RCT #179 - Success Stories are the best advocacy. Plus: Avoiding hero work pays off in the end; Good progress updates; Design is not recoverable from implementation; Product management at a science tech company; Code-review.org; Configuration shouldn't change version-controlled source code
We’re going to continue the series based on this seemingly simple diagram. The diagram sketches out the flywheel of a successful technical research support team, and today I’m going to talk about the part that makes it a flywheel - making sure that the work is noticed by and registers with funding decision makers.
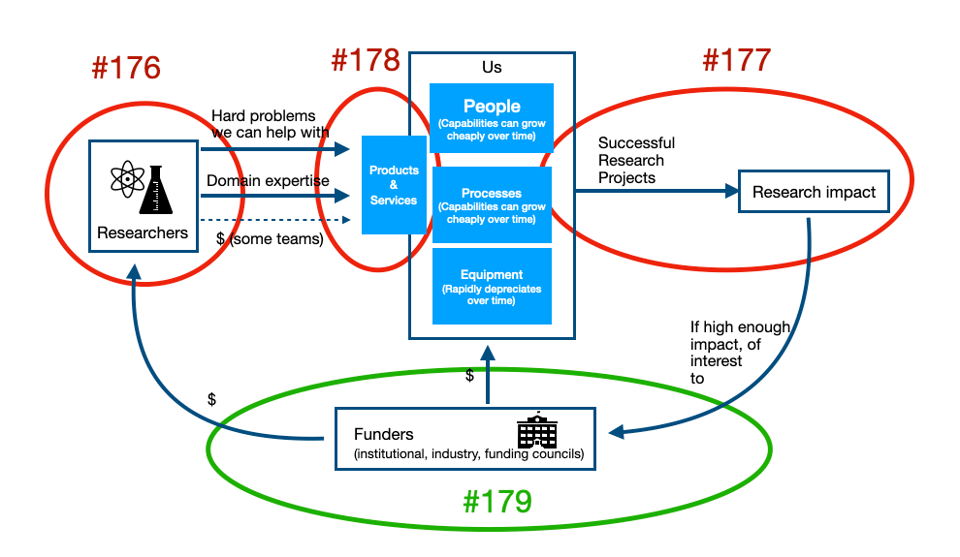
In earlier versions of the diagram, I had the text by the arrow on the bottom right saying “If high enough impact, noticed by…”. That passive voice was a mistake, but it’s no consolation that it’s one made by many teams.
You can’t be passive about having your teams’ impact noticed by others. Not if you want your team to have the success it deserves.
“But the work should speak for itself…” - No! That’s what people say when they don’t want to put in the effort of speaking on behalf of the work and the people who do it. Work does not speak. Work does not advocate. People speak. People advocate. People show how their work benefits others.
And if we care about our team and the work it’s doing? Then I have terrible news, but “people” has to be us.
Those who decide on funding for our teams don’t understand the work we do, nor have any sense of how well we’re doing it (#165). It’s up to us to demonstrate the scientific impact our work is having.
We operate as a professional services firm (#127), but that’s not our business model. If it was, nearly all we would have to do is keep our existing clients happy so they come back for more work. If we want to grow, sure, we have to market our services, but we can operate at near steady-state by picking up the occasional new business here and there.
Instead, our business model is that of a nonprofit (#164). (This is typically true even for the teams that do a fair amount of fee-for-service business, as they are still subsidized). We have primary clients — the researchers whose work we supercharge — and our sustaining clients, who are the national and institutional funders and decision makers.
In such a business model, even treading water and maintaining a steady amount of funding requires consistent advocacy and communications. (Just ask your researchers!)
The people giving money to us have very limited means, compared to the needs; and are faced with an effectively unlimited number of perfectly worthy targets for their money. They are constantly approached by people who have good and worthwhile and exciting proposals, people who are genuinely convinced, with some supporting evidence, that this proposal is the most valuable thing that could possibly happen at the institution. All of this is happening while budgets are getting tighter, not more generous, on average.
In this situation, we owe it not just to our team but also to the decision makers to show them exactly how our team advances the goals they have. If we don’t do that job, a job that really only we can do, how can the decision makers possibly make informed decisions about how they should best assign funds? And without us, who is there to trumpet the amazing work our team does?
Whether we’re talking to program officers or someone in OVPR or OCIO, the communication and advocacy we’re going to be doing is simply having an iteratively more effective series of conversations.
And these will be conversations, not emailed documents I know you love the documents you assemble, they’re awesome, but they’re not getting read.
More importantly, though, you don’t learn things by sending people PDFs. And in these conversations, we’ll be learning as much from them as they are from us - we’ll be asking them what is important to them, what problems they’re having that perhaps we can be enlisted to solve. And we’ll be sharing with them the work we do, with a spotlight on exactly those problems or important opportunities.
Over time you’ll learn exactly who is interested in what, but you can begin from a pretty solid starting point.
I can tell you for absolute certain that your decision makers do not inherently care at all about any of the following:
Your utilization rate
The number of researchers supported
How many lines of code/CPU cores/data bases you’ve generated or manage
They may even ask for those things, but only because they have no other idea what to talk to you about, or because your predecessor showed them those numbers and now they’ve became trained to expect them. But if they think those numbers are all your team has to offer, they won't value your team very highly.
If your decision makers start digging deeply into those numbers and start asking why they’re low, they think your team is doing a bad job and just don’t know any other way to ask probing questions. If your decision makers think you’re doing well, then they will forget these numbers before they’re even finished reading them.
Either way, every minute you spend talking about these numbers with your decision makers is a minute you’re not talking about something that matters, and not demonstrating to them that you and your team realize what matters.
I know this, and you know this, gentle reader; and yet, I can’t tell you how many times I’ve spoken in the last couple of years with people, asking them how they think of the impact of their teams, and had them go blank for a second before answering something about utilization rate or number of jobs or numbers of tickets. Even in this common era year two thousand twenty four, we have work to do as a community.
Those numbers are not important. The things they count are not inherently valuable. You can juice utilization rate or number of tickets or number of clients by breaking tickets into dozens of little sub-tickets or giving busy work to your computers or people or expending resources offering near valueless services to massive numbers of people; not only do those things not advance science, they hinder it in annoying little paper-cut ways. You can drop those numbers while making your community’s research environment better by having very long running collaborative discussions, by leaving staff time available for professional development or computer time available for high-priority jobs, or by focussing on the research sub-communities where your team can do the most good.
Those numbers being high or low says nothing about the reason our teams exist, which is advancing our community’s research as much as possible given our constraints.
Your decision makers have specific problems they’re trying to solve and are willing to allocate money to solving those problems (#75). Focusing on institutional decision makers: at small institutions, it’s often about trying to nucleate a critical mass around certain interdisciplinary areas. In larger institutions, it might be about trying to develop capability in a new area, or maintaining a lead in an established field of expertise, or making sure that new faculty members are given the support they need to launch their careers successfully.
Your decision makers care somewhat, in an abstract sort of way, about number of papers that relied on your team’s support. But not all papers are equally valuable, your contribution to any given paper much less the sum of them is unclear, and your decision makers care about specific areas and researchers more than others.
Your institutional decision makers care more strongly about total amount of grant funding projects you’re supporting are bringing in. Decision makers of any sort will be impressed by the total amount of grant funding where your team is explicitly written into the grants, because that’s an unmistakeable endorsement stating that funding your team is a cost-effective way of advancing research (#178), given by the people who care more than anyone else about that research.
Decision makers will also be interested in how you’re working successfully with other teams (because other teams are not the competition, less and worse science is - #142 - and because this shows canny and effective use of resources).
But nothing is really going to compete with success stories and testimonials, curated to the interests of the person you’re speaking to.
This is hard for us to accept; our training focussed on quantitative data. Plots! Error bars! Equations!
But an actual story, describing in detail about how your team in particular made possible some important-to-the-listener advance by a named and quoted researcher, answers more questions about the impact your team brings to your community than any plot or table you can bring.
Collecting these stories is time- and labour-intensive; but the conversations you have collecting them are inherently valuable, and you’ll learn a lot; the materials you collect can be reused countless different ways; and they are compelling to decision makers and other researchers, while documenting for your team members why what they do matters and giving them a portfolio of their contributions. You can use them in talks and on your website and in annual reports and in emails. Eventually you have a library that can be deployed in a targeted way as needed.
So my recommendation here is simple, but not necessarily easy — start talking with your stakeholders and decision makers; find out who cares about what, and what problems they’re trying to solve; collect quantitative data, sure, but also qualitative data in the form of success stories and testimonials about the impact your team has; and share that information relentlessly with the people who will care the most, while learning what does and doesn’t work.
So that completes our loop around our flywheel diagram. The next issue or two will focus on the “us” box - I’m leaving that for towards the end, because it only makes sense to talk about operating the “us” box after establishing the context of the whole flywheel.
Until then, on to the roundup!
Managing Teams
Across the way over at Manager, Ph.D., last week I talked about something particularly important for our inherently very interdisciplinary and cross-organizational teams: how managing up (and sideways, and diagonally) is part of our job.
In the roundup I covered articles on:
The Ladder of leadership
Hidden opportunities in feedback
Good directive work phrases
Announcing departures
Get it done (doesn’t mean go off and do it yourself)
Managing and communicating up tips
Introverts can be the best networkers
Technical Leadership
Avoiding hero work pays off in the long run - Ben Cotton, Duck Alignment Academy
I talk to a lot of technical research support leaders, and I’ve heard more than a few proudly-told stories of teams working heroically, even over weekends, to get something done.
But — we all know that’s not good, right?
Hero work feels good, it’s great to see and feel camaraderie and esprit de corps.
But it speaks to either underinvestment in something, or trying to do something your team is just not equipped to do.
Putting the time and effort and investment into avoiding the need for hero work — or simply declaring some things out of scope given the resources — is at best unglamorous and at worst will get people cross at you.
But as Cotton explains, whether it’s a software release deadline slip or something else, avoiding hero work is an investment in sustained productivity.
How to Send Progress Updates - Slava Akhmechet
When we’re in the weeds of work, it’s easy to forget the larger context and share the wrong information to stakeholders. Akhmechet gives a pretty good list of points to remember about writing effective progress updates, and indeed how the “forcing function” of progress updates can usefully help shape the work being done.
Design is not recoverable from implementation - Eric Normand
Ah, finally a nice succinct way of describing the need for comments, internal documentation, architectural decision records, and the rest: “Design is not recoverable from implementation”.
Product Management and Working with Research Communities
Our Process - Greg Wilson
Wilson, of software carpentry fame, describes the product management process at “a small to medium sized tech company”:
I believe the most important part of what follows is how she has organized her thinking. Each process exists to answer key questions, has its own frequency, is someone’s responsibility, and generates specific products.
That observation is really important - processes need to serve a very clear purpose and have someone who is responsible for ensuring that those purposes are met.
The scale of the team Wilson works on now is probably much larger than any of our teams, and so how those processes are executed might not translate directly, but the basic questions being asked (particularly by things like product & solution discovery) absolutely do, or should.
Research Software Development
Code-Review.org: An Online Tutorial to Improve Your Code Review Skills - Helen Kershaw, Better Scientific Software
Kershaw introduces about code-review.org, a series of code reviewing tutorials and blog aimed specifically for scientific code review. This is extremely welcome - congratulations to everyone involved! From the first paragraph of the tutorial introduction:
If you’ll indulge me a 20 year old British comedy reference, a quote from horror writer Garth Marenghi “I’m one of the few people you’ll meet who’s written more books than they’ve read”. Which is a hilarious joke for writers, but a sobering reality for scientific software. It is not that unusual for people working in science to write more code than they read. But we can change that, right?
Apart from making it easier for people to contribute to projects (and accept contributions into projects), thus building more resilient scientific software communities, just getting more research software developers reading more code is itself an important goal. This looks promising and I’ll keep an eye on it.
Don't require people to change 'source code' to configure your programs - Chris Siebenmann
The target here is probably more open-source system software than scientific software, but the point stands. Siebenmann argues (and convinces me, at least) that any local configuration should be done in file that won’t be overwritten by installing the next release of the software.
Random
The Zilog Z80, heart of the Sinclair ZX Spectrum, ColecoVision, TRS-80 Models I, II, III, and 4, Dec Rainbow, and early CP/M machines, had been in continuous production since 1976, but is now being discontinued.
The nautical team that keeps the internet working.
A 1985 in-car navigation system that predated readily available accurate GPS, and used a CRT and cassette tapes - the Etak Navigator.
Computational agent-based models have long been used in social science, but this is new - generating hypotheses and automated screening of them with LLMs.
Query your systems like a database.
I find theorem provers fascinating - here’s an intro to theorem proving with Lean 4.
Another interesting declarative diagram drawer - D2.
As more PhD trained scientists leave academia or just choose other paths, companies are setting up to make it easier to spin out science companies. Here’s WilbeLab, which helps set up commercial lab spaces. (Not an endorsement, don’t know anything about this company in particular one way or another, just find the phenomenon fascinating.)
Debian in the browser - we’ve seen things like this before but this is a compelling example of container2wasm.
Automated traversal of networks using SSH private keys - ssh-snake.
A nice discussion of a paper on visualizing uncertainty for non-experts - we can assume too much as experts, it’s an interesting paper and a great distillation.
We’re starting to see papers on teaching coding incorporating AI code-generation tools - super early days, but (unsurprisingly) there are areas of real potential and areas of real gotchas.
Apparently 50 lines is the sweet spot for pull request length.
That’s it…
And that’s it for another week. If any of the above was interesting or helpful, feel free to share it wherever you think it’d be useful! And let me know what you thought, or if you have anything you’d like to share about the newsletter or stewarding and leading our teams. Just email me, or reply to this newsletter if you get it in your inbox.
Have a great weekend, and good luck in the coming week with your research computing team,
Jonathan
About This Newsletter
Research computing - the intertwined streams of software development, systems, data management and analysis - is much more than technology. It’s teams, it’s communities, it’s product management - it’s people. It’s also one of the most important ways we can be supporting science, scholarship, and R&D today.
So research computing teams are too important to research to be managed poorly. But no one teaches us how to be effective managers and leaders in academia. We have an advantage, though - working in research collaborations have taught us the advanced management skills, but not the basics.
This newsletter focusses on providing new and experienced research computing and data managers the tools they need to be good managers without the stress, and to help their teams achieve great results and grow their careers.
Jobs Leading Research Computing Teams
This week’s new-listing highlights are below in the email edition; the full listing of 110 jobs is, as ever, available on the job board.
Lead Bioinformatics Scientist - Purdue University, West Lafayette IN USA
As the Lead Bioinformatics Scientist, you will be an integral part of our researcher-facing team, leading the support of Purdue’s bioinformatics initiatives at Rosen Center for Advanced Computing. This position provides several opportunities for research collaborations, leadership, external community engagement, and professional development.
BIDS Executive Director - Berkeley Institute for Data Science - University of California, Berkeley, Berkeley CA USA
The Executive Director will take a leadership role in managing and developing the Institute’s research programs and representing these programs to outside organizations. Under the direction of the BIDS faculty director, the ED will develop the vision and corresponding agenda to achieve the Institute’s objectives. The incumbent will oversee all elements of program administration, facilitate collaborations among multiple research groups from across the campus as well as with partner organizations, and provide leadership in identifying outreach services. The Executive Director will work under the direction of the Institute’s academic leadership to formulate strategic goals and objectives, direct long-term planning, and develop policies and procedures, and raise funding from external sources. This individual will be considered a subject matter expert on campus and is recognized as an expert externally in the field.
Centre Manager, QET Labs, Bristol Quantum Information Institute - University of Bristol, Bristol UK
We have a unique opportunity to join our team in the Quantum Engineering Technology Labs (QET Labs) Research Centre within the Bristol Quantum Information Institute, as the Centre Manager. This crucial role involves working closely with academics and researchers, and leading a well-established team of professional support staff to deliver a programme of activities that supports the development of world-changing quantum technologies, and trains the academic and industry leaders of the future. The role is highly-varied, forms a vital part of the QET Labs operations, is crucial to effective operational management and direction, and plays a central role in supporting the strategy for the Centre.
Senior Technical Program Manager - AI Research Systems - NVIDIA, Redmond WA USA
Joining NVIDIA's AI Efficiency Team means contributing to the infrastructure that powers our innovative AI research. This team focuses on optimizing efficiency and resiliency of ML workloads, as well as developing scalable AI infrastructure tools and services. Our objective is to deliver a resilient and scalable environment for NVIDIA's AI researchers, providing them with the necessary resources and scale to foster innovation. As a Technical Program Manager (TPM) on this team, you'll confront and oversee the unique challenges of building and maintaining the AI and data infrastructure necessary for training flagship models at an unprecedented scale. Your focus will be on increasing researcher productivity, as well improving system stability, availability and performance.
Associate Director, Women's Health Bioinformatics - Natera, Remote USA
Natera is currently seeking an Associate Director to join our Women's Health Bioinformatics team. The individual will lead a team of Bioinformatics Scientists and will be responsible for the planning and execution of research projects related to Women’s Health. The ideal candidate should be an experienced team leader and have a strong background in algorithm and assay development, sequencing data processing, and experience with full life cycle of product development.
Director of Bioinformatics - Refined Science, Denver CO USA
RefinedScience is seeking a Bioinformatics Director to join an interdisciplinary team of computational biologists, data scientists, cancer biologists, and clinicians who are seeking to develop new therapies for cancer and other diseases. The individual will lead a growing team of Bioinformaticians and Computational Biologists in furthering organizational research goals and tool/pipeline development. This is a hybrid role out of Denver, CO, working remotely and sometimes from a RefinedScience designated site.
HPC Team Lead - General Dynamics IT, Remote USA
GDIT is seeking a dynamic leader to manage a team of 4 to 6 computational scientists. You will be supporting the DoD High Performance Computing Modernization Program (HPCMP) User Productivity Enhancement and Training (PET) initiative. As the lead computational scientist for your team, you will join a team of innovative and savvy engineers and computational scientists. We focus on building collaborative relationships with the HPC community to better understand customer technology needs and challenges. Our team of computational scientists help solve the HPC challenges for DoD scientists and engineers across the Army, Navy and Air Force.
Senior Software Development Manager, Precision Health Platform - Verily, Kitchener-Waterloo ON CA
Verily's core strategy to advance precision health is by closing the gap between research and care. Our team is responsible for making data useful through customizable tools that provide enrichment and analysis — adding context and insights to improve decision-making, improving research and care workflows and supporting the next best action. By using scalable ingestion, harmonization, de-identification and tokenization techniques to bring multiple datasets together on a single platform, customers can generate high quality insights for users in applications and analysis. As a Senior Software Development Manager, you'll be instrumental in shaping the scope and direction of our technical initiatives. Tackle exciting challenges head-on, overseeing the development life cycle and ensuring seamless execution. Your leadership will drive innovation, foster collaboration, and deliver impactful solutions.
Director, Planning and Performance - Digital Research Alliance of Canada, Remote CA
Reporting to the Vice President, Strategy and Planning, the Director will be responsible for leading the development, implementation, and evaluation of the annual planning processes, the establishment and operation of a Project/Portfolio Management office function, and the ongoing monitoring and measurement of performance across various projects and initiatives within the organization contributing to enterprise key performance indicators (KPIs), objectives and key results (OKRs).
Principal Bioinformatician, Cancer Research UK National Biomarker Centre - University of Manchester, Manchester UK
An exciting opportunity now presents for a Principal Bioinformatician to join the Bioinformatics and Biostatistics (BBS) Team within NBC. You will work alongside a multidisciplinary team of clinicians, biologists, statisticians, bioinformaticians and computational scientists to analyse genomic, epigenomic and transcriptomic data arising from patient samples; including cell-free DNA and RNA (cfDNA, cfRNA), single cell data and circulating cancer-associated cells.
Scientific Computing Manager - University of Dundee, Dundee UK
We now have an exciting opportunity for someone to join our team in a newly created Scientific Computing Manager position. We are looking to appoint an outstanding individual, with experience of working in a similar role, with proven leadership and line management experience to develop and implement a strategy that will support our specialised scientific and engineering computing activities.
Research Reporting and Analytics Manager - University of Wollongong, Wollongong NSW AU
This position is part of the Research Analytics, Systems & Support (RASS) team in the Research Services Office (RSO), part of the Research and Sustainable Futures Division. The RSO is the central coordination point for all University research information systems and analytics, research grants, fellowships, commercial and contract research, and faculty research operations. We are committed to our team values: Collaborative, Integrity, Respectful, Innovative and Supportive.
Senior Data Manager - The George Institute for Global Health, Sydney NSW AU
As an affiliated Medical Research Institute of UNSW, The George Institute for Global Health is a shared partner in the delivery of the Clinical Research Unit (CRU). We are seeking a Senior Data Manager who will be responsible for implementing high quality data management systems and processes across both organisations. Our successful candidate will be employed by TGI and seconded to work within the CRU at UNSW for approximately 3 days per week (0.6FTE). This role will be required to work regularly between the UNSW office (Randwick) and TGI’s office (Barangaroo, CBD). There will be opportunity for limited days to work from home
Digital Analytics Manager - Pacific Northwest National Laboratory, Richland WA USA
The Computing and Information Technology Directorate works to re-imagine how digital technologies can simplify the research experience, enable data-driven insights for decision makers, and accelerate PNNL’s research missions. CIT helps connect staff to systems while enabling a broader research computing ecosystem to improve productivity and provide a sense of community. The Digital Analytics Manager will lead and develop a team of data architects and engineers in a transition that brings together our current data architecture and reporting with contemporary cloud technologies, enabling dynamic data storytelling through visualizations and empowering data scientists to mine for insights that help PNNL make better business decisions.
Associate Director, Data Science - Imaging and AI Research - Merck, Cambridge MA USA
Our Artificial Intelligence Machine Learning (AI/ML) capabilities are critical accelerators to our mission to delivering towards inventing new medicines that save and improve lives. Core to the Data, AI, and Genome Sciences (DAGS) function is an AI/ML-first approach to improving target and biomarker discovery, validation and selection and elucidating complex disease mechanisms. As Associate Principal Data Scientist for Imaging you will build state-of-the-art algorithm for medical imaging datasets such as pathology slides, cell painting, CT, and MRI scans to derive clinically relevant insights for disease biology and target discovery. You will be part of a cross-functional team of computational biologists, bioinformaticians, data scientists, software engineers, and machine learning engineers that strive to identify therapeutic targets.
Principal Scientist, Cryo-EM - Johnson & Johnson, Spring House PA USA
The Discovery Technologies and Molecular Pharmacology group is a dynamic, diverse and critical part of the Discovery Sciences organization in Janssen R&D. We are committed to the discovery and characterization of high-quality chemical leads needed for the generation of small molecule clinical compounds in all five Janssen Therapeutic Areas. This mission requires deep scientific expertise across broad disciplines including chemistry, cellular and molecular pharmacology, enzymology, screening, protein science, and structural biology coupled with an ability to work collaboratively with internal and external partners. Building on a strong legacy of success, we are currently seeking an outstanding and motivated individual to join our team as a Principal Scientist, Cryo-EM.
Product Manager, Bioinformatics Software - Nabsys, Providence RI USA
Reporting to the Director of Product Management and working within the commercial organization, this role collaborates closely with R&D, software engineering, and product development, and strategic partners to manage the Nabsys suite of software products with the goal of enabling the use of our proprietary high-definition electronic genome mapping platform. You will assist and be responsible for bringing novel software products to market and executing on all aspects of our go-to-market strategy that includes secondary data analytics of genome mapping data for structural variant analysis. The successful candidate must have some previous experience in launching software products in related fields and the enthusiasm to work as a member of a multi-disciplinary team in a fast-paced, entrepreneurial environment. This is a phenomenal opportunity for growth as we launch a next generation platform that will make a significant impact on the course of genomic analysis.
Head of Data Science and Bioinformatics - Resilience, San Diego CA USA
Resilience is seeking an outstanding Head of Data Science and Bioinformatics to lead our personalized medicine platform development in our advanced R&D division. This position will lead a team of bioinformaticians and data scientists developing and leveraging multi-omics assays based on next-generation sequencing (NGS), computer vision, and other advanced analytical approaches. This role requires establishing high-level strategies aligned with the overall vision for the platform establishment and rollout.