Research Computing Teams Link Roundup, 28 Aug 2020
Hi!
Our AMA - Ask Managers Anything - last time was “How are you keeping morale up during these challenging times”? We got a couple of answers:
I’ve been doing basically the same communications work I did before but more of it - focussing on the big picture vision (which the team really cares about), lots of listening in one-on-ones and keeping an eye on slack. Early on we tried some team lunches (ordered delivery for everyone) and a couple team happy hours, and they were fine I guess but didn’t seem to move the needle.
and
So, no surprise: one-on-ones, starting always with “How’s things?” which generally gets a non-work answer to start. Team morale has been good, even when challenged by children at home but in school (March - June), remote training […], vacations to nowhere, remote family illnesses, etc. I encouraged the staff to meet on the clock for up to half an hour twice weekly (Tuesdays, Friday) in the afternoons after meetings were over to recreate the office environment of banter without the boss (me) in the room. Others have virtual hangouts as a team WITH the boss and I hear they’re not enjoyed much; I wonder if the presence of the manager has something to do with it. Our staff meeting is fairly casual (but with an agenda and rough internal schedule stated up front), so the staff and I are together then and it’s not “formal” but it is work.
There’s definitely been a ramp-up on the importance of routine communication. I also really like the manager-free virtual hangouts idea, I think that would have a better chance of being successful, maybe I should try that instead. When I was in grad school there was a graduate student seminar series where profs were banned - grad students welcome, even senior postdocs were a little iffy - and it completely changed the dynamics.
We haven’t gotten any new AMA questions for a bit, so unless we get more submissions, this will be the last one for a while:
“For non-embedded teams, what do you do to keep researcher clients / stakeholders up to date on progress of work?”
This is really interesting, there’s been a tonne of conversation about communications within teams in our newly distributed world but less about communications with stakeholders.
My experience is that senior stakeholders are even harder to get “together” all at once for a call than they used to be. I’m trying something new now, putting together some status materials and questions, circulating it, then offering one-on-one discussions on the status with the stakeholders - and only once that’s done bringing people together for short conversations. It’s more of my time (though not that much more – many don’t take me up on the one-on-one) but it seems like it actually works and it makes the “everyone-on-one-call” discussion much more effective.
What have other people been doing? Reply to this email and with your permission I’ll share an anonymized excerpt with all the readers; and feel free to submit a new question.
Now, on to the roundup!
Managing Teams
8 Leadership Myths Every Manager Should Know About - Kate Dagher A bit basic for long time readers, but it may be useful to send new managers (or someone you’re growing towards management), and it’s always useful for us to remind ourselves of the basics.
Of the below, I’m still working on not leading everyone the same way, and bringing others into the spotlight. Even though I know intellectually those are the right approaches I still tend to use my default settings on all my team members when busy, and take on a lot of leadership-y tasks like giving talks myself.
- A position will make me a leader
- If I am not hearing anyone complain, everyone must be happy
- I can lead everyone the same way
- Leaders must be extroverts
- Leaders can’t show vulnerability
- Leaders have all the answers
- Great leaders are always in the spotlight
- Great leaders are born, not made
A simple framework for software engineering management - Andrei Gridnev
This post describes a nice simple approach to structuring thinking about software development management; three categories of responsibilities
- People management - hiring, team member career development, ensuring people are content and engaged with their work
- Delivery leadership - execution on delivering new work or changes
- Technical system ownership - maintaining the technical systems under your stewardship
and then labelling priority areas under each responsibility with
- issues - things that need to be changed
- ok - things going well but should still be monitored
- ideas/aspirations - things that you’d like to try or change in the future
That makes for a simple “dashboard” of things to keep your efforts focussed on in a simple three-by-three chart:
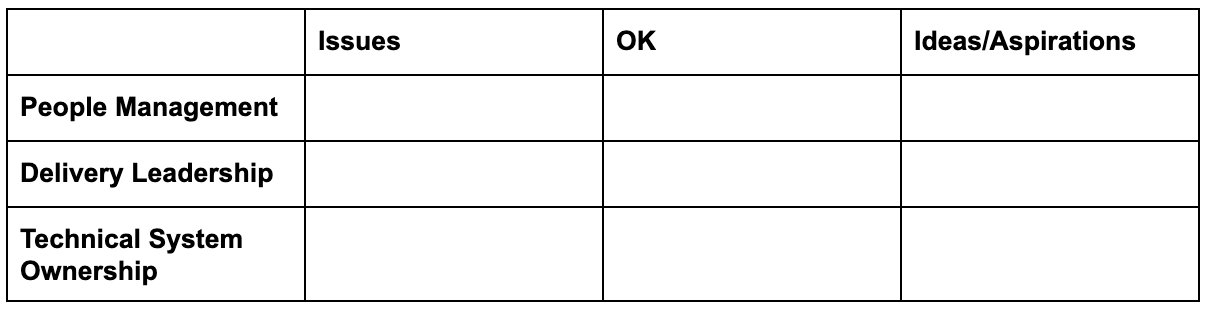
Does anyone have a similar framework for keeping high-level track of things? I may actually try something like this at the start of each week to keep my focus through the week as things get busy.
Debugging engineering velocity and leading high-performing teams - Smruti Patel, LeadDev
This article talks about debugging productivity problems (defined as seen from outside your team) with your software development organization. First off is to identify that the problem exists:
- Are you hearing discontentment or lack of engagement in your regular 1:1s?
- Does the team feel unsure of the impact they are driving?
- Are you seeing unexpected or regretted attrition on your team?
- Is the broader organization questioning the value of your team?
- Is your team feeling stagnant, in terms of growth and recognition?
Second is to make sure the issue is that you’re doing the right things:
- Alignment, between your team and the larger org, or within your team
- Prioritization - is the team prioritizing things correctly?
Finally, if it’s true that you are, to focus on the execution.
- Focus - is the team doing too much? Should you reduce the amount of WIP?
- Are there things that need to be unblocked - whether technical, with people, or their tools?
- Would smaller iterations work better?
How to Foster Psychological Safety in Virtual Meetings - Amy C. Edmondson and Gene Daley, HBR
We’ve talked a few times about the importance of getting everyone to contribute their ideas, including - and especially! - dissenting ideas. Edmondson and Daley point out that some of the tools we’re using all the time now make it especially easy to do that, whether it’s by asking for “hands up” or “yes/no” (green check/red x) indicators, or - and I think this is a really good idea - having polls which aren’t just yes no but, e.g., “on a scale of 1-5”. Polls are nice because they can be anonymous but let everyone chime in. Chat and breakout rooms are also mentioned, as are suggestions as where audio works best and where video works best.
We’re using these tools constantly now anyway, we may as well use some of their features to make sure that everyone gets to make their contribution. Team members will feel more engaged and we will be getting valuable input.
Managing Your Own Career
Expiring vs. Permanent Skills - Morgan Housel
This is a nice way to think about the distinction between the technical skills we started our careers with and those we’re trying to develop as managers. Our technical skills - whether it’s coding or systems work on the computer side, or domain expertise on the science side - degrade over time, and a lot of work has to go in to keep them current. The management skills we’re building - stakeholder engagement, working with team members, large-scale prioritization, planning, and strategy - are more or less permanent. There’s no future where those skills won’t be valuable, and there’s very few jobs we could end up finding ourselves in where they wouldn’t be useful to us and to those around us.
This is also a good reason why it’s important to make sure that those of our team members who are interested in developing those skills have us or someone else available to help coach them in those skills. A vital part of our job as managers and leaders is to grow more managers and leaders.
Product Management and Working with Research Communities
Training Infrastructure as a Service - Helena Rasche, Björn Grüning
This is a paper describing the training infrastructure as a service built by the community supporting Galaxy - a web-based tool for running workflows (bioinformatics workflows, but in principle more general) .
Because it’s not for a particular team, it’s interesting that it’s significantly more automated than I’ve seen most teams have - the instructor registers the course and training materials and approximate number of students, then is given a link that can be shared for students to request accounts. There are ansible scripts for deploying the infrastructure semi-manually before the course.
Are there other teams out there that automate some portion of the deployment of infrastructure for training?
Research Software Development
Introducing Versioned HDF5 - Quansight Labs
HDF5 is a storage API and file format that’s frequently used in large-scale numerical computing, either directly or through other packages like NetCDF or ADIOS. While databases have long had versioning of data available, binary data formats for (e.g.) data analysis haven’t. The team at Quansight and D E Shaw have put together a versioning library atop the very useful h5py, allowing h5py users to transparently add additional versions to existing datasets in place. If that meets a need of yours - I’m thinking more in data analysis than in simulation - it might be worth a look. An upcoming series of blog posts will go into the technical details.
vaexio/vaex - Vaex.io
A technique I’m excited to see starting to come back after fading away in the 90s is out-of-core/external memory algorithms for data analysis. SSDs getting faster while memory bandwidth growth has been sluggish has swung the pendulum back in favour of these techniques, and NVMe is going to push things further. veax is an out-of-core library for data frames (supporting HDF5, as above, and Apache Arrow so far) in Python. The easier these are to use the more widespread the technique will become.
Challenge to scientists: does your ten-year-old code still run? Missing documentation and obsolete environments force participants in the Ten Years Reproducibility Challenge to get creative. - Jeffrey M. Perkel, Nature
Jeffrey Perkel reports on the ten years reproducibility challenge where researchers were asked to rerun software they wrote ten or more years ago.
Changing languages, changing dependencies, and obsolete environments were all a challenge - as was woefully inadequate documentation.
What’s interesting here is that some of the things I might have expected was a dealbreaker - hardware not being available, for instance - was actually often possible to work around through things like emulators.
After ten years, I don’t think it’s a disaster if someone can’t just press “go” and have software work; but it shouldn’t be an impossibility to get working, either. It’s interesting to think about how this same experiment would play out differently ten years from now. On the one hand we have better ways of packaging up dependencies now as with container images; on the other hand frameworks, libraries, and languages have maybe never been evolving faster.
Do you or your team have any stories about rescuing old software that you’re particularly fond of? Email me if you’re willing to share with the rest of the audience.
Emerging Data & Infrastructure Tools
Hands-on WebAssembly - Try the basics - Polina Gurtovaya and Andy Barnov, Evil Martians
Real Time Rendering of Water Caustics - Martin Renou
As the visualization components of tools we build for research computing get increasingly complex, it’s getting more common to push these tasks to the client side for low-latency interactions. These are two nice articles on the implementation of visualization on the client side, one a tutorial using WebAsm-computed fractals as an example, and the other a “how I did it” article using WebGL-computed shaders representing real-time water caustics (those bright lines that appear when light is refracted through shallow waves) over a complex geometry.
The Evil Martians article is a really nice hands-on tutorial on webassembly going from nothing more than a C program to generating fractal curve in the web browser. It’s written for web developers, so it explains a lot that is well known to this audience (“What’s a compiler?”) but it’s a nice tutorial.
The article by Renou walks through why previous directly computed approaches wouldn’t work in complex geometries, and describes how environmental maps and shader mapping are used for this interactive real-time client-based rendering.
Managing AWS ParallelCluster SSH users with OpenLDAP - AWS HPC
AWS ParallelCluster is a nice way to spin up a dynamic compute cluster in AWS, but creating IAM users isn’t a lot of fun, and it doesn’t allow you to make use of existing credentials. This blog post walks through the process of setting up an OpenLDAP server so that you could manage researcher identities there, or connect to remote LDAP services.
AWS HPC Tutorial from PEARC 2020 - Pierre-Yves Aquilanti, Kevin Jorissen, Lee Pang, Tara Madhyastha , Ankit Malhotra, Linda Hedges, and Anh Tran
The AWS HPC team ran a tutorial at PEARC 2020, and their materials are online. Hands-on step by step guides to firing up a ParallelCluster instance, running WRF, and running genomics workflows with NextFlow and AWS Batch.
Events: Conferences, Training
Excalibur SLE Workshop on “Data Assimilation and Uncertainty Quantification” - 24-25 September, 13:00-17:00 BST, Free
From the site,
With the interaction between forward simulations and information-driven methods, techniques for UQ and DA are specifically challenged by the scale of problems that exascale computing will enable. Developing efficient UQ and DA algorithms will also be a major challenge, with close collaborations between RSEs and researchers necessary.
Microsoft Azure Virtual Training Day: Fundamentals - 29-30 Sept, Free
7.5 hours of fundamentals-of-Azure training, split over two days, free of charge, hosted by Azure.
Random
DARPA is getting in on ARM, signing a three year development agreement.
Backblaze has released it’s 2020 Q2 update of hard drive failure rates.
Hadn’t seen this when it came out - mini-conf is a simple but pretty complete setup for virtual conference.
If you or anyone in your team has been curious to learn about functional programming, especially the ML family of languages, there’s a new free online book on OCaml for Scientific Computing.
Really nice, detailed walkthrough of the bundle of techniques used to do multiple NAT traversal by the folks over at tailscale.
Ever been curious about building simple static executables that can be run on Windows, MacOS, and Linux? Welcome to αcτµαlly pδrταblε εxεcµταblε.
That’s it…
And that’s it for another week. Let me know what you thought, or if you have anythingyou’d like to share about the newsletter or management. Just email me or reply to this newsletter if you get it in your inbox.
Have a great weekend, and good luck in the coming week with your research computing team,
Jonathan
Jobs Leading Research Computing Teams
Highlights below; full listing available on the job board.
Sr. Manager, Scientific Computing & HPC - Pfizer, Andover MA USA
The successful candidate will work with the rest of the SciComp engineering and development team to develop, deploy, and support applications that scientists use to run complex simulations, sequence analysis, statistics, and AI/ML models on our large supercomputing environment. This user facing role will provide expertise with managing applications, data, automation, and tuning apps to run on HPC environments. This includes applications like R, Python, Rstudio, databases (Oracle, MongoDB, NoSQL), Matlab, Jupyter Hub, genomic sequencing, image analysis, proteomics, and other scientific computing utilities.
Principal Biostatistical Programmer - Premier Research, Winnipeg MB CA
As a Sr. level Biostatistical Programmer, you’ll be able to produce project related tables, listings, and graphs (TLG), and integrated summaries of efficacy and safety data for regulatory submissions required for delivery to Premier Research Group clients. You’ll take on lead responsibilities for the development and validation of proprietary SAS Software macros, and advanced statistical programming, supporting large complex Biostatistical projects. You’ll also have the opportunity to provide Global Biostatistics with advanced programming knowledge and expertise to lead, develop and support programming efficiencies within Global Biostatistics.
Associate Director Bioinformatics HPC - UT Southwestern Medical Center, Dallas TX US
Certified Network, Linux, Storage or/and Database Expert or Master with five (5) years of HPC experience and leading other leaders in a highly technical environment. Mastery skillset of modern SDLC methods such as GIT, Agile, DevOps, Develops and CI/CD. Knowledge of high-performance networks and parallel file systems.
Deep experience in customer facing roles with a proven record of earning trust as well as effective collaborations across multiple internal organizations and in interactions with HPC users; deep experience in architecting, deploying and management of HPC solutions; deep experience in current technologies such as Singularity/Kubernetes, functional programming languages, pub/sub messaging and RESTful APIs; deep experience in scientific programing; experience deploying HPC solutions to the cloud; experience with system automation and experience with shell/scripting languages.
Senior Data Architect - HDR UK, London UK
You’ll provide excellent data engineering capability across of HDR UK. You’ll design and implement effective data architecture solutions and pipelines, and assess our current data engineering implementation procedures to ensure compliance. As a senior advisor on data design and architecture, you’ll provide business intelligence, prepare reports for management and executive teams and make recommendations for improvement. We need ‘always-on’ access to high quality data, so you’ll be responsible for ensuring that the Innovation Gateway meets the content and functionality requirements of users across HDR UK. Moreover, you’ll own the longer-term data roadmap, defining the datasets that will be added to the Gateway over time. And since you’ll be contributing to the development of recommended standards and minimum datasets for health data in the UK, so you’ll manage and convene colleagues and external stakeholders in areas of strategic importance.