Research Computing Teams - Online Manager Training Options and Link Roundup, 14 May 2021
Hi, all:
I got an important question and comment from longtime newsletter reader Laura Kinkead at University of Zurich:
Do you have any recommendations for online management or leadership courses? My manager has given me the go head to take a course or two, and I’m wondering if you have any recommendations for what may be more or less relevant to the research environment. If it would help to be more specific, an area that I’d like to focus on is coaching and giving feedback.
Also, from your tip in a previous newsletter, I attended the Developer First Tech Leadership conference today, and there were a few talks I found really helpful (I found Kevin Goldsmith’s “When, why, and how to stop coding as your day job” to be particularly clarifying!
It continues to be a problem that there are relatively few good offerings for newish managers generally, and approximately none that focus on the particular needs of research computing teams (working with trainees as well as employees, product management, cross-institutional research collaborations, funders…). Here was my response:
Manager-tools virtual effective training: this covers the basics, items you’ve seen in the newsletter - one-on-ones, feedback, coaching, and delegation - with opportunities to practice. It’s relatively reasonably priced ($800 USD, and ~8 hours). There are longer and modestly more expensive in-person trainings as well. This stuff is the fundamentals and translates quite well into research (one reader has had the M-T team give in person training years ago at their organization and the whole research computing organization still uses it). You can go through the manager-tools basics podcasts to get a sense if you’d like the approach.
There are a lot of trainings out there specifically for tech and startups; I continue to think that research computing has a lot in common with early stage startups, with a lot of “will this even work” combined with “will anyone even use this”. Lara Hogan now has a quite modestly priced ($830US) set of at-your-own-pace video courses with a tech flavour here; personally I’d prefer to see some kind of opportunity to practice and get feedback on your skills even at that modest price point, but a lot of people like Hogan’s training (and certainly her writing makes frequent appearances on the newsletter).
On research-specific areas, unfortunately there’s only really one I know about but they’ve restricted their eligibility very narrowly, to postdocs or new group leaders in molecular biology. For those who that fits, the European Molecular Biology Organization, EMBO has some extremely well regarded lab leadership courses (https://lab-management.embo.org/course-overview) - they’re longer, more expensive (€1,800 for the lab leadership course, less for shorter courses like project management).
Upon reflection, I’d add some nonprofit training options, which are good for including topics like managing volunteers (volunteers are a lot like trainees, or volunteer contributors to open source projects), having a clear mission and vision (crucial for any kind of small team with a potentially broad remit) and on funders (a longer post I’ve been meaning to write for a while is that writing a research computing funding proposals is more like going after a nonprofit grant than a science grant). So then I’d add things like Nonprofitready.org.
How about you, RCT readers: what trainings and opportunities would you suggest to Laura and other readers? And what kinds of trainings would you like to see? What topics should be included, and what would the ideal format be - at-your-own-pace online materials, group classes with discussion, one-on-one training? Let me know and I’ll share it next week with other readers (with your permission) - hit reply and it’ll just go to me, or email me at jonathan@researchcomputingteams.org.
For now, on to the roundup!
Managing Teams
Prattfalls: Better Communication - Roy Rapoport
The Art of the Tick Tock - Lara Hogan, Wherewithall
It’s too easy for us as manager to say things to a team member one-on-one or to the team as a group and for it to seemingly not register, or for it to be understood in a different way we intended.
Rapoport has a useful model for those of us in tech of how to think about these misfires. In Rapoport’s model, the purpose of communication is to successfully transmit (or receive) an idea or mental model, and in doing so update someone’s internal state. This is certainly true for important communications where what you’re trying to get something significant across and are willing to put some thought into how to do that. Whether you’re trying to keep someone informed of something, teach them something new, have them look at something in a new way - or to receive those same things from someone else - he distills his approach into four points:
- Communication only exists as a mutation of someone else’s internal state
- Focus entirely on what mutation you’re trying to accomplish
- Be thoughtful about how to accomplish that mutation
- Validate THAT mutation occurred
What’s useful about this is that it reminds you, as ever, of the audience, and that they have a whole lot of complex state in there you don’t even know about. So it’s crucial to validate that the idea got across!
I’d add that another purpose for communication is to build relationships, which is sort of a mutation of state but slowly over time, and so probably doesn’t lend itself to this approach, but that’s easy enough to think about in other ways.
Hogan takes that same deliberate approach in the construction of a communications roll-out model for a new important message to a larger audience. That could be some significant change in focus being communicated within a big organization, or it could be something like a new software project or conference being communicated out to a research community at large.
Having a plan, and rolling out the communications slowly (first one-on-one or one-on-few, then onwards to increasingly broadcast modes of communication) gives you a chance to think critically about the audiences and the strategy - focussing on the mutations you’re trying to accomplish and being thoughtful of it. It also gives you the chance to get feedback on what is being communicated (validating that the mutation is occurring) early on, letting you clear up misunderstandings, gaps, and ambiguities early on in the process.
What if you dread 1:1s with a direct report? - Lara Hogan, LeadDev
You’re not going to look forward to all one-on-ones equally. If there are some you find yourself dreading, that’s an indicator light that something needs looking at in the relationship, on your side or theirs.
After digging into things to understand what’s bothering you about the meetings or relationship, figuring out what you need, and making clear to yourself what is and isn’t your responsibility, Hogan suggests working with your team member to figure out a way forward:
- Learning what they need from you, by asking them what’s worked in the past
- Figure out whether you can provide that
- Decide and communicate what you will and won’t be doing as their manager - setting clear boundaries and expectations.
How Men Can Be More Inclusive Leaders - David G. Smith, W. Brad Johnson, and Lisen Stromberg, HBR
If something - anything! - is truly important at work, then you adopt and communicate it as one of your small number of priorities, learn about it, set targets for it, and have transparency and accountability for those targets. Then you try stuff, listen carefully about why current approaches are and aren’t working, and iteratively make changes to what you’re trying and the targets.
Smith, Johnson, and Stromberg suggest taking that approach in your inclusion efforts, with a focus on what changes when the priority is as important but sensitive as inclusion. Their recommendations:
- Get Comfortable Being Uncomfortable - sometimes you’re going to hear things you don’t want to hear,
- Make It Personal and Visible - to have credibility, and
- Design Transparency and accountability into the efforts
Cool Research Computing Projects
Automated Earth observation using AWS Ground Station Amazon S3 data delivery - Nicholas Ansell and Viktor Pankov, AWS Public Sector Blog
As you’ll see, this is an AWS-heavy issue, for which I apologize, but c’mon, this is pretty cool.
AWS has released an entire automated cloudformation stack for receiving and processing Earth Observation data from the NOAA-20 satellite. And what’s remarkable is how simple it is - relying solely on S3, lambda functions, SNS, CloudWatch events, and of course Ground Station to build the whole pipeline, with some EC2 instances running public NOAA software with some custom code to connect it to the pipeline.
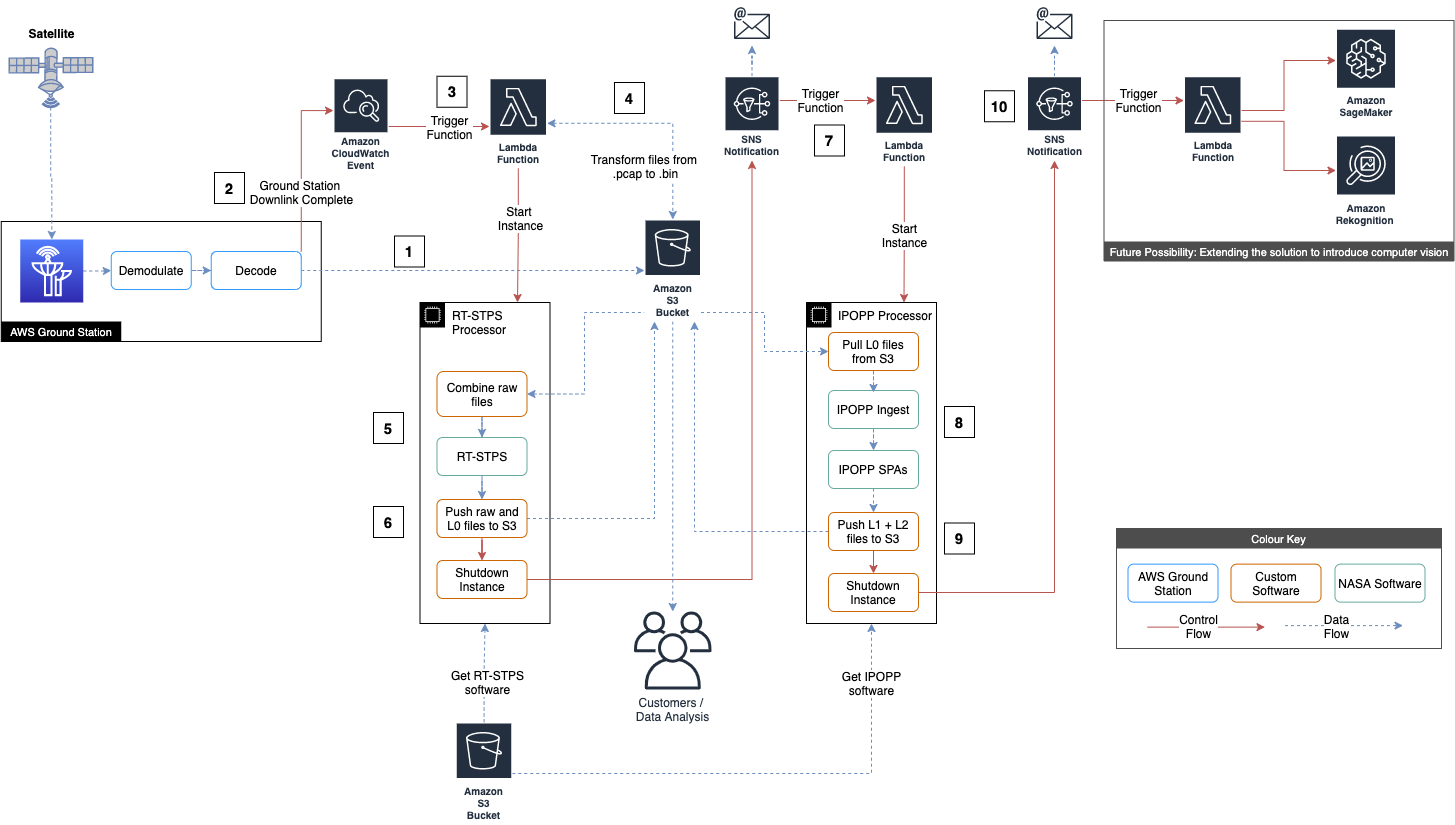
Modern commercial cloud providers have a large number of managed services that make it (comparatively) absurdly easy to build these automated data pipelines by providing a comprehensive set of building blocks that can be assembled. It’s really hard to replicate that functionality on-prem, and absent super-compelling reasons I don’t think research computing teams should even try.
Research Software Development
Dos and Don’ts of Pair Programming - Study Suggests Togetherness and Expediency for Good Sessions - Bruno Couriol, InfoQ
Two Elements of Pair Programming Skill - Franz Zieris, Lutz Prechelt, arXiv:2102.06460
Couriol has a good summary of the work of Zieris and Prechelt on pair programming. That work, which was accepted to ICSE 2021, looks at two features which they claim determines whether pair programming succeeds as a practice: a combination of “togetherness” (whether the pair can successfully establish and maintain a common mental model of what’s going on during the session) “expediency” (having a healthy focus on the task at hand as well as the longer-term goals of knowledge transfer).
A good summary Couriol’s article on three common failure modes:
The study also identified three pair programming anti-patterns: Getting Lost in the Weeds, Losing the Partner, Drowning the Partner. The first antipattern involves spending time investigating irrelevant details and losing track of what is important. Losing the Partner refers to situations in which one participant focuses on the task at hand and does not pay attention to whether the other participant understands what he is doing. The last anti-pattern is somewhat the opposite behavior: one participant explains too much his thoughts and actions, at the expense of expediency.
Babel is used by millions, so why are we running out of money? - Babel Core Team
Another in an ongoing series of reminders that no one has figured out ongoing financial support for open-source software yet. Software isn’t “sustainable”, it’s sustained - or not - by people, who need to make a living. This cri de coeur from the Babel team makes it clear that even with ongoing sponsorship from big companies there’s more maintenance work to be done than dollars with which to fund the work.
Introducing the Software Development Curve - Daniel S. Katz
Why are there forty-seven million pieces of software for writing and running computational pipelines and whereas there are a small number of community codes for running complex multi-physics simulations?
Katz suggests that there’s barriers to entry for some kinds of research software - tools where a large foundation needs to be built from scratch before one has a minimum viable product. In those situations, there is less incentive for other groups to build their own and instead incentive to contribute to other tools.
It won’t surprise long-time readers to learn that I like to think of this in terms of technological readiness models and the path to product maturity; the longer you have to spend on the early phases (proof-of-concept) and before you can put functional prototypes in the hands of friendly users, the fewer systems there are going to be.
This barrier-to-entry model suggests a couple of things:
- Your product will be more likely to become a community code if it’s easy to contribute to and extend, and:
- The more you can push down the requirements for “minimum viable product” the sooner you can get that proto-community-code in the hands of potential contributors, increasing the possibility of addoption
Research Computing Systems
Numerical weather prediction on AWS Graviton2 - Matt Koop and Karthik Raman, AWS HPC Blog
We’ve covered before ARM performance (often the Graviton2 systems on AWS) on traditional HPC codes, such as in #29 when we covered OpenFOAM. In this post by Koop and Raman, they profile the HPC stalwart WRF (Weather Research and Forecasting) code. Running the CONUS 2.5km dataset on a single instance, the Intel-baed C5n.18xlarge instances just barely inch out (by 5%) the Graviton2-based C6gn.16xlarge (and FWIW GCC and ARM compilers seem to make only a very modest difference on the Graviton, whereas Intel handily beats GCC on the Intel node).
For multi-node runs, going out to ~100 nodes, there is similarly very modest performance difference between the two (using the -n instances with the elastic fabric adaptor, which they show is crucial for WRF performance over about 16 instances).
But crucially the ARM nodes are significantly cheaper than the Intel nodes so on price performance ARM wins out by a solid 30% or so depending on where you are aiming for in terms in performance.
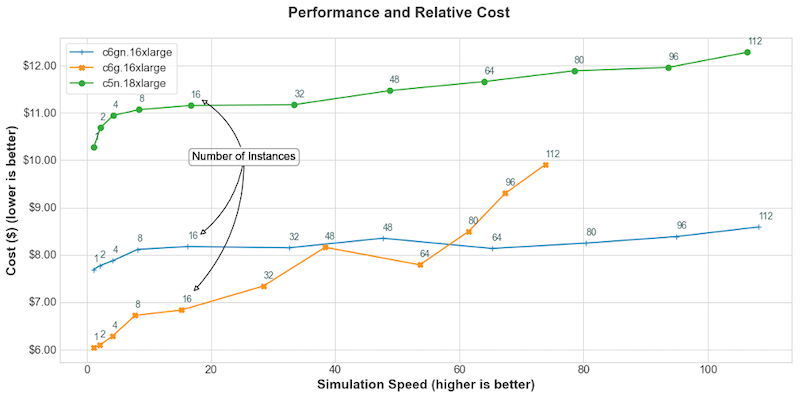
These are all on AWS, of course, but as the new ARM Neoverse cores come out I expect we will see similar comparisons both on performance and price-performance play out in the on-prem datacentre.
Surviving switch failures in cloud datacenters - Rachee Singh et al., Microsoft Azure
Microsoft Does The Math on Azure Datacentre Switch Failures - Timothy Prickett Morgan, The Next Platform
In an ACM SIGCOMM paper that I hope becomes the first of an ongoing series, a team from Microsoft lead by Singh studied a cohort of more than 180,000 switches and looked at their failure rate in their first three months of production, looking at switches from three vendors (unidentified, but Morgan has ideas) and using either proprietary or Microsoft’s preferred SONiC open-source switch OS.
The authors describe their data collection approach, identify root causes - 32% are hardware failures in the switch - and break down failure rates, survival times, and causes by vendor. While it would be good to know which vendor was witch, it’s somewhat heartening to know that there’s only a 2x difference in 3-month failure rates across vendors (~1.5-3%) and it seems like SONiC-run switches modestly but robustly outperform proprietary OSs in failures (but I’d like to see cross-tabs of by vendor to make sure this wasn’t confounded by hardware).
I’m pleasted to see this paper. It would be lovely to see more backblaze-type failure statistics for different kind of data center components, even though I don’t know that the hyperscalers will ever release vendor details.
Running Border Gateway Protocol in large-scale data centers - Alexey Andreyev et al., Facebook Engineering Blog
An interesting datacentre networking week this week! Here Facebook talks about their use and extension of the Border Gateway Protocol (BGP) services for within-datacentre communication of routing, defining backup paths, etc. This is too far out of my wheelhouse to comment on, but if it’s of interest to you there are slides and video of a presentation at USENIX NSDI here.
Emerging Practices and Technologies
The 400 Gb/sec Ethernet Upgrade Cycle Finally Begins - Timothy Prickett Morgan, The Next Platform
After some big migrations from 10Gbps, 100Gbps is now very widespread in the datacentre for those using ethernet - but there’s not much perceived appetite for replacing switches and optics for a factor of two speedbump to 200 Gbps. However, 400 is well underway, especially with hyperscalers and similar big-infrastructure companies. Companies like Arista providing hardware for 400 Gbps switches and optics to provide breakouts to existing 100 Gbps systems to help ease the transition.
One question I keep having is whether or not ethernet becomes fast enough for most HPC applications, with some work on top - look at AWS elastic fabric adaptor having very solid performance up to hundreds of nodes.
Another question raised is whether or not these Ethernet roadmaps continue to provide cost-effective COTS next-gen networking for the rest of us as AWS and perhaps Facebook start building their own ASICs for datacentre work. Without large buyers driving adoption of extremely high speed networking, what happens to the marketplace for such technology?
Reverse debugging at scale - Walter Erquinigo, David Carrillo-Cisneros, Alston Tang, Facebook engineering Blog
Imagine how cool this would be when long-running simulations or data analyses start intermittently failing - loading the crash dump in the debugger and backtracking through the execution stack to see what happened.
We’ve covered reverse debuggers like rr before (#19, #36, #61) but generally keeping the entire execution log for a program, especially a long-running program where it’s most valuable, is prohibitive.
At Facebook the use a ring buffer for the tracing, so you can’t go right back to the start of a program, but you generally don’t need to - as long as the ring buffer is big enough to catch where the problem started you can use it to identify the issue. They also use higher level optimizations, like building a tree of calls so that one can identify branches the code took without going deep into the execution stack.
Calls for Proposals
Papers call: Auto-Tuning for Multicore and GPU (ATMG): Abstracts due 25 May, Papers due 31 May, Symposium online 20-23 Dec
Papers are solicited in following areas of auto-tuning technologies for multicore and GPU/MIC computing, but not limited to:
- Optimized Algorithms for Numerical Libraries
- Automatic Code Generation and Empirical Compilation Hybrid Programming for Threads and Processes
- Communication Optimization
- Mixed Precision and Accuracy Assurance for Numerical Computing
- Power Consumption Optimization
- Fault Tolerance
Microsoft Research PhD Fellowship - Applications due 30 June
Eligibility criteria, application process, and stipend/internship vary by region, but money is available as well as the opportunity to work with research teams at Microsoft (research areas range from algorithms and AI to math, programming languages, quantum computing, information retrieval, security/privacy, and social sciences). Full-time Ph.D. students working in areas relevant to Microsoft research teams are eligible.
Events: Conferences, Training
HPC Leadership Institute - 24-26 May, US Central Time, registration $149-$199 USD
Apparently this workshop is already nearly full, so if it’s of interest to you please register right away:
Topics covered will include procurement considerations, pricing and capital expenditures, operating expenditures, and cost/benefit analysis of adding HPC to a company’s or institution’s R&D portfolio. A broad scope of HPC is covered from department scale clusters to the largest supercomputers, modeling and simulation to non-traditional use cases, and more.
AHUG Hackathon: Cloud Hackathon for Arm-based HPC - 12-16 July, Register your team by 25 June
This looks like a fun and useful event for grad students and postdocs:
Teams will undertake application porting and performance tuning of key HPC applications using virtual clusters on the AWS cloud – powered by their Arm Neoverse-N1 based Graviton2 processor. Using the Spack package manager teams will have to control the installation of their codes – and tune compiler, library and optimization flag choice to ensure a robust and performance tuned installation. Teams must then undertake performance and scalability studies and to compare against other processor architectures. Amassing points for successful builds, tests, performance analysis and tuning – the team with the most points will take the prizes.
Teams will be assigned a mentor and should come with a use case with code and realistic inputs. Top prize is that the winning team (max 4 people) get Apple M1 MacBooks. An AWS HPC Blog post about the event can be found here.
Random
Sure enough, one in four Stack Overflow visitors hit “ctrl-C” or “cmd-C” when visiting a page for more than five minutes. To be clear, I think that’s a success not a problem.
We love bash scripting and embedded databases in this newsletter, so this was a sure thing - Atuin stores your shell history in a SQLite database, has a super-slick tui for viewing history, and lets you search for, e.g., that succesful call to make you made yesterday late afternoon.
SpecBAS.exe lets you revisit your Sinclair BASIC days on windows.
Write hybrid python/bash scripts with zxpy.
ymake does sensible recursive sub-directory makes by building a global dependency graph.
We’ve mentioned before that FIDO2 keys now “just work” with OpenSSH - building on that they now work with git over ssh.
Sign of the times - the Asia SuperComputing conference (ASC) student supercomputer challenge now will use AWS.
An experimental code editor that asks questions to find correctness bugs.
eBPF is being ported to Windows(!). Relatedly, InfoQ has a nice tutorial introduction to eBPF on Linux.
Brendan Gregg goes through debugging poor performance on a single disk drive using iostat and biolatency.
That’s it…
And that’s it for another week. Let me know what you thought, or if you have anything you’d like to share about the newsletter or management. Just email me or reply to this newsletter if you get it in your inbox.
Have a great weekend, and good luck in the coming week with your research computing team,
Jonathan
About This Newsletter
Research computing - the intertwined streams of software development, systems, data management and analysis - is much more than technology. It’s teams, it’s communities, it’s product management - it’s people. It’s also one of the most important ways we can be supporting science, scholarship, and R&D today.
So research computing teams are too important to research to be managed poorly. But no one teaches us how to be effective managers and leaders in academia. We have an advantage, though - working in research collaborations have taught us the advanced management skills, but not the basics.
This newsletter focusses on providing new and experienced research computing and data managers the tools they need to be good managers without the stress, and to help their teams achieve great results and grow their careers.
Jobs Leading Research Computing Teams
This week’s new-listing highlights are below; the full listing of 138 jobs is, as ever, available on the job board.
Technical Program Manager - Big Data - Microsoft, Vancouver BC CA
In this role, you will own a broad charter that impacts various Microsoft product verticals- Teams, Azure Communication Services, Graph, Sharepoint, Workplace Analytics etc., third party Independent Software Vendors, and end-users. The role requires product vision, strategic thinking, customer empathy, technology depth, passion for development of cutting-edge data solutions powering variety of scenarios including billing, usage/quality/analytics reporting, business intelligence, and artificial intelligence initiatives.
Research Projects Manager Quantum Computing (80-100%) - Zurich Instruments, Zurich CH
Ph.D. in physics, mathematics, or computer science close to quantum computing research. Proven track record of successful research proposals and project execution. Experience as project administrator, coordinator, or manager in a complex R&D environment.
High Performance Computing (HPC) Systems Architect I - St Jude’s Children Research Hospital, Memphis TN USA
HPC Systems Architect I provides technical direction of the research information systems architecture portfolio, defines standards for the systems design, collaborates with researchers, data center operations, and other IS staff on system implementation activities, and develops and adopts standard methodologies including resource governance processes to ensure that research information system solutions are delivered to support St. Jude’s vision and strategies. HPC Architect I will lead a team of specialized individuals responsible for the scalability, redundancy, performance, and functionality of all aspects of research computing clusters, servers, and research storage systems including upgrades, customization, and system integration.
Neutron Data and Computing Program Manager - Oak Ridge National Laboratory, Oak Ridge TN USA
We are seeking a senior scientist with expertise in neutron scattering, data systems and analysis, computational research, or related fields to fill the newly created role of Neutron Data and Computing Program Manager in the Neutron Scattering Division (NSD) at Oak Ridge National Laboratory (ORNL). In this role, you will develop creative solutions and coordinate our efforts across the entire data lifecycle for data collected at all 30 neutron scattering beamlines at the Spallation Neutron Source (SNS) and the High Flux Isotope Reactor (HFIR), which are operated as scientific user facilities on behalf of the U.S. Department of Energy
Senior Data Engineer - Reflection X, Anywhere CA
Implement model data flows to support running cutting-edge machine learning techniques on massive amounts of data. Work with product managers and data scientists to turn new features and algorithms into beautiful, battle-tested code. Work with the technologies we use to analyze and identify cyber-security threats for our customers on cloud and containerized environments.
HPC Storage R&D Program/Project Manager I - HPE, Longmont CO USA
Provides support and/or lead teams through the Engineering development process and implementation of HPC Storage products. Projects are typically shorter-term, less complex and more contained with a defined time frame. Programs are typically longer-term, multi-functional, multi-project with complex requirements and effort. Manage activities, resource capability, schedules, budgets, and ensure cross company communications to facilitate product completion on schedule within budget. Work with engineering management to identify and improve process and program efficiencies. Work can involve external parties such as standards bodies, partners, etc.
Research Project Manager 1 - Bioinformatics - BC Cancer, Vancouver BC CA
Establish detailed research project charter, plans and objectives to outline timelines and project deliverables. Execute project plan according to project methodologies, ensures successful and coordinated completion of project components, consult with stakeholders as needed and ensure readiness for project implementation. Track research project progress according to project plan and identified metrics. Monitor and report on the status of projects and major barriers encountered. Make recommendations to Principal Investigator or Leader regarding research projects scope and related changes required to facilitate a successful outcome.
Principal Clinical Data Scientist Lead - PRA Health Sciences, US or CA
Leads end-to-end data review activities performed on a clinical trial. Accountable for achieving clinical data management deliverables
on-time, with high quality and to agreed financial metrics. Responsible for applying advanced analytics to centrally aggregate and
analyze data from disparate sources to identify risks and issues impacting data integrity, patient safety and/or regulatory compliance. Triages and assigns data review findings to the appropriate project team role for follow-up and resolution. Communicates trending analyses and a summary of findings to internal and external stakeholders to support the on-time delivery of data fit for analysis.
Research Project Manager 1 - Bioinformatics - BC Cancer Agency, Vancouver BC CA
Establish detailed research project charter, plans and objectives to outline timelines and project deliverables. Execute project plan according to project methodologies, ensures successful and coordinated completion of project components, consult with stakeholders as needed and ensure readiness for project implementation.
The research focus of this posting is in translational research and clinical trials for gastrointestinal cancers, with a particular focus on colorectal cancer. Analysis led by the successful candidate will support development of future clinical trials.