RCT #178 - Offer services worth paying for. Plus: Effective vendor relationships; Teaching Humanists Changed How This Team Teaches Everyone; Service sludge toolkit; Existing knowledge and collaborations improves agility
Offer Services Researchers Would Be Willing To Pay For
I want to keep talking about this diagram, and point out something that seems logical to the point of inevitability yet which is in my experience pretty controversial for those not operating fee-for-service teams.
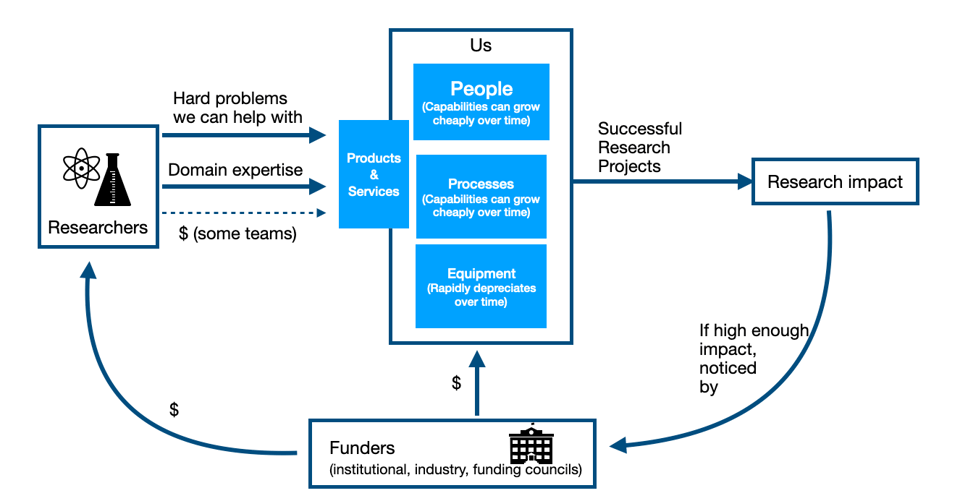
In #176, I focussed on the left hand side of the diagram, that the easiest and most effective way to bring in good work for your group is to talk with your best clients (past and present) and see if there were new or more or larger projects you could do together.
In #177, last issue, I talked about the right hand part of the diagram, the importance of having as high a research impact as possible given your teams constraints.
This issue, I’m going to talk about the path from the left to the right, connecting the researcher, costs, and impact. And in doing so I’m going to share what is by far my least popular technical research support opinion. That is: regardless of the actual funding mechanism of your group, if researchers wouldn’t even in principle be willing to pay the full cost of a service out of their own research grants, then we almost certainly shouldn’t offer that service and should do something else instead.
Oh, that’s not controversial enough? Alright, let’s try this corollary: one example of breaking this rule is that many (many) institutions over-provide batch HPC services at the expense of other services that would be more highly valued.
Researchers know what their research needs
It seems obvious almost to the point of being condescending to point out that researchers know what their research needs.
But the fact is, at the level of which we interact with researchers every day, sometimes we forget.
They quite often don’t know how to do something with computing, or how much effort is involved in getting ABC to work, or which of several kinds of methods to use.
But they very definitely know what they want to accomplish, and what kinds of resources they’re willing to expend to accomplish it.
Just because researchers happily use something for free doesn’t mean they value it
Demand for free things will always be off the charts. If you have a departmental ice cream social on a hot summer’s day, you’re going to go through every bit of ice cream that you buy for your “free ice cream” stand.
High utilization of that ice cream stand is not evidence for the proposition that providing even more free ice cream is the most valuable use to which you could put scarce departmental resources. It’s not even evidence that it’s in the top 10, or should be a priority at all.
People just like free ice cream.
Researchers are resourceful. If something is available for free, and they can find a way to use that free thing to advance some part of their research portfolio, they will absolutely make use of it. That could be computing, support, software development, data analysis, management, grant-writing support, machine-room time, or what have you.
It’s only when you ask them if they’d write the costs into their next grant that you’ll find out how much they actually value it.
Researchers make assessments of Highest Bang for Research Funding Buck every day
For our purposes, research is infinite. Any individual researcher has countless projects they could take on to advance their research programme, and they can and do pivot that programme and switch their research focus when new opportunities arise.
Research funding, and research support funding, on the other hand, is exceedingly finite.
So every researcher who writes grants is constantly assessing what is the best way they could have their desired research impact, and very critically assessing what is the least resource-intensive way to have that impact. And they are VERY willing to shift the projects they tackle if they see higher bang for research funding buck in a new direction.
If researchers wouldn’t support it with their own funds, doing it anyway hurts science
Whatever our teams’ source of funding, it comes from that same, super finite, research funding ecosystem as do the researchers’ grants.
And typically, for better or worse, we have a lot of discretion about the exact kinds of activities we perform and services we provide.
As I said in #177, we have a duty to use these funds to perform tasks where they can have the highest impact. And (#173) by that I don’t mean “do something that has non-zero usefulness”. Institutionally, the trade-off isn’t “is doing this better than putting the money in a pile and setting it on fire”. The trade-off is: “is providing this portfolio of services better than disbanding the team and giving the money that would have funded it back directly to highly productive researchers”.
Because if it isn’t then continued funding of our centre is, objectively, hurting research.
That sounds terrible! But:
Our teams are staffed by world-class experts with high-demand skills who can have outsized impact
Our teams not only should have so much impact that researchers would in principle be willing to write our services into their grants, we can.
We know it’s possible, because there are lots of teams, many in our own institutions, which operate this way.
But besides that: consider how hard it is to hire for our teams. Now consider dozens or hundreds of individual researchers trying to hire for our level of expertise and knowledge, probably looking for only part-time or term-limited work.
We offer extremely in-demand experts an opportunity to have high scientific impact by bouncing between exciting projects if that’s what they prefer, or focusing deeply into one area if they prefer that. It’s still hard to hire, but that’s largely because hiring experts like ours is hard everywhere.
Our teams are professional services firms (#127). We bring expertise to bear on challenging projects. More, it’s our team’s full-time job to do so, and we develop skills and produces and processes and automations and knowledge transfer around exactly that.
If we can’t do our work so much more effectively than individual research groups can that they’d happily write us into funding opportunities, then what exactly are we doing here?
I’m not arguing fee-for-service is the best mechanism for funding services
I want to point out that I’m not arguing that all technical research support should be fee-for-service. Some should (and probably more than currently is), but there are excellent administrative and equity reasons why particular services are best funded in part or in whole by central funding, just as some of our public services are funded through general taxation while others are supported through user fees.
But the rule we measure ourselves against should still be: would providing this service be, in principle, something researchers would be happy to write into their grants.
Yes, there are exceptions to this rule
I’m describing a way of assessing the research impact per unit research funding investment of a particular technical research support intervention - and in fact, thinking of it the way a researcher would.
There are very specific reasons why an institution might choose to invest in some area of research support even when individual researchers would overwhelmingly argue that the money should be spent somewhere else.
Changing behaviours - sometimes the institution sees a need to change behaviours of how research is done in the institution, and is willing to spend money to make that behaviour change. Some examples:
- Funding mandates - sometimes new mandates come down from the heavens, whether it’s cybersecurity or research data management or open access. The institution’s research office is more sensitive to and often aware of these mandates before the bulk of researchers, and wants to nudge individual research group decisions in directions that are going to be compliant with funding changes to avoid foreseeable problems down the line.
- Key interdisciplinary research focuses - especially at small institutions, where individual departments lack a critical mass of potential collaborators, driving interdisciplinary research collaborations becomes crucial. Even at larger institutions, sponsored research offices may see changes coming down the pike and want to build on existing departmental strengths by connecting research across departments where they complement each other. (Think of all the cross-disciplinary infectious disease work that’s gone on in recent years). Since almost all of academia is set up to incentivize people to stay in their disciplinary lanes, it may be useful to develop ways of subsidizing cross-disciplinary work you want to see.
The thing about changing behaviours, though, is that if successful, at some point the behaviours have changed. Institutions can’t and probably shouldn’t commit to (say) subsidizing good research data management practices from now until the heat death of the Universe. Eventually this should be just part of how research is done (and funded), and the necessary costs should be baked into research grants. Similarly, at some point the desired interdepartmental collaborations will be either be (a) strong and not need the same level of external subsidization, or (b) clearly not happening and should be abandoned.
Developing new capabilities - there are lots of kinds of research support that just can’t be purchased piecemeal by individual investigators on their own. Maybe the institution and some key group of researchers has decided (say) that it’s important to develop strong quantum computing and quantum materials depth of expertise, and some large capital expenditure will be a useful way to spend a lot of money even if most researchers at the institution will not directly benefit.
This is related to “changing behaviour” but the reason for it is different — the big (and presumably one-time) capital purchase is just too large for any one researcher or group of researchers to manage, but the institution putting its muscle behind it one way or another can make it possible.
Again, though — if successful, this new capability then exists. If after some initial experience with the new capability it becomes unsustainable, because not enough researchers feel maintaining and sustaining the capability is the best use of their research funding, then why exactly should it be maintained and sustained?
The Bar Is High, and We Can Meet It
Lots of teams do have a lot of their work funded at least partly fee-for-service, in which case everything I’ve said will be pretty obvious.
But for the majority of our teams, those that rely in whole or in part from some source of external subsidy, it is important to view our offerings through the battle-weary perspective of our colleagues that do operate purely fee-for-service offerings, or through the perspective of the researchers who have to decide how their own research funds get spent.
“Is this the best use we can put our funding to” is a broad, fuzzy question. “Would researchers be willing in principle to write the full cost of this into their grants” is bracingly concrete.
And teams that assess their offerings against that very high bar are going to be teams whose teams more consistently get to experience having really high research impact in their work. Our team members, and our researchers, deserve that.
One that note, on to the roundup! A short one this week, since the essay went long.
Managing Teams
Over at Manager, Ph.D., I talked last week about how the imposter syndrome of switching fields is a lot like that of becoming a manager, and how the same approaches can help.
In the roundup, there were articles on:
- How working with LLMs like ChatGPT can help us (and others) practice management communication skills
- Personal development goals and plans
- The importance of psychological safety of speaking up with teams
- The pros and cons of taking on a turnaround
- What if we’re the difficult personality in a particular relationship
Technical Leadership
Three Keys to Building Effective Vendor Relationships - Scott Hanton, Lab Manager
I want to do a whole thing on this at some point - in my experience, most of our teams do not take anything like full of the relationships we have with vendors. [Full disclosure: I work for a vendor now. But then, I’d argue, so do you (#123)].
The vendors we interact with, whether hardware, software, or services, have a range of deep expertise, and visibility into what a lot of other teams are doing. The individuals, especially the technical ones, are typically interacting with university research support teams (compared to all of the other frankly far more profitable customers they could be working with) because they genuinely value research; and all of the individuals know the importance of mutually beneficial long-term relationships.
All that is to say, these relationships and interactions do not need to be purely transactional. The experts on the vendors’ teams are generally quite open to the possibility of other kinds of collaboration than just waiting for you to place an order.
Hanton encourages us to:
- Develop clear communication paths to key contributors from the vendor. That might involve asking around, and asking to meet with others, but once you find them, “[t]his person can be a key hub for information flow between the vendor and the lab. “ He also says, and I agree completely with this, “If you don’t feel like the vendor is listening to you or answering your questions, you would be well served to build a relationship with another vendor.”
- Get support from their experts. “A strong relationship with their technical experts can provide support around troubleshooting, understanding all of the different functions of the equipment and developing new methods or applications”. Yes! And, again: “If you can’t get access to the technical experts at the vendor, it might be time to consider working with someone else.”
- Understand how they can support your lab. “In addition, vendors work with many different customers, and they learn about different aspects of the science from their interactions. Contacts at the vendor can be good sources of ideas, tips, and tutorials for your lab to make progress on your science.”
In general, we should try to forge collaborative relationships with experts in our space wherever we find them - under whatever org in our institutions, and even across sectors. And vendors who aren’t interested in having their technical experts have ongoing conversations with you? Well, there’s lots of other vendors out there.
Product Management and Working with Research Communities
Teaching Technical Topics Effectively: How Teaching Humanists Has Changed How We Teach Everyone - L. Vermeyden and G. Fishbein
This is an interesting paper from last year that I’ve only seen recently, describing how teaching research software & computing concepts to digital humanists made the authors’ training team rethink some aspects of their teaching which improved teaching for everyone.
This was a really interesting read, but hard to summarize - I’ll encourge you to read it if you find the topic interesting.
Sludge Toolkit - New South Wales Governement
I’ve been following the recent rise of digital services in government quite closely; after a lot of very hit-and-miss efforts, there seems to be a growing realization (at least in the anglosphere) that service design requires big picture thinking and attention to detail simultaneously.
In particular, there’s a lot more attention being given to unnecessary friction - or sludge - in the process.
I’ve seen this sort of thinking once or twice in technical research support (e.g. #147, Karamanis’ article “How to redesign a scientific website in three simple steps with limited budget and time”), but not really often enough.
NSW has a “sludge audit” process described, for going through the user-facing pieces of service, identifying unnecessary frictions, and prioritizing their removal.
Effects of prior knowledge and collaborations on R&D performance in times of urgency: the case of COVID-19 vaccine development - Laufs, Melnychuk & Schultz, R&D Management
We investigate how organizations' prior collaboration and existing knowledge not only helped them cope with the crisis but also affected the vaccine's development performance. […]. The results reveal that under urgency, organizations with prior scientific collaborations and technological knowledge exhibit a higher R&D performance. Furthermore, a broad network of diverse collaborators strengthened this relationship, thereby calling for more interdisciplinary R&D activities.
I think this article is interesting, for two reasons.
First, it points out how having a network of existing collaborations (whether that’s with other teams within the institution, or further afield) helps groups be more nimble when they need to be, as there’s a network of pre-existing relationships to draw on.
Second, my own interpretation: our teams not only have very broad technical knowledge, but a particularly broad set of existing collaborations, both with researchers and other support teams (or we should). That makes us a potentially vital hub for our research communities when they need to be agile with some uncertainty.
Either way, I think this a pretty good motivation to not only make a point of broadening and “keeping warm” our internal and external collaborative relationships, but to be explicit that our network of relationships and breadth of expertise are important resources we bring to our institutions.
Random
This is a nice primer on “differentiable programming”, a way of approaching programming to take maximal advantage of all the differentiability and continuous optimization tools there are out there now because of AI.
A chess engine in PostScript, for some reason.
Variable colour fonts, for some reason.
I have a soft spot for the Chapel programming language, although interest seems to have stalled out - anyway, Chapel 2.0 is out.
Lots of good Python tracing/profiling stuff out lately, some related, some not: an article from JetBrains on the new-ish monitoring API, profiling Numba code, trace your Django app inside VSCode.
The most efficient way to tell odd integers from even integers, if you’re committed to doing that with 4 billion if statements.
For actual useful optimizations, designing a SIMD algorithm from scratch.
As servers serving single applications (or infrastructure components) become increasingly a typical use case, we’re going to see more custom OSes like this - a database specific OS, DBOS.
You’ve almost certainly seen this already, but just in case - you can link your ORCID ID to your github account now.
I’m sort of surprised I can’t remember an article on this topic before - what impact does floating point precision have on the Mandelbrot set?
That’s it…
And that’s it for another week. If any of the above was interesting or helpful, feel free to share it wherever you think it’d be useful! And let me know what you thought, or if you have anything you’d like to share about the newsletter or stewarding and leading our teams. Just email me, or reply to this newsletter if you get it in your inbox.
Have a great weekend, and good luck in the coming week with your research computing team,
Jonathan
About This Newsletter
Research computing - the intertwined streams of software development, systems, data management and analysis - is much more than technology. It’s teams, it’s communities, it’s product management - it’s people. It’s also one of the most important ways we can be supporting science, scholarship, and R&D today.
So research computing teams are too important to research to be managed poorly. But no one teaches us how to be effective managers and leaders in academia. We have an advantage, though - working in research collaborations have taught us the advanced management skills, but not the basics.
This newsletter focusses on providing new and experienced research computing and data managers the tools they need to be good managers without the stress, and to help their teams achieve great results and grow their careers.
Jobs Leading Research Computing Teams
This week’s new-listing highlights are below in the email edition; the full listing of 102 jobs is, as ever, available on the job board.
Manager, Quantum Accelerator - University of Calgary, Calgary AB CA
The Quantum City Team in VP Research invites applications for a Manager. This Full-time Fixed Term position is for approximately 35 months (based on length of grant funding), with the possibility of extension. This role is critical in the development of Quantum City's startup program. Working in close collaboration with our partner, the role's focus is to build the quantum and quantum-adjacent startup accelerator program locally in Calgary. The candidate will be responsible for developing the operational processes as well as the coaching and integration of mentors on-site. The role will be instrumental in scouting and selecting the participating global startups but will also support Accelerator leadership in the selection and development of the teams for the international market. There is also a possibility of the role supporting the development of another accelerator location.
Data Science and Bioinformatics Development Lead - UK Animal and Plant Health Agency, New Haw UK
As a senior scientist in the Influenza and avian virology team, you will lead data management activities, driving cutting edge diagnostic responses in a data acquisition and analysis environment. This will involve horizon scanning for novel approaches to both data acquisition, analysis and translation across both national and international for an including both laboratory and computer-based activities. This role will also include supporting strategic direction and delivery for the maintenance of funding streams at APHA including towards ensuring cross-sectorial development of tools to improve diagnostic and research activities.
Head of AI Lab - Healthcare of Ontario Pension Plan, Toronto ON CA
We are actively seeking a visionary and accomplished leader to spearhead our HOOPP AI Lab, a groundbreaking initiative that aims to revolutionize investment management and pension administration through the strategic exploration, evaluation, and implementation of cutting-edge Artificial Intelligence (AI) technologies. Reporting into the Chief Technology Officer (CTO), this role represents a unique opportunity to shape the future of our organization and the pension industry at large.
Program Manager, Research Data Experience - University of New South Wales, Sydney NSW AU
The Program Manager - Research Data Experience is responsible for UNSW's petascale enterprise research data experience (RDE) program initiated in partnership by IT and PVC Research Infrastructure. Data is at the core of research practice and this role will be integral to delivering a sustainable, secure, future-ready, and fit-for-researcher capability.
The program manager will ensure program delivery through all phases including technology selection, procurement, implementation, and operationalisation of the new research data platform(s) and the aligned streams of work covering sensitive data, policy alignement, metadata functions and reporting. This role is critical in ensuring the success of this multi-year and multi-stream program.
Manager, Cryo-Electron Microscopy Facility - Montana State University, Bozeman MT USA
We are looking for a qualified manager to oversee the daily operations of MSU’s Cryo-EM Core Facility on the MSU-Bozeman campus. This individual will assist cryo-TEM users (students, post-docs, researchers) with negative stain and cryogenic sample preparation, as well as data collection on the 120 kV and 200 kV microscopes. They will also have the opportunity to help design and contribute to research projects, and to collaborate with colleagues at MSU, assisting in the design of research projects and subsequent publications. In addition, the person in this position will be responsible for supervising and training facility users and staff, managing operating costs, ensuring a balanced budget and maintaining and troubleshooting equipment.
Bioinformatics Training Lead - Ontario Institute for Cancer Research, Toronto ON CA
As the host of Bioinformatics.ca who is the lead of PCGL’s training working group, the Ontario Institute for Cancer Research (OICR) is seeking a Bioinformatics Training Lead to be responsible for development and delivery of a genomics and bioinformatics training program for PCGL involved groups and members across Canada. The role involves developing relationships with healthcare providers, researchers, and trainees from diverse communities to evaluate their skill gaps in understanding and using human genomic data for research and health benefit. The role will collaborate closely with the Bioinformatics.ca team to co-develop training programs in fundamental concepts like data management and ethical considerations when working with genomic data, as well as work independently to develop training programs specific to PCGL needs. The goal of PCGL training is to generate a workforce capacity in genomics.
Lead Software Architect - SKAO Headquarters, Manchester UK
The outcomes of your work will also feed directly into the SKAO contribution to the EU-funded EVERSE project, that aims to create a framework for research software and code excellence, collaboratively designed and championed by the research communities across five EOSC Science Clusters and national Research Software Expertise Centres, in pursuit of building an European network of Research Software Quality and setting the foundations of a future Virtual Institute for Research Software Excellence. In particular, your area of focus will be the development of a technology watch for tools and services to assess, curate and improve scientific software, code and workflows quality in the Science Clusters.
Agile or SAFe Product Manager, Australian SKA Regional center - The University of Western Australia, Crawley AU
You will take a lead role in driving the SRCNet program towards achieving its strategic vision. You will be responsible for working collaboratively with other members of the SRCNet program lead team to develop and maintain the near and longer-term roadmaps for SRC software development products. This will involve understanding how different products fit together and demonstrating leadership in supporting discussions with stakeholders about overall prioritisation of products and ensuring that the SAFe® teams deliver value to the SRCNet project by specifying and prioritising features and capabilities.
Analytics and Data Manager - Prenuvo, Vancouver BC CA
We are changing healthcare and bringing a slow moving goliath of an industry into the present while blazing a trail into the future of radiology and clinical operations through software, automation and AI. We are looking for an Analytics and Data Manager to join our team!
We want to empower every department and every person to achieve more using data informed decision making. You will play a key role in leveling up our data quality, storage, and accessibility - transforming our ways of operating to enable us to make better decisions and help an increasing number of people around the world.
Lead Genomics Data Scientist - Genomics England, London UK
We are looking to hire a Lead Genomic Data Scientist to join our Bioinformatics Consulting team at Genomics England and lead on a range of cancer genome analysis and interpretation projects in collaboration with and on behalf of our external researchers and industrial partners. The role of the Lead involves a harmonious blend of technical leadership and people management, with a primary focus on enhancing customized cancer genome analysis within our research environment. Drawing upon a robust understanding of biomedical challenges and a commitment to producing high-quality code, the Lead Genomic Data Scientist plays a direct and influential role in crafting solutions and products. These outcomes are specifically designed to cater to the distinct requirements of our researchers and industrial collaborators, thereby contributing significantly to the advancement of our objectives.
Assistant Director of Research, IT - University of Exeter, Exeter UK
The Assistant Director of Research IT is a newly created, critical role. Reporting to the Director of IT Services, you will be responsible for ensuring that the University’s Research IT capability (service and change) is fit for purpose and able to protect, support and enhance the full breadth of research IT services that will be delivered either on-campus, purely digitally or in a blended model. The post offers the opportunity for an individual to deliver an effective future Research IT service, which will facilitate improved, efficient research at Exeter. We need a strategic thinking, scientific or research computing leader, with the ability to engage with senior research stakeholders and who can encourage a progressive, efficient Research IT service.
Lead Machine Learning Engineer, Knowledge Enrichment (Remote) - BenchSci, Remote
We are looking for a Lead Machine Learning Engineer to join our new Knowledge Enrichment team at BenchSci. You will help design and implement ML-based approaches to analyse complex biomedical data such as experimental protocols and results from several heterogeneous sources, including both publicly available data and proprietary internal data, represented in unstructured text and knowledge graphs. The data will be leveraged in order to enrich BenchSci’s knowledge graph through classification, discovery of high value implicit relationships, predicting novel insights/hypotheses. You will collaborate with your team members in applying state of the art ML and graph ML/data science algorithms to this data.
Software Lead, Centre for Population Genomics - Garvan Institute, Sydney NSW or remote AU
The Centre for Population Genomics is a non-profit research organisation operating at the cutting edge of the new field of genomic medicine, at the intersection between biomedicine and data science. The Centre has already generated several of the largest sets of genomic and clinical data ever assembled in Australia, and has assembled a team of software engineers, data scientists, and specialists in community engagement and project management to drive projects focused on generating real-world scientific and clinical impact//. You will lead the software engineering team for the Centre for Population Genomics, which is responsible for designing and implementing a massively scalable genomic analysis platform for providing intuitive access to complex scientific datasets. Your team will include six engineers already recruited, with the opportunity to hire additional members to fill key skills gaps.
Data Science - Leadership - US Department of Homeland Security, various USA
The Department of Homeland Security (DHS) is recruiting professionals to support a range of leadership roles in Data Science, including Data Science Manager, Data Engineer Team Lead, FISMA Support Metric Lead, Data Modeler, Data Security Officer and Operations Research Chief. All positions are in the DHS Cybersecurity Service.
Engineering Manager, Batch Data Infrastructure - OpenAI, San Francisco CA USA
You’ll manage the team that’s behind OpenAI’s batch data infrastructure that powers critical engineering, product, alignment teams that are core to the work we do at OpenAI. The systems we support include our data warehouse, batch compute infrastructure, data orchestration system, data lake, ingestion systems, critical integrations, and more.
Program Manager, Data & AI - Merck, St Louis MI USA
Take part in shaping our AI-focused journey and drive the development and roll-out of Data & AI products and solutions for the Science & Lab Solutions (SLS) division. Become part of a highly skilled team of experts working on scalable use cases and data & AI products. As part of our key initiative centered around AI for SLS, you take a key role in shaping our strategy and defining our roadmap. You work with key business partners to detect opportunities for supporting business decisions, or driving automation and improvement of business processes. You plan and deliver AI-centered projects, translating requirements into structured solutions.
Senior Manager, R&D - IonQ, College Park MD USA
We are looking for a highly capable Manager to help lead our R&D efforts. As a member of the R&D organization, you will lead a cross-functional team whose mission is to lead IonQ on its journey to build the world’s best quantum computers to solve the world’s most complex problems. We are primarily looking for candidates in the College Park, Maryland (DC) area, however we are open to considering candidates in Seattle, Washington or Remote as well. In this role you’ll lead a diverse team of physicists, scientists, optical engineers, mechanical engineers, software engineers, and device fabrication experts to deliver a portfolio of novel technologies that range from qubit technology and ion traps to ultra-high vacuum and cryogenic systems within R&D. You’ll be responsible for helping hire, grow, and coordinate the team to deliver new capabilities that influence and shape generations of our upcoming products.
Chief Informatics Data Science Officer - University of Miami, Miami FL USA
The Chief Informatics Data Science Officer is a role in the University of Miami Health System (UHealth) Information Technology (IT Department) and reports to the UHealth Senior Vice President, Chief Information and Digital Officer. They will play a pivotal role in planning, executing and delivering artificial intelligence, robotic process automation, machine learning, NextGen Medical Education and clinical research related data projects. The bulk of the work will be in machine learning/AI modelling, management and problem analysis, data exploration and preparation, data collection and integration, and turn over to the Chief Data Officer organization for operationalization.
Principal Scientist, O'Donnell Data Science and Research Computing Institute - Southern Methodist University, Dallas TX USA
SMU's O’Donnell Data Science and Research Computing Institute was launched in Fall 2020. We aim to develop research connections between our faculty affiliates and corporations, federal/state/local governmental agencies, and nonprofit organizations. The Principal Scientist of the O'Donnell Data Science and Research Computing Institute (ODSRCI) will help position SMU as a respected leader in data science and high-performance computing (HPC). The ODSRCI was recently created to link and enhance data science across SMU campus, enabled by state-of-the-art HPC infrastructure. With support from the inaugural Director of the ODSRCI, the Principal Scientist will help create an ecosystem of data-related research, high performance computing, education, and engagement. The person in this role will help launch initiatives across campus that strengthen connection between the fields of research in data science, HPC, AI/ML and future technologies. This position will also assist the Director in identifying opportunities for research funds in SMU’s pursuit of R1 status.
Associate Director Research Computing - Tufts University, Somerville MA USA
Reporting to the Director of Research Technology, the Associate Director of Research Computing plays a critical role in advancing the research mission of the University by providing leadership and strategic direction in the development, implementation, and support of research computing infrastructure and services. Their portfolio includes High Performance Computing (HPC), research storage, secure research computing, and instrumentation data capture. This position collaborates closely with faculty, researchers, and other stakeholders to understand their computing needs and ensure that the University's computing resources effectively support cutting-edge research initiatives across various disciplines. Work designation for this position is remote; however, candidate may need to travel to Tufts University 6-8 times per year as needed. Candidates can flex and/or have a compressed schedule per arrangement with manager following successful completion of the trial period.
Research Lead, AI Deployment and Evaluation Lab, Institute for Better Health - Trillium Health Partners, Mississauga ON CA
Trillium Health Partners (THP) is the largest community-based hospital system in Canada. As THP’s research and innovation engine, the Institute for Better Health (IBH) is a core enabler of THP’s mission of a new kind of health care for a healthier community through the application of scientific expertise, innovative thinking and partnerships. Focused on generating cutting-edge science and innovation in health service delivery and population health, IBH leads practical research and innovation that shapes how we engage, design, deliver, and finance health care to solve problems stretching from the bedside to the system. The Institute for Better Health is seeking a Research Lead that will support the AI Deployment and Evaluation Lab ( AIDELab.ca ). The AI Deployment and Evaluation Lab is a global leader in bridging the gap between academic and industrial research and real-world deployment of clinical AI tools. The AIDE Lab is a cross-discipline team composed of clinicians, computer scientists, software engineers, informaticists and health system researchers. It focuses on projects related to clinical AI tool deployment (imaging and EMR-based tools such as pneumonia detection and sepsis prediction), third-party AI evaluation, open data set creation, and opportunistic screening. The AIDE Lab collaborates with leading AI centers across north America and has works presented and published in high impact environments.