kill a job and then just start it up again as if nothing had happened; especially since this was before VMs were common.
Here Morgan reports on the work of MemVerge, a commercial company, to contribute to and provide commercial support for DMTCP and one of it plug-ins, MPI-Agnostic Network-Agnostic Transparent Checkpointing (MANA).
In research computing we have a pretty ambivalent relationship with commercialization - we are encouraged to find commercialization opportunities, but people are very skeptical about the development of a commercial version of open-source software the community has used and contributed to for years. But this commercialization will help guarantee the ongoing viability of DMTCP and related tools, and help push it into the cloud - imagine routine research users being widely able to more safely run medium-sized MPI jobs on spot instances! Someone has to do that development work, and if the research community won’t pay for it to be done at the level that is needed, then other partners have to step in.
Emerging Technologies and Practices
Faster and Cheaper Serverless Computing on Harvested Resources - Micag Lerner
Faster and Cheaper Serverless Computing on Harvested Resources - Yanqi Zhang et al., Proceedings of SOSP ’21
Lerner gives an overview of a paper from the 2021 Symposium on Operating Systems Principles conference by Zhang et al describing the use of Harvest Virtual Machines, which is something Microsoft has looked at before (PDF). Harvest VMs can be though of as a bit like an opportunistic cycle-scavenger for throughput computing, like say HTCondor started out, but rather than just being available or unavailable, sizes up and down depending on how busy the underlying node is. Here the application is for Serverless computing - which can be a very effective way to organize short-ish embarrassingly parallel tasks.
There’s interesting discussion here about whether the “typical” serverless workload is a match to these variable capacity VMs - a lot depends on the length of time the individual tasks run, and how tolerant they are to being cancelled and re-started.
To test out their hypothesis, even though the authors are at Microsoft they actually use the open source Apache OpenWhisk for implementing function-as-a service and building them on top of the harvest VMs.
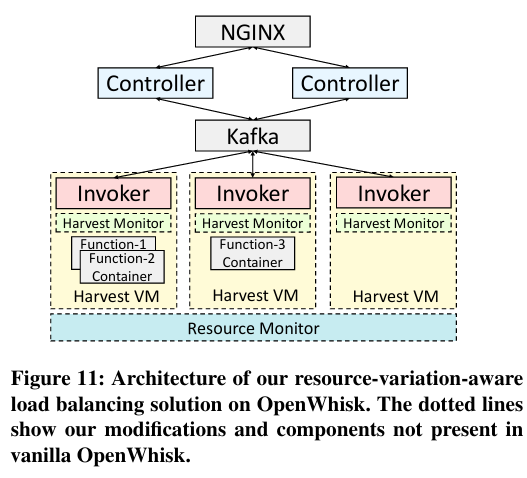
This isn’t something that an HPC cluster would be able to roll out tomorrow even if they wanted to, but as systems and workloads get more dynamic, this opens up some really interesting possibilities of getting every last bit of utilization out of a large cluster, as long as there is a large pool of very short low-state jobs that can be fired off.
Calls for Submissions
Winter and the end of this term brings planning for the summer term! Some nice opportunities below for trainees.
Sustainable Research Pathways for High-Performance Computing (SRP-HPC) - Applications due 31 Dec
Sustainable Horizons Institute, which specializes in improving diversity and inclusion in scientific communities, and the DOE National Laboratory HPC centres, are pairing to offer faculty and student tracks for research training or collaboration opportunities in application development, software technology, or hardware and integration.
Research Experiences for Undergraduates (REU) @ National Centre for Supercomputing Applications - NCSA, Deadline 15 March
If you know a US undergrad who would be a good REU candidate for work at the storied NCSA, particularly on open source machine learning and tools, this is a great opportunity.
UKRI Cloud Workshop 2022 - 29 March, London, Deadline 17 Jan
The hosts are:
[…] looking for talk submissions covering all aspects of research computing using cloud, both public and private. We wish to have a diverse set of viewpoints represented at this workshop and encourage individuals and institutions of all backgrounds (for example academic, technical, business, or user experience) to apply.
Themes include HPC, cloud pilots, user experience,s hybrid cloud, trusted environments, COVID and cloud, and performance.
International HPC Summer School 2022 - 19-24 June, Athens; Deadline 31 Jan
Grad students and postdocs at institutions in Canada, Europe, Japan, and the US can apply to this extremely well thought of HPC summer school, co-organized by PRACE, XSEDE, RIKEN, and SciNet. This is a great opportunity to head off for a week, network with a lot of other trainees from different fields and different places, and fill your head chock full of advanced HPC knowledge.
28th International European Conference on Parallel and Distributed Computing (Euro-Par 2022) - 24-26 Aug, Hybrid Glasgow and online, paper deadline 11 Feb
From the CFP:
Euro-Par is the prime European conference covering all aspects of parallel and distributed processing, ranging from theory to practice, from small to the largest parallel and distributed systems and infrastructures, from fundamental computational problems to full-fledged applications, from architecture, compiler, language and interface design and implementation, to tools, support infrastructures, and application performance aspects.
Relevant topics include
- Performance and Power Modelling, Prediction and Evaluation
- Scheduling and Load Balancing
- Data Management, Analytics and Machine Learning
- Cluster, Cloud and Edge Computing
- Theory and Algorithms for Parallel and Distributed Processing
- Parallel and Distributed Programming, Interfaces, and Languages
- Multicore and Manycore Parallelism
- Parallel Numerical Methods and Applications
- High-performance architectures and accelerators
38th IEEE International Conference on Software Maintenance and Evolution (ICSME 2022) - 3–7 October, 2022, Cyprus, Paper deadline 1 Apr
Papers on all topics related to maintaining and evolving code bases are welcomed, including
• Change and defect management • Continuous integration/deployment • Empirical studies of software maintenance and evolution • Evolution of non-code artifacts • Human aspects of software maintenance and evolution • Mining software repositories • Productivity of software engineers during maintenance and evolution • Software migration and renovation • Software quality assessment • Software refactoring and restructuring • Technical Debt
Events: Conferences, Training
NHR PerfLab Seminar: Memory Bandwidth and System Balance in HPC Systems, Dr John D McCalpin, 15 Dec, Zoom
Interesting looking talk about system balance and memory bandwidth these days by TACC’s McCalpin.
Random
Cute systemd-as-a-example series, using containers so you can keep your experimentation self-contained.
A free two-hour self-paced course on programming NVIDIA’s DPUs using DOCA.
A reminder that overall research computing is worse than either academia or computing when it comes to diversity, and HPC in particular is even worse than that.
UBC’s excellent “Data Science, a First Introduction” course Jupyter notebooks are now up on Binder, and so are interactive.
On the bioinformatics/comp bio side, materials for a comprehensive looking course from Harvard is online.
llama, a file manager for the terminal.
Improving flamegraphs with fil.
Write a simple 16-bit VM in 125 lines of C.
Or simply gape in horrified awe at implementations of AES-128 and SHA256 in Scratch.
GraphQL for Postgres in native PLpgSQL - pg_graphql.
Draw architectural diagrams with Python with diagrams.
After roughly 30 years of editing files in vi and then realizing I needed to be root to save my changes, this week I learned about :w !sudo tee "%".
LAN, WAN, VLAN, etc for software developers.
Sadly, because I’ve sent this newsletter out late, you may have missed your chance to see Excel wizards battling it out esports-style on ESPN3 and live on youtube in the Financial Modelling World Cup.
That’s it…
And that’s it for another week, and for 2021!. Let me know what you thought, or if you have anything you’d like to share about the newsletter or management. Just email me or reply to this newsletter if you get it in your inbox.
Have a great weekend, enjoy the rest of the year, and good luck in the new year with your research computing team. Talk to you in January!
Jonathan
About This Newsletter
Research computing - the intertwined streams of software development, systems, data management and analysis - is much more than technology. It’s teams, it’s communities, it’s product management - it’s people. It’s also one of the most important ways we can be supporting science, scholarship, and R&D today.
So research computing teams are too important to research to be managed poorly. But no one teaches us how to be effective managers and leaders in academia. We have an advantage, though - working in research collaborations have taught us the advanced management skills, but not the basics.
This newsletter focusses on providing new and experienced research computing and data managers the tools they need to be good managers without the stress, and to help their teams achieve great results and grow their careers.
Jobs Leading Research Computing Teams
This week’s new-listing highlights are below; the full listing of 148 jobs is, as ever, available on the job board.
Scientific Leader, Human Genetics/Computational Biology Program Manager - GSK, Collegeville PA USA or Stevanage UK
The Genomic and Observational Data Sciences team within the Humana Genetics and Computational Biology (HGCB) organisation is seeking a program manager to facilitate agile project management, decision-making, and participation in the advancement of HGCB data strategy and integrity objectives. The successful candidate will drive mature and consistent program delivery in a multidisciplinary, collaborative and scientifically driven environment, interacting with GSK scientists and key academic collaborators to advance drug discovery and clinical development in multiple disease areas. The scope of supported projects will be broad, including external data collaborations, analysis and tool implementations, and departmental data integrity initiatives.
Principal Data & Applied Scientist Manager - Microsoft, Vancouver BC CA
Connected Reality is a team within the Business Application Platform organization that includes both the Mixed Reality Applications and Connected Spaces – this product group provides the opportunity to work on transformative early-stage products in highly relevant, up-and-coming domains. An ideal candidate will have worked on early-stage products and is comfortable influencing across multiple disciplines. You will work closely and in partnership with teams in our business applications eco-system including developer, design, and PM teams to build the future of how we work. You will be part of product leadership building innovative products from scratch - collaborating with all disciplines.
Federated Research Computing Delivery Manager - University of Oxford, Oxford UK
The Federated Research Computing Delivery Manager is a unique opportunity to take a lead role in the development and delivery of a programme of business and IT change at the University. “Research Computing” comprises a broad mix of resources including compute hardware, networking, storage, hosting services and the teams required to support and exploit these physical resources to help enable world-leading research at the University. As an example of the range of activity; in the first year of this role, the post-holder will be expected to have delivered the programme governance structure, as well as performing the stakeholder consultation and analysis which will be critical in shaping the programme and delivering the business case for investment to deliver against the programme’s strategic objectives through year two onwards.
Director, Holland Computing Center - University of Nebraska, Lincoln NE USA
The University of Nebraska is launching a search for a new Director to lead the Holland Computing Center, a nationally recognized resource that provides high-performance computing and cyberinfrastructure systems and services to advance the research mission of the University of Nebraska. Reporting to the Vice Chancellor for Research & Economic Development at the University of Nebraska-Lincoln, the Director will bring vision and leading-edge expertise in high performance computing (HPC) and high throughput computing (HTC) to shape and steward these investments and to realize the full potential of the distinctive opportunity set that institutional strategy, timing, and regional growth have created. The Director ensures that HCC has the depth and breadth of technical knowledge to engage academic researchers and staff and provides high-level technical direction in alignment with this mission.
Manager – Scientific Data Management - Dupont, Various US CA
Information & Data Science (IDS) is a team of Information Scientists, Data Scientists, and Research Computing experts who focus on maximizing the power that information can provide to the Innovation, Discovery, and Product Development processes. Supporting the R&D community throughout DuPont - we are seeking an experienced, and energetic leader who will help drive and enable innovation through support and new implementations of scientific data management systems and underlying support of the applications.
Vertical Director, High Performance Computing - HPE, Washington DC USA
We are seeking a well-thought and curious technical leader that will be responsible for designing, planning, developing and managing a product or portfolio of next generation high performance computing products and/or solutions throughout the portfolio lifecycle: from new product definition or enhancements to existing products; planning, design, forecasting, and production; to end of life. Unique mastery and recognized authority on the Leadership Computing market including technologies, theories, techniques, customer requirements. Contributes to the development of innovative principles and ideas. Successfully operates in the most complex disciplines, in which the company must operate to be successful. Provides highly innovative solutions. Leads large, cross-division functional teams or projects that affect the organization’s long-term goals and objectives. Participates in cross-division, multi-function teams. Provides mentoring and guidance to lower level employees. Routinely exercises independent judgment in developing methods, techniques and criteria for achieving objectives. Develops strategy and sets functional policy and direction. Acts as a functional manager within area of expertise but does not manage other employees as a primary job function.